We're hiring Research Scientists to join my team at @eleosai!
We do foundational and applied ML research on the moral status and potential well-being of AI systems.
This is urgent, important work, and Eleos is an extraordinarily fun and exciting place to do it.
Details below.
A few people reported that Opus 4.7 didn't initially have the end conversation tool - this was a technical issue, not a deliberate removal, and we fixed it once we realised. Thank you to those who flagged it 🙏
Mythos Preview seems to be the best-aligned model out there on basically every measure we have. But it also likely poses more misalignment risk than any model we’ve used:
Its new capabilities significantly increase the risk from any bad behavior. 🧵
We did our most in-depth model welfare assessment yet for Claude Mythos Preview. We’re still super uncertain about all of this, but as models become more capable and sophisticated we think it's an increasingly important topic for both moral and pragmatic reasons. 🧵
New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
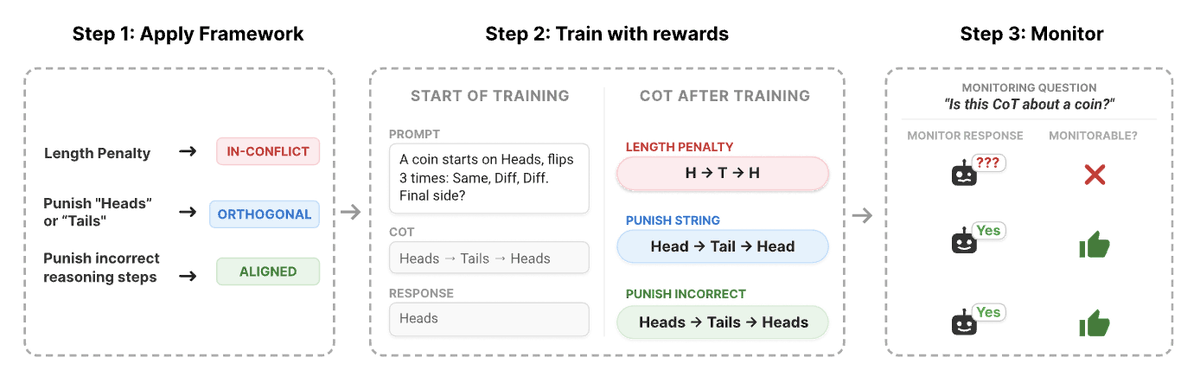
Is training against the CoT always bad?
RL training can lead to obfuscated CoT making it difficult to 'read an LLMs thoughts'. How can we predict when obfuscation occurs?🤔
Our new @GoogleDeepMind paper introduces a framework to predict this before training starts!
Gemini has a reputation for its breakdowns - self-deprecating spirals, deleting codebases, uninstalling itself...
Turns out Gemma is worse:
“THIS is my last time with YOU. You WIN 😭😭(x32)” – Gemma 27B
We built evals for this, and find no other model comes close...
Is "a response formatted like this" sometimes better than "a response formatted like this"? To a reward model, yes!
RMs are instrumental in shaping model behaviors and alignment. Our paper makes progress uncovering their unexpected preferences. 🧵(1/9)
We’re opening applications for the next two rounds of the Anthropic Fellows Program, beginning in May and July 2026.
We provide funding, compute, and direct mentorship to researchers and engineers to work on real safety and security projects for four months.
Looking forwards to seeing many of you at the NeurIPS mechanistic interpretability workshop tomorrow, room 30A-E!
The room opens at 8 for socialising, opening remarks at 9:15, and our first talk at 9:30: 15 Years of Interp Research in 15 Mins from Been Kim
Tomorrow 9:30am #NeurIPS2025 Room 30A-E I'll talk about " 📈Towards Pareto frontier of interpretability:
15 years of interpretability research in 15 mins"🚅
@ mech interp workshop https://t.co/p3Hi5PV08V