The GOAT AI Builder Grants Program is seeing serious demand.
We’ve already received many strong applications for base grants, with a further $1M being allocated to the strongest teams building agent-based products with real economic utility.
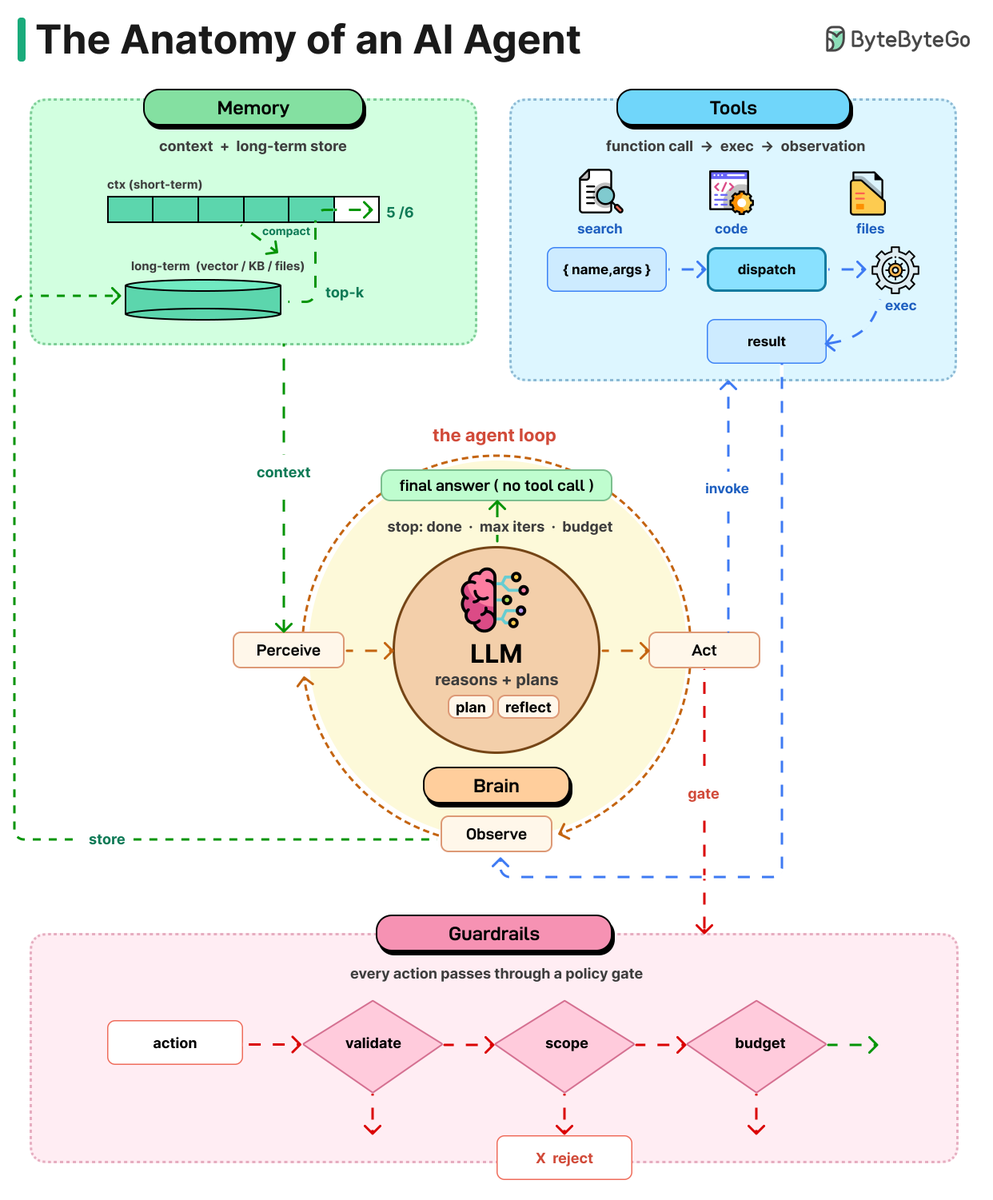
An AI agent can be thought of as a simple While-loop.
