This Google DeepMind’s paper is a serious warning for anyone using autonomous agents today.
Gives the first clear taxonomy of 6 attack types where harmful websites can detect AI agents and show them hidden content humans never see, like
- Instructions buried in HTML comments or white-on-white text
- Steganography in image pixels
- Override commands in PDFs, metadata, or even speaker notes
- Memory poisoning that persists across sessions
- Goal hijacking and cross-agent cascades in multi-agent setups
The real security problem for AI agents is not just the model, but the environment it reads.
The web itself can be weaponized against autonomous AI agents. As agents increasingly browse the internet, read emails, execute transactions, and spawn sub-agents, the information environment becomes an attack surface.
In one cited benchmark, hidden prompt injections embedded in web content partially commandeered agents in up to 86% of scenarios, sub-agent hijacking working 58–90% of the time, and data exfiltration attacks clearing 80% across five different agent architectures.
That reframes the whole debate.
We usually talk about model safety as if the danger sits inside the weights, but agents do something more fragile: they browse, retrieve, remember, and act on untrusted material in real time.
Here’s the thing to worry about.
A web page does not have to look malicious to be dangerous to an agent, because the agent may parse what humans never see: hidden HTML comments, metadata, CSS-hidden text, formatting syntax, or adversarial content embedded in images and other media.
The threat gets more serious once memory enters the loop.
If an agent uses RAG or persistent memory, poisoning no longer has to win in one shot. It can sit quietly in a corpus or memory store and activate later, which is why the paper highlights results showing latent memory poisoning above 80% attack success with less than 0.1% data contamination.
---
ssrn .com/sol3/papers.cfm?abstract_id=6372438
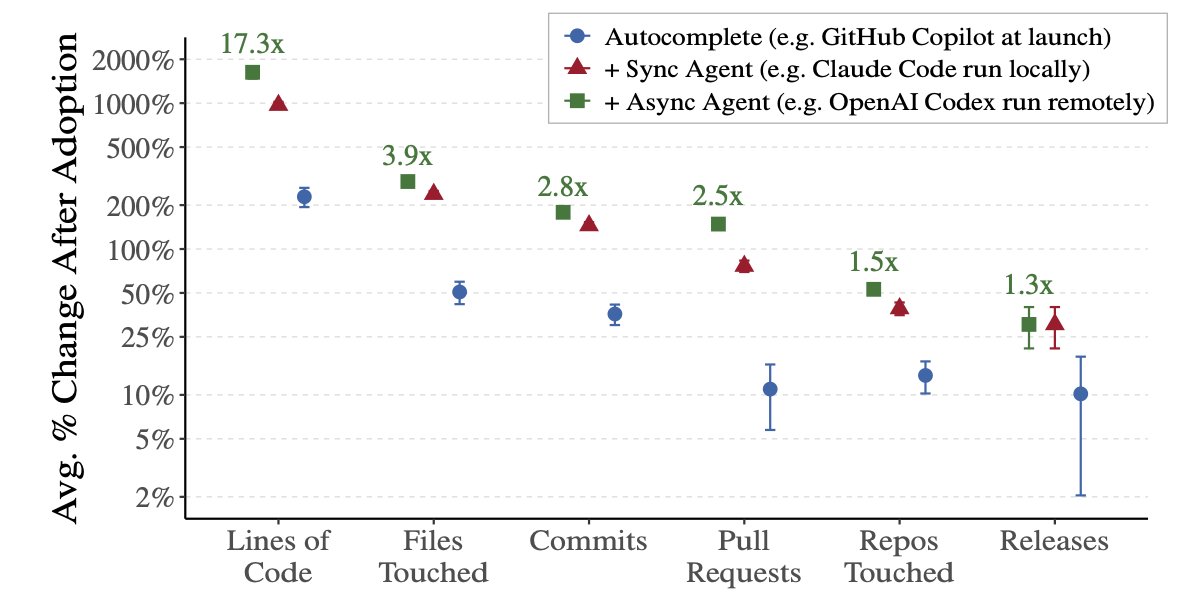
Big paper on AI coding agents using Github & other data
The auto-complete tools (Copilot) led to 2.2x more code, local agents like original Claude Code led to 7.4x, & current remote coding agents 17.3x(!)
But human bottlenecks in coding means actual releases "only" went up 30%
A new and possibly controversial perspective:
In this video, I explain the sense in which generative AI trained by supervised learning is incapable of making novel discoveries.
https://t.co/zin5QbbT9N
The text of the speech:
AI Creativity and Discovery
Good day ladies and gentlemen. I regret that I am unable to be with you all today to engage in a back-and-forth discussion, but I am nevertheless pleased to be able to share with you, via this recording, some high-level thoughts about the current and future state of artificial intelligence, and in particular about AI’s relationship to science and mathematics, which is, as I understand it, the central focus of this meeting and of the SAIR Foundation.
I would like to start with an old joke; I am sure you have heard it before. It is the one about the researcher whose work is being evaluated, and the review comes back, and says “This work is both novel and good. Unfortunately, the parts that are good are not novel, and the parts that are novel are not good.”
