Automate everything with AI, but handle customers yourself. Making customers feel at ease is going to be far more difficult than auto replying with "You are right!", and "So sorry to hear that, let me check that quickly.", and far more valuable.
@championswimmer There seems to be some ground work done on this already, in case it helps : https://t.co/CRMbx4Y65q
Also, happy to chat if you don't crack it in a week, would love to take a stab at it for kicks !
@ponnappa@NirantK All tokens spent aren't going to get outcomes, and combined with the default frugality / scarcity led approach that Indian firms have, I suspect this will help show a visible difference in ROI even if there's competition
@miten@WhatsApp Very cool ! Going to port this to a card computer and run it with a local model so it can run without sending data to Claude, and even when your laptop is off :)
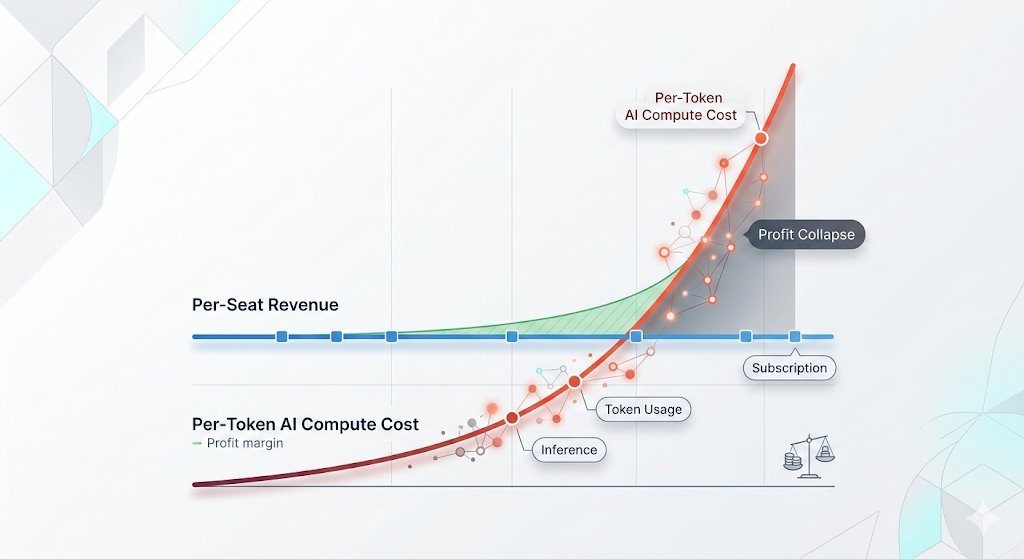
Even if costs were to stay flat or drop, lots of use cases would absolutely make no business sense to do if you had to pay per token.
Pricing tokens is akin to charging as if a token is an outcome, whereas in most cases it is far from it.
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
@Sengupta@HDFC_Bank@billdesk Not been able to log in for months now. Absolutely locked out of the only place where I could view and manage my AutoPay mandates
We are going to see a lot more of this IMO. Such costs seem ok in the moment when you label it as POC / growth stage, but will quickly drag profitability down.
Extremely crucial to have a plan to scale revenue superlinearly with token costs scaling sub-linearly.
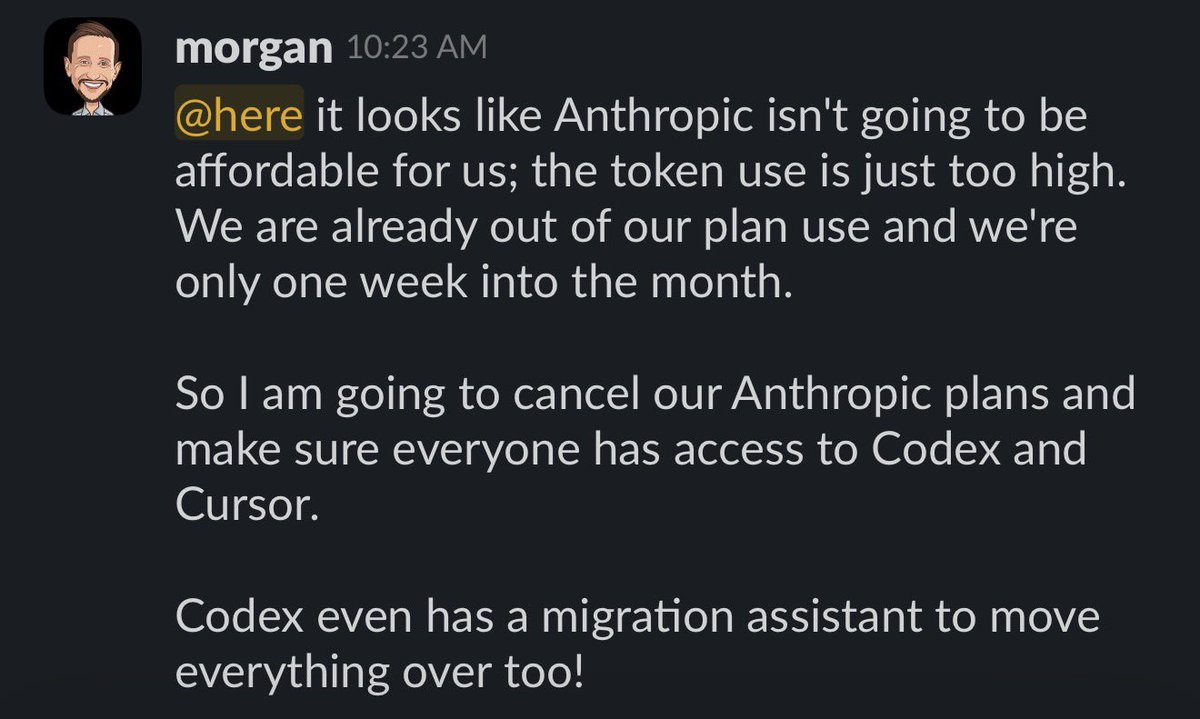
Officially canceling our Anthropic plan, it’s Codex + Cursor for my little 16 person eng team.
Anthropic is great for companies that can spend $2,000/mo and up per engineer, but not affordable for us.
Codex really upped their game recently, and with GPT 5.5, it’s just so good, and so token efficient.
Still using Cursor plenty, my team still looks and reviews a lot of code.
But with Cursor, we’ve never hit a limit, and Composer 2 is pretty awesome for most stuff.
Testing out Droid as well and see some good early results with Droid + GLM 5.1, but still more testing to do before rolling it out to the whole team.
My guess is many more engineering leaders will be sending messages like this. Anthropic makes great stuff but phew, it’s so darn token hungry.
My team loves Codex and Cursor, onward!
@ponnappa Yep. Beyond a point we'll still end up needing "specialists" when you're out of your depth. Seems very similar to existing operating structures, just faster cycles and steeper org pyramids
This helps get outcomes sooner, and you spend "engineering" only when the "business" / "product" outcome is met. No trying to "optimize" until "demo" is a pass. Has helped speed up drastically.
It definitely helps that model output has improved drastically too.
I used to be paranoid about AI code quality. Now, I check the code structure at the start and end but completely skip the middle, just check output.
Hammer the code back in shape (security, performance, extensibility, maintenance, design pattern) once behavior is acceptable.
@Abhi1Nair Yeah saw it real time. Quick playbook for undoing the damage :
- Remove SIM and insert on another device
- Deactivate forwarding (call,voice,data)
- Switch on phone in Airplane mode and check which SMS was received and block / reset
- Factory reset phone
- Reinstall WhatsApp