SV is more like the best factory that converts innovation to great real-world impact. creating top-down structure around innovation feels very hard and the best innovative ideas still come from everywhere (incl SV)!
People at major AI labs (using internal models) 3-4 months ahead of startup silicon valley engineers
SV founders/eng 3-6 months ahead of NY
NY founders/eng 6-12 months ahead of rest of world
Most people have no idea how fast AI shifting as 1-2 years behind SOTA
"The future is here, just not equally distributed" - Robert Heinlein
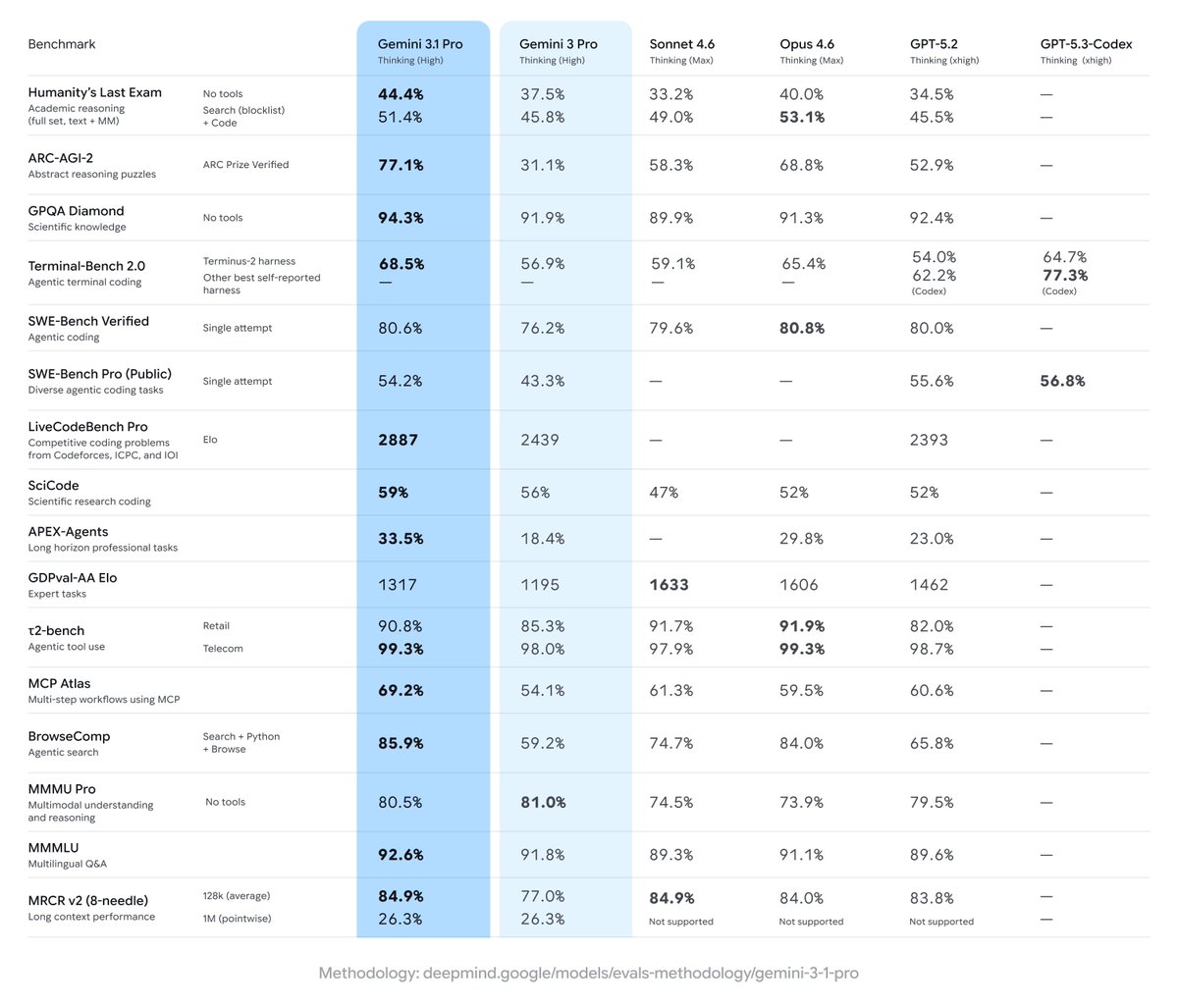
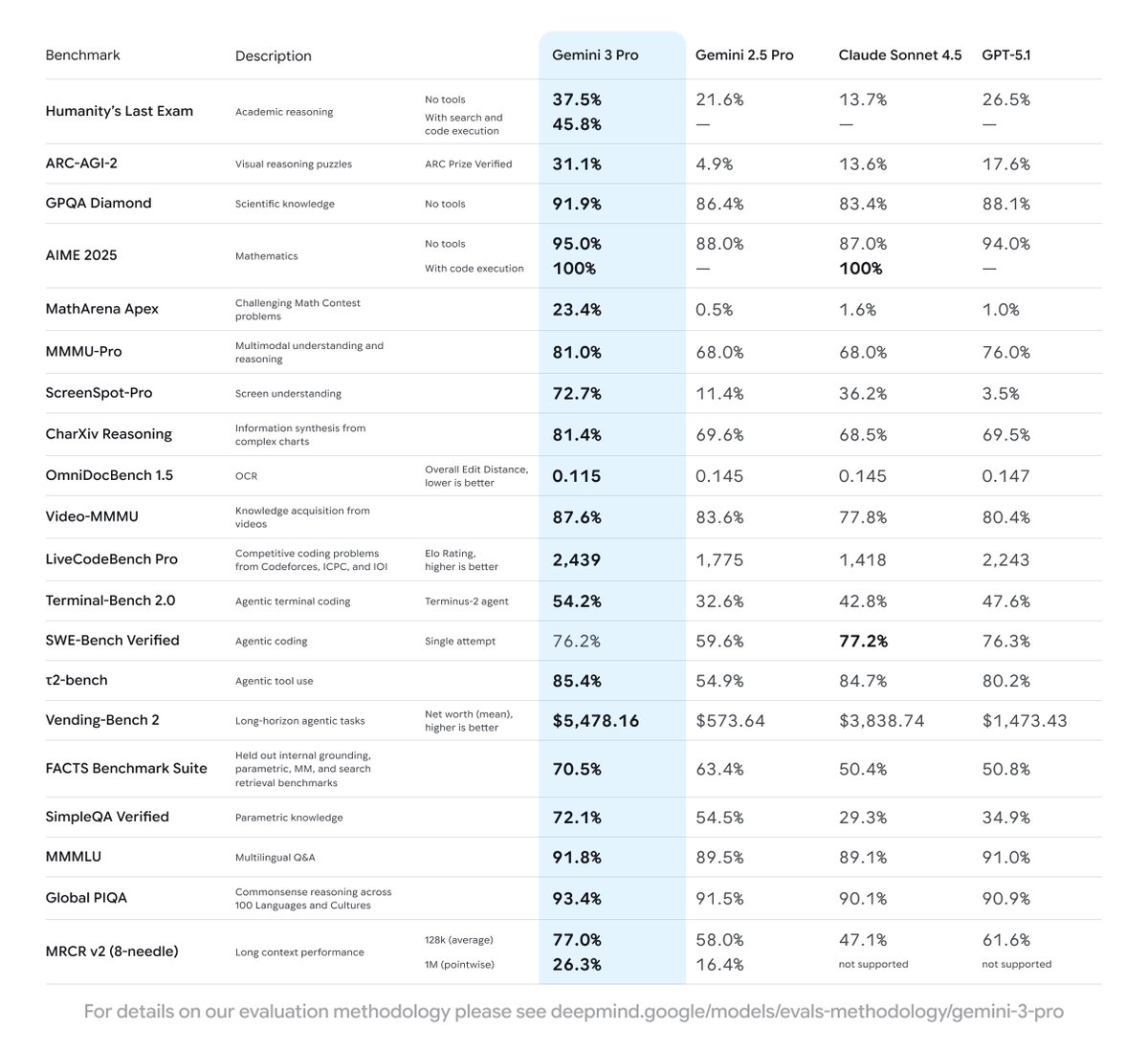
Gemini 3.1 Pro has landed! Amazing performance / capabilities across the board.
Beyond SOTA, the best are all the things that evals can't measure. E.g. SVG has gotten so much better (see 🧵)
https://t.co/JDhT0NRY5L
The secret behind Gemini 3?
Simple: Improving pre-training & post-training 🤯
Pre-training: Contra the popular belief that scaling is over—which we discussed in our NeurIPS '25 talk with @ilyasut and @quocleix—the team delivered a drastic jump. The delta between 2.5 and 3.0 is as big as we've ever seen. No walls in sight!
Post-training: Still a total greenfield. There's lots of room for algorithmic progress and improvement, and 3.0 hasn't been an exception, thanks to our stellar team.
