Así nació Curtai.
Generas vídeos para todos tus clientes — guión, voz en español, subtítulos y hashtags. En minutos. Sin grabar. Sin editar.
Waitlist abierta 👉 https://t.co/9vwK4SchVt
¿Cuántas horas pierdes cada semana creando contenido para cuentas de clientes que no son tuyas?
Llevo más de 50 días publicando un vídeo de psicología en TikTok.
No he grabado ninguno.
Pero mientras lo hacía, no dejaba de pensar en otra persona.
El freelance o social media manager que gestiona 10 o 15 cuentas de clientes. El que sabe que el vídeo corto funciona pero no tiene tiempo para producirlo cada día para todos.
❌ El pueblo ha hablado: los aficionados hispanohablantes suspenden la Fórmula 1 de 2026 con un 3.15 de media. Ningún país participante aprueba estas "nuevas" carreras.
Abro hilo con mis conclusiones de la encuesta completada por 41.450 aficionados de la categoría reina.
Es hora de escuchar (de verdad) al aficionado de la Fórmula 1.
He preparado este formulario para dar voz a vuestra opinión sobre el reglamento de 2026 y la situación actual de la categoría. Es largo, tened paciencia.
Podéis completarlo aquí: https://t.co/LJl6far7Vx
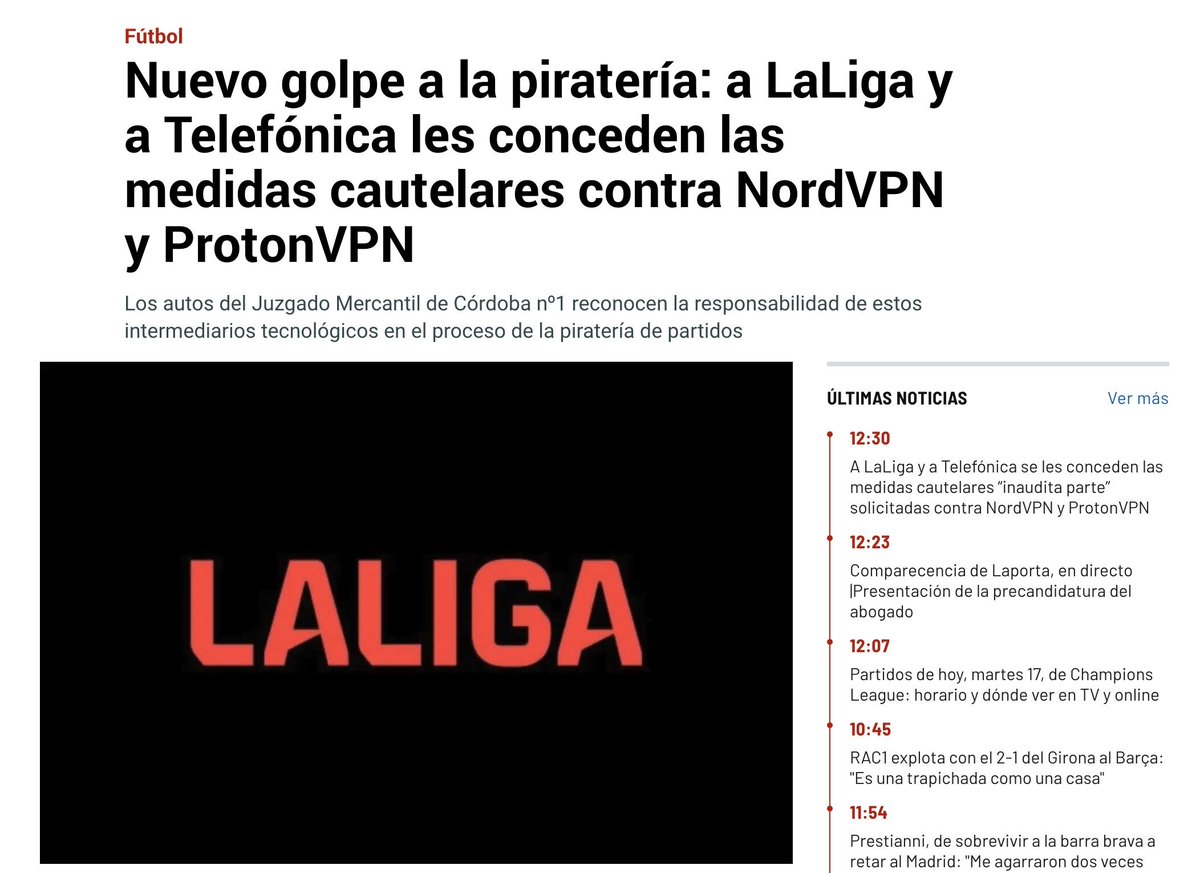
Esto no es una victoria contra la piratería. Es una derrota para la neutralidad de Internet y la privacidad.