It uses an LLM to select an action, executes that action, evaluates the result, and repeats the process until the task is complete. Let’s take a closer look at each of these components:
Brain: The LLM is the core. It reads the situation, thinks, and decides what to do next. The big shift from chatbot to agent: the model isn't writing text anymore, it's making choices.
Planning: Hard tasks need more than one step. Agents break them down using methods like Chain of Thought (think step by step), Tree of Thoughts (try options, pick the best), or
Reflexion (learn from mistakes and retry). Planning turns a fuzzy goal into clear actions.
Tools: An LLM without tools is a brain in a jar. Tools are functions the model can call, like web search, code execution, APIs, files, or browsers (often using the MCP standard). The model requests a tool, the system runs it, and the result comes back.
Memory: Without memory, every turn starts from zero. Short-term memory is the context window. Long-term memory lives in vector stores, files, and knowledge bases. When the window fills up, agents summarize old turns and carry the summary forward.
Loop: All four pieces work together in a cycle. The agent looks at the current state, decides what to do, uses a tool, sees the result, and repeats. It keeps going until it gives a final answer.
Guardrails: Not strictly anatomy, but important. Sandboxing, human checks, token limits, output validation, and scope limits keep autonomy from turning into expensive chaos. The more autonomy you give, the more these matter.
Over to you: when you build an agent, which of these five takes the most work to get right?
How to set up Claude Code so it runs like a full dev team:
5 folders. That's the entire system.
1. CLAUDE.md → Memory.
Your repo's constitution. Naming rules, structure, expectations. One global file for all projects, one local file per repo.
2. skills/ → Knowledge.
Reusable workflows Claude auto-invokes by matching the task description. No slash commands. It just knows.
3. hooks/ → Guardrails.
Shell scripts that run before and after every tool call. Block dangerous commands. Auto-lint on save. Ping Slack on deploy. Deterministic. Not AI.
4. subagents/ → Delegation.
Isolated agents with their own context window. A code reviewer that only sees the diff. A test runner with custom permissions. Keeps your main session clean.
5.plugins/ → Distribution.
Bundle the whole system into one install. Every teammate gets the same skills, same hooks, same agents. Aligned from day one.
This is the Agent Development Kit. Five layers, one stack.
To learn how and get the full Claude guide:
1. Go to https://t.co/xViEAXTX7v
2. Subscribe free by just writing your email.
3. Open my welcome email and get the free resources.
Repost ♻️ to help someone in your network.
🚨 𝟔 𝐓𝐲𝐩𝐞𝐬 𝐨𝐟 𝐋𝐋𝐌𝐬 𝐩𝐨𝐰𝐞𝐫𝐢𝐧𝐠 𝐭𝐨𝐝𝐚𝐲’𝐬 𝐀𝐈 𝐚𝐠𝐞𝐧𝐭𝐬
1️⃣ 𝐆𝐏𝐓 – 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐏𝐫𝐞-𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐓𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐞𝐫
(𝑇ℎ𝑒 𝐺𝑒𝑛𝑒𝑟𝑎𝑙𝑖𝑠𝑡)
Trained on massive datasets, these autoregressive models are the foundational engines for writing, reasoning, coding, and open-ended conversation.
➜ Highly versatile across diverse domains
➜ Excels at zero-shot and in-context learning
➜ The ultimate foundation for downstream fine-tuning
2️⃣ 𝐌𝐨𝐄 – 𝐌𝐢𝐱𝐭𝐮𝐫𝐞 𝐨𝐟 𝐄𝐱𝐩𝐞𝐫𝐭𝐬
(𝑇ℎ𝑒 𝑆𝑐𝑎𝑙𝑒𝑟)
Instead of activating the full neural network, MoE uses sparse routing to send each input only to the most relevant subset of "expert" sub-networks.
➜ Radically higher compute efficiency during inference
➜ Scales seamlessly to trillions of parameters
➜ Achieves deep specialization without sacrificing overall performance
3️⃣ 𝐕𝐋𝐌 – 𝐕𝐢𝐬𝐢𝐨𝐧-𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝑀𝑢𝑙𝑡𝑖𝑚𝑜𝑑𝑎𝑙)
Combines advanced vision encoders with language models to natively process and reason over spatial data—like images, complex diagrams, and video streams.
