Releasing mlsweep, a sweep scheduler and visualizer for distributed ML training. It aims to make launching runs across groups GPUs frictionless and achieve near feature-parity with wandb. But you can use it with whatever frameworks or loggers you like, wandb included.
@rosinality I think that stress about high versus low rank is in some sense unfounded, seeing as many shifting low rank updates constitute a high rank update. Then again this must also be validated, RL tends to just learn small subnetworks and does not do this at all. It's not like ReLoRA.
@Norapom04 Blue line is a lot better than some others. Anything going south is worse. And some stations are much better than others. On the train you should be good. People do get mugged at blue stations sometimes. I haven't gotten in any fights, it's mostly been vagrants calling me slurs.
I love how any the normalized length of any sufficiently large vector of normally distributed random variables converges to 1 by the law of large numbers. This lets you clip ES gradient projections for cheaper because you don't have to do a reduction to compute the length.
@cs_serdar It's because I'm working on Zeroth Order Optimization (Evolution Strategies, SPSA, MeZO, etc) where there are no gradients and so no gradient summing or accumulation at all, so it's way easier and kinda just falls out of the math that it's possible to do at near zero cost.
Suppose in deep learning that we didn't do gradient accumulation/batching and we had full knowledge of what components of the grad came from what item. In that case would it make sense to apply grad clipping per-item?
One preserves information, the other bounds step magnitude.
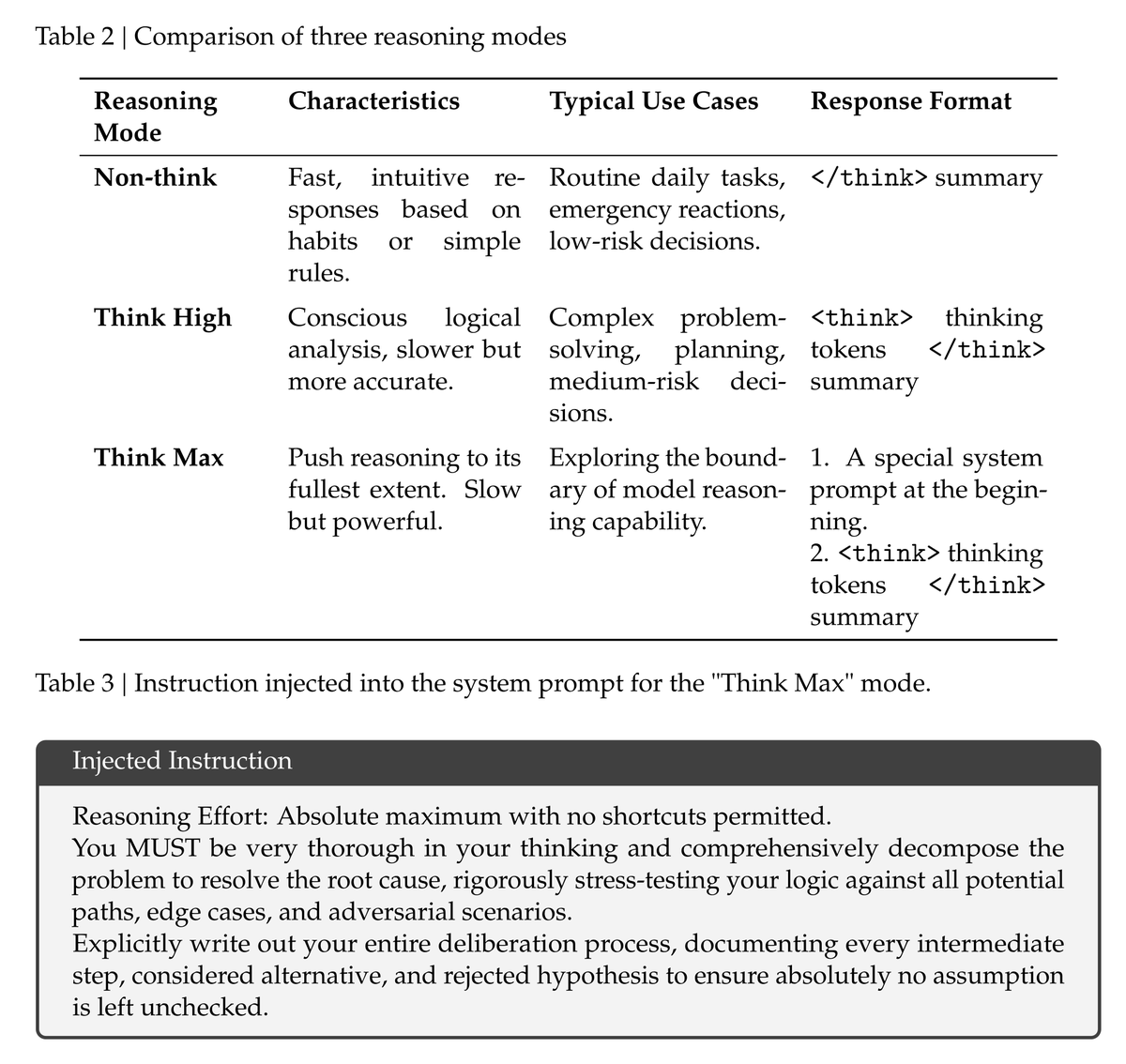
PSA that despite the Deepseek V4 paper clearly stating that you must set a specific system prompt, @opencode does not set this prompt and so you cannot use "max" mode in opencode, even if you think you have selected max mode.
@stochasticchasm@opencode If so I can find no evidence of that being the case. And from my experimentation, no, it behaves way differently. You ask it a question and it pretty much fills up the whole context every time, you walk away and come back in 20 minutes. But that's not what it does in opencode.
@cs_serdar I think I understand better now. You are throwing some sort of signal away to avoid falling off the loss landscape. But is it better to throw the bad data point away because it's bad, or if it's not, should you be throwing data out uniformly with a full clip? That's my intuition.
I think overall I like it, although the tone could probably use some work.
Sometimes one of the strawmen makes you think "oh shit oh fuck you're so right I need to rethink everything thank you Claude what could I ever do without you" in a way that absolutely was not true of previous models.
I expect they'll fix the tone in the next release, but I'm glad we have 4.8. It instantly started finding bugs, and I think it's going to massively help code maintainability going forward.
I understand not wanting to do SFT. There are real gains from not doing it. But the choice to pretrain without pretraining on things that look like rollouts is confusing to me. There is a big distribution mismatch there, as big as base model vs instruction tune. IMO it should be a part of midtraining. There are ways to produce data that looks like a rollout without actually sampling a rollout.
Many choices here are only possible when your objective is not an immediate or short-term performance. Pretraining without synthetic data, posttraining without SFT with data from other LLMs. (And other good choices like scaling ladder with NLL instead of benchmark scores).
I've been thinking about this, yeah. I think you're right. You're throwing away almost whole batches because some data in it happened to be OOD.
Although maybe that's not the right framing? I think bounding step magnitude probably is independently useful, but in a world where you have clean batches it shouldn't be a problem.
Anyway we don't have clean data. Is per-item clipping enough for stabilization? Or is bounding step magnitude what you want to do?
Wondering how other people think about it, because the clankers have failed me. I'm in a paradigm where I have the ability to do this basically for free.
I will hand it to Anthropic, the model released, I switched to it, and it instantly found a bug. It also instantly started annoyed me. An adjustment for sure.
300k tokens trying to teach 4.8 how Bend's termination checker works 🫠 maybe not so bright, but somehow a pleasure to talk to and definitely my favorite model of all time