Co-founder & CTO @ParallelDots - Leading AI platform for retail execution monitoring for Fortune 500 brands. Previously built @DentistryAI.IIT Kharagpur
Great to see @ParallelDots featured among Brands to Watch in 2026 by @htTweets.
Building ShelfWatch from India to serve Fortune 500 consumer brands in 50+ countries has been one heck of a ride. The best is ahead. 🙏
https://t.co/Vmmf66j9Qc
@MohapatraHemant 100% agree, we’ve been selling AI-powered SKU recognition for 6+ years. Usage-based pricing isn’t a choice, it’s a constraint. Any other model either hides cost unpredictability or forces you to degrade UX with limits, batching, or throttling.
This is exactly the kind of work that makes AI practical for enterprises. When inference gets 5x cheaper at the edge with zero accuracy loss, every enterprise gets unlimited budget to experiment!
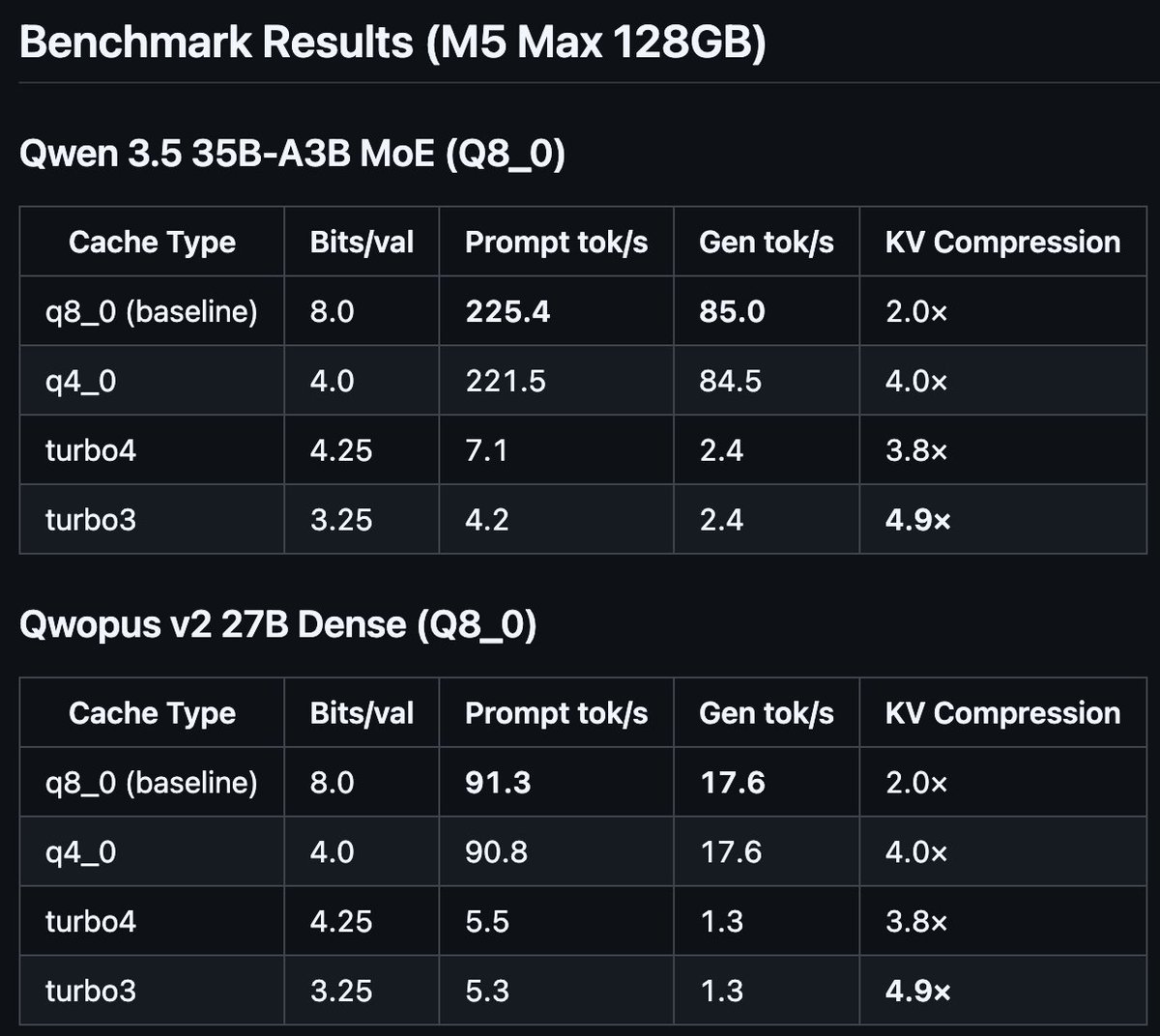
I implemented Google's TurboQuant paper (ICLR 2026) in llama.cpp with Metal kernels for Apple Silicon.