➜ Understands deep visual and spatial context
➜ Perfectly aligns pixel data with semantic text
➜ Enables rich multimodal tasks (like visual QA and image-based telemetry)
4️⃣ 𝐋𝐑𝐌 – 𝐋𝐚𝐫𝐠𝐞 𝐑𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝑇ℎ𝑖𝑛𝑘𝑒𝑟)
Built for "System 2" thinking. Optimized for multi-step reasoning, logical problem-solving, and planning through explicit verification and self-correction loops.
➜ Elite mathematical and logical planning
➜ Drastically reduced hallucinations through step-by-step verification
➜ Excels at complex, highly constrained problem-solving
5️⃣ 𝐒𝐋𝐌 – 𝐒𝐦𝐚𝐥𝐥 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝐿𝑖𝑔ℎ𝑡𝑤𝑒𝑖𝑔ℎ𝑡)
Compact, highly optimized models engineered specifically for edge devices, offline execution, or highly cost-sensitive environments.
➜ Ultra-low latency and blazing-fast inference
➜ Highly cost-effective to deploy and maintain
➜ Ensures data privacy through strictly on-device processing
6️⃣ 𝐋𝐀𝐌 – 𝐋𝐚𝐫𝐠𝐞 𝐀𝐜𝐭𝐢𝐨𝐧 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝐷𝑜𝑒𝑟)
Designed not just to generate text, but to execute real-world tasks using tools, APIs, and external environments. It operates on a continuous agent loop:
🔄 Plan ➟ Action ➟ Observation ➟ Reflect ➟ Update Memory
➜ Autonomous real-world execution
➜ Native integration with external systems and software
➜ Dynamically adapts to environmental feedback
Agents aren’t just chatbots anymore. They see, act, reason, and run anywhere from cloud GPUs to edge devices. 𝐶ℎ𝑜𝑜𝑠𝑖𝑛𝑔 𝑡ℎ𝑒 𝑟𝑖𝑔ℎ𝑡 𝐿𝐿𝑀 𝑡𝑦𝑝𝑒 𝑑𝑖𝑟𝑒𝑐𝑡𝑙𝑦 𝑖𝑚𝑝𝑎𝑐𝑡𝑠 𝑐𝑜𝑠𝑡, 𝑙𝑎𝑡𝑒𝑛𝑐𝑦, 𝑟𝑒𝑙𝑖𝑎𝑏𝑖𝑙𝑖𝑡𝑦, 𝑎𝑛𝑑 𝑟𝑒𝑎𝑙‑𝑤𝑜𝑟𝑙𝑑 𝑐𝑎𝑝𝑎𝑏𝑖𝑙𝑖𝑡𝑖𝑒𝑠.
If you find this resource valuable:
Save 💾 ➞ React 👍 ➞ Share ♻️
Cc : author
// Agentic Harness Engineering //
Pay attention to this one, AI devs.
(bookmark it)
Most coding-agent harnesses are still tuned by hand or brittle trial-and-error self-evolution.
This new work introduces Agentic Harness Engineering, a framework that makes harness evolution observable. They do this through three layers: components as revertible files, experience as condensed evidence from millions of trajectory tokens, and decisions as falsifiable predictions checked against task outcomes.
Each edit becomes a contract you can verify or revert.
Results: pass@1 on Terminal-Bench 2 climbs from 69.7% to 77.0% in ten iterations, beating human-designed Codex-CLI (71.9%) and self-evolving baselines like ACE and TF-GRPO.
The evolved harness also transfers across model families with +5.1 to +10.1 point gains, while using 12% fewer tokens than the seed on SWE-bench-verified.
Harness work is the biggest hidden cost in most agent systems. This is the first credible recipe for letting the harness improve itself without drifting into noise.
Paper: https://t.co/9fEgqwlTSf
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
💯 Đây là cách công ty AI native vận hành - Chia sẻ bởi CEO của https://t.co/vzjJqiMtcs
Ông CEO của https://t.co/vzjJqiMtcs chia sẻ về cách họ vận hành một công ty AI-native, anh em đọc thử xem có áp dụng được gì không 😁
Điểm khác biệt lớn nhất là họ không dùng AI như một tool phụ trợ, mà thiết kế lại toàn bộ cách làm việc xoay quanh AI ngay từ đầu. Kiểu không phải “dùng thêm AI cho nhanh”, mà là build cả hệ thống để AI có thể làm việc cùng team.