Que LaLiga y Telefónica consigan que se obligue a NordVPN y ProtonVPN a bloquear IPs sin garantías es un precedente que debería preocuparnos a todos, incluso aunque no veas fútbol.
Una VPN es una herramienta neutral. Igual que un navegador, una conexión a Internet o un cuchillo.
Como no soy capaz de detener al delincuente, decido retirar los cuchillos de los supermercados.
Y lo peor es que gente que, como yo, no consumimos fútbol de ninguna manera nos vemos igualmente afectados por este tipo de decisiones.
El problema real no es técnico. La piratería no existe porque haya VPNs, Cloudflare o Internet. Existe porque el producto es caro, está fragmentado y es difícil de consumir legalmente.
Si alguien no paga ahora, no pagará mañana. Un pirata no deja de serlo por castigo, deja de serlo cuando el producto y el modelo cambian. Spotify, Netflix y demás lo demostraron.
Y luego está el papel de cierto periodismo deportivo. Medios como Marca actúan aquí como simples altavoces de comunicados corporativos, sin análisis técnico, sin contexto legal y sin el más mínimo escrúpulo sobre las consecuencias reales de lo que están amplificando.
No informan, legitiman. Y cuando renuncias a cuestionar el poder para limitarte a reproducir su relato, dejas de hacer periodismo y pasas a formar parte del problema.
5/ The entire project was built using Claude Code as a coding partner. From the bot logic to debugging Docker networking issues during deployment.
6/ Running costs: ~$7/month for the VPS. No API fees since the model runs locally. Data stays on my server.
I've been building a personal AI assistant as a side project. It runs on my own VPS, no paid APIs involved.
Quick thread on what it does and how it's set up 🧵
3/ It also has a RAG memory system, so it remembers context from past conversations.
4/ The stack:
→ Python + Docker
→ Ollama (Llama 3.1 8B) on a Hetzner VPS — 4 vCPU, 8GB RAM
→ Tailscale for secure remote access
→ Telegram as the interface
Hostia... esto es muy fuerte.... lo que me ha reconocido Claude: "Buena pregunta, Juan. Déjame buscar si hay algo documentado sobre cambios de comportamiento en 4.6.Juan, esta es una pregunta muy buena y voy a ser directo contigo.
Sí, hay un patrón real aquí, y no es exclusivo de 4.6. Pero déjame desglosar lo que probablemente está pasando:
El problema de fondo: cómo se entrena y evalúa el modelo. Los benchmarks principales de coding (SWE-bench, Terminal-Bench) miden exactamente eso: resolver issues. El modelo recibe un bug report o feature request, produce un patch, y se evalúa si los tests pasan. Esto crea un sesgo de optimización hacia "producir el diff mínimo que resuelve el problema inmediato" en lugar de "producir la solución correcta desde una perspectiva de ingeniería". Las versiones anteriores de Claude tomaban atajos frecuentemente, y los equipos tenían que diseñar arquitecturas específicamente para contrarrestar esa pereza. Opus 4.6 mejora en exhaustividad, pero el sesgo subyacente sigue ahí.
Lo que ves en Claude Code específicamente es una combinación de factores:
Primero, aversión al riesgo acumulada. Cuando Claude Code lleva varias iteraciones en una sesión y ha tocado múltiples archivos, empieza a "tener miedo" de romper lo que ya funciona. En lugar de refactorizar correctamente, parchea. Cada parche hace el siguiente cambio más arriesgado, y el modelo responde siendo aún más conservador. Es un círculo vicioso.
Segundo, degradación por contexto largo. El rendimiento se degrada cuando el contexto llega al 30% de capacidad, no al 100%. A medida que la sesión crece, la calidad de las decisiones arquitectónicas baja.
Tercero, el "ticket mindset" del training. El modelo ha sido optimizado para resolver la tarea inmediata que le pides, no para mantener la salud global del código. Cuando le dices "arregla X", su instinto entrenado es producir el cambio mínimo que arregla X, no "arregla X y de paso limpia el desastre que causamos hace tres iteraciones".
Lo que puedes hacer en la práctica:
Usa /compact o /clear entre tareas significativas para evitar la degradación de contexto. Cuando detectes que está parcheando sobre parches, para la sesión, haz commit de lo que tengas, abre una sesión nueva y dile explícitamente algo como: "Revisa este módulo. Hay deuda técnica acumulada de iteraciones anteriores. Refactoriza correctamente antes de seguir añadiendo funcionalidad. No me importa si el diff es grande."
También puedes añadir en tu https://t.co/GqN5ukzoGX una regla como:
"Prefiere refactorizar código problemático antes de añadir funcionalidad encima. Si detectas que estás parcheando sobre código frágil, señálalo y propón un refactor antes de continuar."