Congratulations to the whole team 💙💙💙
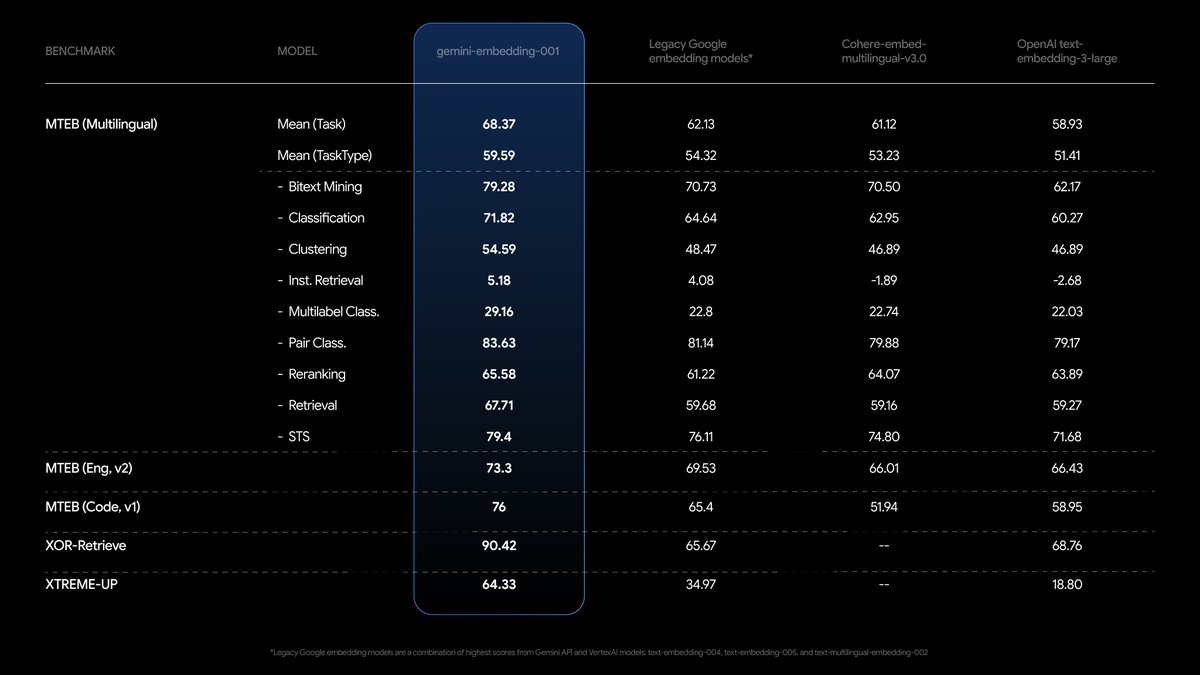
Today we are rolling out our first Gemini Embedding model, which ranks #1 on the MTEB leaderboard, as a generally available stable model. It is priced at $0.15 per million tokens and ready for at scale production use!
thrilled to be back @Google in the @GoogleDeepMind team! The technical breadth and expertise across the whole stack (hardware->infra->deep learning->products) is truly mind-blowing. Great to see a lot of familiar faces and meet new friends. Look forward to learning a lot!
Excited to join @AIatMeta! The past 4.5 years at @OpenAI,working on embeddings, GPT-3 & 4,API and ChatGPT, have been career highlights. Now, I'm thrilled to work on the next generations of Llama and contribute to its impact on the developer ecosystem and billions of users!🚀 1/2
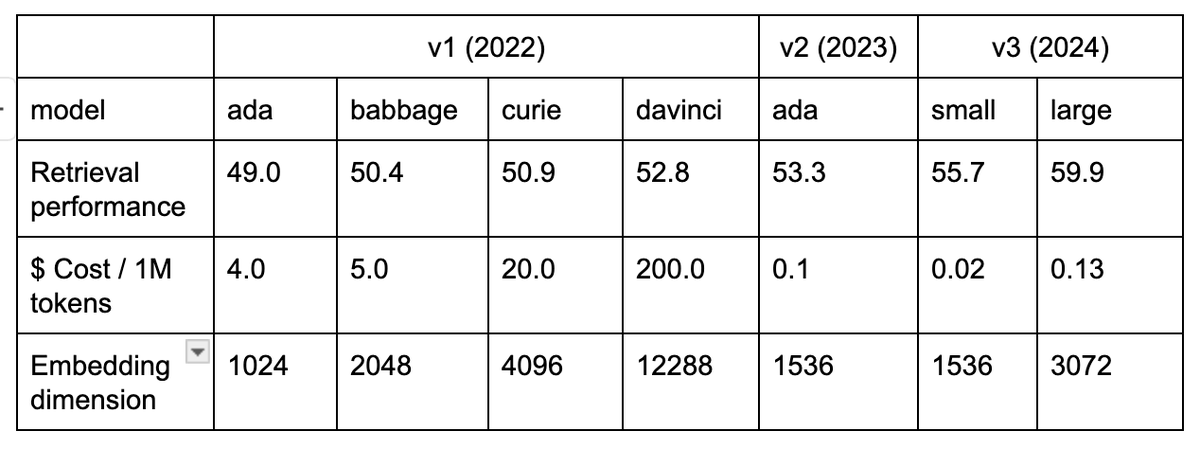
Announcing a new generation of embedding models:
• text-embedding-3-small: 5x cheaper and stronger performance compared to the previous generation
• text-embedding-3-large: our best performing model, creating embeddings with up to 3072 dimensions
https://t.co/2J6rq1Sz5e