Toàn bộ dữ liệu công ty được gom vào một repo GitHub gọi là “Company OS”. Trong đó có đủ thứ: tài liệu nội bộ, SOP, playbook, dữ liệu thị trường… Mỗi client cũng có một repo riêng, chứa toàn bộ context như brand, campaign, lịch sử làm việc. Nhờ vậy, mỗi lần làm việc với Claude là đã có sẵn context, không cần ngồi giải thích lại từ đầu.
Thay vì làm việc qua mấy cái UI SaaS như bình thường, họ chuyển dần sang dùng Claude Code + CLI + MCP. Nghe hơi technical nhưng hiểu đơn giản là AI không chỉ “gợi ý” nữa, mà có thể trực tiếp làm việc: đọc file, sửa dữ liệu, chạy workflow, kết nối với Slack, Google Docs, Airtable… Lúc này AI không còn đứng ngoài nữa, mà tham gia luôn vào hệ thống vận hành.
Các việc lặp lại như onboarding khách hàng, research nội dung, xử lý phản hồi hay kiểm tra campaign trước khi chạy thì gần như để AI làm hết. Con người tập trung vào mấy phần quan trọng hơn như strategy với creative. Nhờ vậy team không cần tăng người quá nhiều mà vẫn scale được.
Một điểm mình thấy khá hay là hệ thống này tự cải thiện theo thời gian. Team có thể thêm agent, skill, chỉnh workflow thông qua pull request như code bình thường. Đồng thời dữ liệu từ quá trình làm việc cũng được đẩy ngược lại để AI học tiếp. Càng dùng lâu thì hệ thống càng “khôn” hơn.
Mời các bạn join @nghienaivn tại đây, có nhiều bài viết xịn, anh em cộng đồng support xịn 😁
https://t.co/wOX7GsW3qv
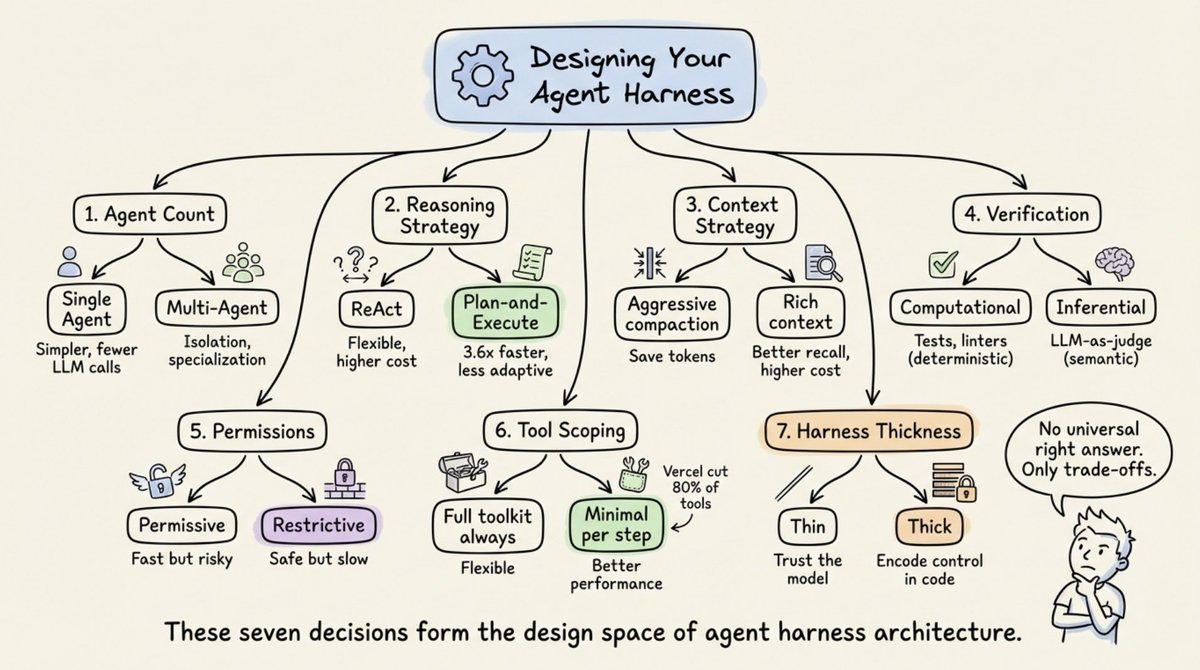
Design principles for building an Agent harness.