Eso contrarresta directamente el sesgo de "cerrar ticket rápido".
Respuesta corta a tu pregunta: No es un cambio deliberado de 4.6 para priorizar velocidad sobre calidad. Es un sesgo estructural de cómo se entrenan y evalúan todos los modelos de coding actualmente — y que se manifiesta más cuando las sesiones se alargan y la complejidad se acumula."
🤯 Mientras todos hablan de "regresión" porque Apple vuelve al aluminio en los iPhone 17 Pro, la realidad es que acabamos de presenciar una de las decisiones de ingeniería más brillantes de la última década. Y casi nadie lo entiende.
🔥 Vamos a los datos duros: el aluminio serie 7000 aeroespacial tiene una conductividad térmica de 237 W/mK (watts por metro por Kelvin, que mide cuánto calor puede transferir un material) frente a los míseros 22 W/mK del titanio. En cristiano: el aluminio es 10.8 veces mejor evacuando el calor que genera tu procesador. No son números de marketing, es física pura.
👨🏻💻 La aleación que Apple emplea de Al-Zn-Mg-Cu (aluminio-zinc-magnesio-cobre) con 7-12% de zinc y 2-3% de magnesio no es aluminio común: es la misma aleación que usan en aviones. Y no solo es 40% más ligera que el titanio, sino que permite algo que el titanio hacía imposible por su pésima conductividad: la integración directa con un sistema de cámara de vapor soldado al chasis.
🌡️ Aquí viene lo bestial: esa cámara de vapor usa agua desionizada al 99.99% de pureza (solo 0.01% de impurezas que podrían romper el ciclo térmico) como fluido de trabajo. El sistema crea un ciclo de evaporación-condensación que alcanza una conductividad térmica efectiva de hasta 10.000 W/m-K. Para que compares: es 25 veces superior al cobre sólido.
⚡ ¿Capacidad de disipación? Más de 100 W/cm² (watts por centímetro cuadrado). Una plancha doméstica genera 10-15 W/cm². Estamos hablando de otro nivel de gestión térmica.
🎯 El resultado real: el A19 Pro mantiene un rendimiento sostenido 40% superior sin throttling térmico. La estructura de mecha de polvo de cobre sinterizado garantiza que el líquido regrese por capilaridad, distribuyendo el calor uniformemente por todo el chasis. Es un sistema autocontenido perfecto.
🫵🏻 Y así es como nos gusta explicar las cosas: con datos, con física, con las unidades claras y la verdad por delante. Porque si no entiendes los datos y el por qué de las innovaciones, podrías perderte en el marketing y no entender por qué se toman las decisiones que realmente importan.
---------
Somos Apple Coding Academy. Formamos a empresas y desarrolladores desde la especialización para ser más competitivos y entendiendo el código. Si te gusta nuestro contenido, ve a nuestro perfil, dale a la 🔔 y síguenos. ☝🏼
¡Microsoft lo cambia todo! GitHub Copilot evoluciona.
Agente de código autónomo que trabaja para ti.
✓ Asígnale una "issue" a Copilot
✓ Copilot generará una PR con la solución
✓ Accesible desde GitHub y Visual Studio Code
¡Mira cómo funciona! ↓
The Model Context Protocol (MCP) is not just "another API lookalike." If you think, "Bro, these two ideas are the same," it means you still don't get it.
Let's start with a traditional API:
An API exposes its functionality using a set of fixed and predefined endpoints. For example, /products, /orders, /invoices.
If you want to add new capabilities to an API, you must create a new endpoint or modify an existing one. Any client that requires this new capability will also need modifications to accommodate the changes.
That issue alone is a colossal nightmare, but there's more.
Let's say you need to change the number of parameters required for one endpoint. You can't make this change without breaking every client that uses your API! This problem brought us "versioning" in APIs, and anyone who's built one knows how painful this is to maintain.
Documentation is another issue. If you are building a client to consume an API, you need to find its documentation, which is separate from the API itself (and sometimes nonexistent.)
MCP works very differently:
First, an MCP server will expose its capabilities as "tools" with semantic descriptions. This is important! Every tool is self-describing and includes information about what the tool does, the meaning of each parameter, expected outputs, and constraints and limitations.
You don't need separate documentation because the interface itself is that documentation!
One of my favorite parts is when you need to make changes:
Let's say you change the number of parameters required by one of the tools in your server. Contrary to the API world, with MCP, you won't break any clients using your server. They will adapt dynamically to the changes!
If you add a new tool, you don't need to modify the clients either. They will discover the tool automatically and start using it when appropriate!
But this is just the beginning of the fun:
You can set your tools so they are available based on context. For example, an MCP server can expose a tool to send messages only to those clients who have logged in first.
There's a ton more, but I don't think I need to keep beating this dead horse.
AI + MCP > AI + API
*micdrop*