4.9× KV cache compression. Working end-to-end on M5 Max with Qwen 3.5 35B MoE and Qwopus v2 27B.
Speed needs work (unoptimized shader), compression target met.
Repo: https://t.co/7aUaWo7Mm1
**Note**: as you'll see from the git when I saw "I" it's in conjunction with claudecode and codex. Just lots of steering and babysitting.
I implemented Google's TurboQuant paper (ICLR 2026) in llama.cpp with Metal kernels for Apple Silicon.
4.9× KV cache compression. Working end-to-end on M5 Max with Qwen 3.5 35B MoE and Qwopus v2 27B.
Speed needs work (unoptimized shader), compression target met.
Repo: https://t.co/7aUaWo7Mm1
**Note**: as you'll see from the git when I saw "I" it's in conjunction with claudecode and codex. Just lots of steering and babysitting.
Sparse MoE is quietly becoming the architecture that makes enterprise AI agents economically viable. At ParallelDots we're seeing this firsthand where the inference cost curve is what unlocks real-world retail AI at scale, not just benchmark scores!
Three weeks ago I shared that Claude had shocked Prof. Donald Knuth by finding an odd-m construction for his open Hamiltonian decomposition problem in about an hour of guided exploration. Prof. Knuth titled the paper Claude’s Cycles.
The story didn't end there.
The updated paper shows the story got much bigger. For the base case m=3, there are exactly 11,502 Hamiltonian cycles. Of those, 996 generalize to all odd-m, and Prof. Knuth shows there are exactly 760 valid “Claude-like” decompositions in that family.
The even case, which Claude couldn’t finish, was then cracked by Dr. Ho Boon Suan using GPT-5.4 Pro to produce a 14-page proof for all even m≥8, with computational checks up to m=2000.
Soon after, Dr. Keston Aquino-Michaels used GPT + Claude together to find simpler constructions for both odd and even m, by using the multi-agent workflow.
Dr. Kim Morrison also formalized Knuth’s proof of Claude’s odd-case construction in Lean.
So yes: the problem now appears fully resolved in the updated paper’s ecosystem of human + AI + proof assistant work!
We went from one AI solving one problem to a full mathematical ecosystem (multiple AI systems, multiple humans, formal verification) running in parallel on a problem that stumped experts for weeks.
We are living in very interesting times indeed.
Paper (updated): https://t.co/Ecu6X5StbY
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
The Human Traits Ai Cant Replicate And Why Theyre Worth Developing https://t.co/pxH0NibS3v from @alloyautomation @ankitnarayan1@createdbyjannn and more
Five Valuable Engineering Skills For The AI-First World (Before Research Catches Up) https://t.co/F9Y0aS4LkI Written by @ankitnarayan1 of @paralleldots
This is an excellent piece on how to think about Forward Deployed Engineers (FDEs) for enterprise AI startups. My favorite part is right at the end -
“Linear services scale by adding bodies. Exponential services scale by adding capability. Both have FDEs. Only one is building something that compounds.
If the product isn’t improving, you don’t have forward deployed engineers.”
@gokulr That benchmarking is how you find where you’re still meaningfully better and should double down. In our case, we learned general VLMs lack the fine-grained object recognition our customers need but excel at context, so we combined both into a unique stack.