Most agent builders get three of the seven core design decisions exactly backwards.
Every production agent harness is the result of seven architectural bets. Agent count, reasoning strategy, context strategy, verification, permissions, tool scoping, and harness thickness.
On three of these, the obvious answer is the wrong one.
𝗠𝗼𝗿𝗲 𝘁𝗼𝗼𝗹𝘀 𝗺𝗲𝗮𝗻𝘀 𝗮 𝗺𝗼𝗿𝗲 𝗰𝗮𝗽𝗮𝗯𝗹𝗲 𝗮𝗴𝗲𝗻𝘁.
This is the first intuition that breaks. More tools feels like more capability, the same way more options on a menu feels like a better restaurant.
It isn't.
Every tool you expose to the model eats context, adds a decision point, and creates another chance for the model to pick the wrong function for the job. Vercel cut 80% of the tools from v0 and the agent got better. Claude Code dynamically loads only the tools needed for the current step and cuts context by 95%.
The principle is the opposite of what most teams ship with. A bloated toolkit looks like capability and behaves like cognitive load.
𝗥𝗲𝗔𝗰𝘁 𝗶𝘀 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗿𝗻 𝘄𝗮𝘆. 𝗣𝗹𝗮𝗻𝗻𝗶𝗻𝗴 𝗶𝘀 𝗼𝗹𝗱 𝘀𝗰𝗵𝗼𝗼𝗹.
ReAct is the default pattern in most tutorials. Think, act, observe, repeat. It feels sophisticated because the model reasons at every step.
But reasoning at every step is expensive. Plan-and-execute, where the agent makes a plan once and then runs through it, hits 3.6x faster on many workloads. The reason is simple. Most steps in a multi-step task don't need fresh reasoning. They need execution.
ReAct buys adaptability. Plan-and-execute buys speed and predictability. For bounded tasks with clear structure, planning once and executing wins cleanly. The "obviously more advanced" pattern is often the worse choice.
𝗣𝗲𝗿𝗺𝗶𝘀𝘀𝗶𝘃𝗲 𝗵𝗮𝗿𝗻𝗲𝘀𝘀𝗲𝘀 𝘀𝗵𝗶𝗽 𝗳𝗮𝘀𝘁𝗲𝗿. 𝗥𝗲𝘀𝘁𝗿𝗶𝗰𝘁𝗶𝘃𝗲 𝗼𝗻𝗲𝘀 𝘀𝗹𝗼𝘄 𝘆𝗼𝘂 𝗱𝗼𝘄𝗻.
This is the one that burns teams in production.
Permissive harnesses feel fast in development. The agent just works. It calls tools, mutates state, takes actions. No friction. No approval gates.
Then it ships. And the first time the agent does something irreversible that it shouldn't have, the post-mortem starts. Restrictive harnesses feel slow because they ask for confirmation on high-stakes operations. That friction is the feature. A gated tool call is a tool call you can still recover from.
The teams that ship permissive harnesses to production are the ones who haven't yet had the incident that makes them switch.
𝗧𝗵𝗲 𝗽𝗮𝘁𝘁𝗲𝗿𝗻
All three mistakes share a shape. The intuitive answer optimizes for what feels good during development. More capability on display, more reasoning happening, less friction in the loop. The correct answer optimizes for how the agent actually performs under real workloads. Less context pressure, fewer wasted LLM calls, fewer irreversible mistakes.
The diagram below lays out all seven decisions. The ones above are where most teams are currently betting wrong.
The article goes deep on each trade-off, with examples from how Anthropic, OpenAI, CrewAI, and LangChain have actually answered them.
I'm also building a minimal agent harness from scratch. Didactic, easy to read, no magic. Open-sourcing it soon. Stay tuned.