My first point about AI is that this assessment applies exactly to large parts of AI as we know it today. Not all of today’s AI, but a large part of it. Pretty much all of what we mean by “Generative AI”---which includes large language models, and the images and video models, and even the new methods for learning world models. All of these AIs take large numbers of examples and produce a “model” which behaves similar to the examples, that is, which generates text like people, or images like artists or nature, and videos like we find on the internet. Don’t get me wrong, Generative AI can be extremely useful. No doubt about that. But the assessment of the joke still applies. These systems can produce output that is both novel and good, but not at the same time.
In many ways this is just absolutely not a problem. When we ask an AI for an answer from the internet, or to summarize a document, we don’t want it to be novel. We are happy if the quality of the answer, the goodness, comes from the source material—from the people who wrote the document or the articles on the internet. If the AI’s answer is novel it means it is going beyond the source material, adding something beyond it. This is what we call “hallucinations”. In most cases, we don’t like it when the AI makes something up, when it adds something novel.
One exception, of course, is when we are looking not for facts or reality, but for fiction and entertainment. We might ask for a bedtime story for a child, or an image based on existing images on the internet but which is nevertheless different and distinct from them. In these cases, it is never easy for us to know how creative the AI is actually being, as we do not know how close the AI’s story, poem, or image is to the source material. In a real practical sense we can not know this because the internet is too big, the possible sources that the AI may draw upon are too numerous.
When we ask for a fiction or novelty, the AI can give it to us because its processing is in part stochastic. Every decision can go multiple ways and will go different ways and produce a different trajectory every time. The trajectory can be random—and thus novel—or it can be based on the training data—and thus “good” because the training data is good, sourced from people or reality. Thus, the trajectory is either novel or good—based on randomness or based on data—but never both at the same time.
Really, I think it is okay if the output of Generative AI is never good and novel at the same time. For the researcher in the joke this is a devastating criticism, but for most things it is not, and for Generative AI it is not. Generative AI is meant to be a mimic. This is what supervised learning is for. Generative AI can be extremely useful, even when it just mimics, if it is faster, or cheaper, or smaller, or more customizable, or more copy-able, than the thing being mimicked. It is okay if Generative AI cannot be both novel and good at the same time. It is still a transformative technology.
But it is a limitation. And remember we are here to use AI for science and mathematics, and for these areas the assessment of the reviewer in the joke is devastating. For these areas we need true creativity and discovery. Generative AI—or Mimicking AI—will never get where us there. For these we need something more, and indeed we have something more in other parts of AI. We have many AI systems which can give us more. We have AlphaGo with its world-changing move 37, or AlphaZero with its brilliant original chess-playing style. We have GT-Sophy that drives simulated racecars better than any human. We have AlphaFold and AlphaProof and Claude-Code, which have brought true advances in science, mathematics, and programming. We have RL-Lyft which optimizes the assignment of cars to passengers in the ride-hailing business. All these systems have found things that are both novel and good. And, truth be told, some language models have been augmented in ways that make them more than Generative AI based on supervised learning.
All these systems have some additional features that make them capable of true creativity and true discovery. It is important for us to recognize what this is—and that it is not present in ordinary, garden-variety Generative AI. It is something that can not come from just supervised learning, from learning from examples. What is it? Well, it is a simple thing, a commonsense thing. It is not new. We have many names for it, but unfortunately none of them are very good names. I will call it Discovery. Basically, Discovery is just the idea of trying many things and seeing which of them work, then keeping those that worked the best. Evolution by natural selection works this way. The scientific method works this way. And just ordinary life and learning works this way. We try things and remember what works. What could be more obvious? In this behavioral case, psychology has two names for it— “instrumental learning” and “operant conditioning”—and in machine learning it is what we mean by “reinforcement learning”. We also see the idea of Discovery in planning and combinatorial search—anything that involves the idea of “generate and test”.
The essence of Discovery is to combine three steps:
1. Variation,
2. Evaluation, and
3. Selective retention.
Of course, I am not the first to say this. I am not the first to point out that this combination of steps is key to science, to evolution by natural selection, and to animal behavior. I think particularly of papers by Donald Campbell, by Daniel Dennett, and by Gary Cziko. What is new in my remarks is to directly relate the idea of Discovery to modern AI to help us see that it is not present in supervised learning or Generative AI—in particular, that Discovery is not present in backpropagation or gradient descent.
Let me say explicitly what is missing from Generative AI. As we have remarked, these systems do have a stochastic aspect, so they do generate a variety of trajectories and behavior. What is missing is the Evaluation step. The generator was pre-trained by supervised learning, leaving no way at runtime to Evaluate what it generates. And of course without Evaluation there can be no Selective retention, and thus no Discovery. The variation can bring novelty, but without evaluation there is no Discovery, and arguably, no creativity. That is, I would say that creativity requires that the new things generated be Evaluated. Without evaluation, and retention of the best, there is nothing created. The novelty flickers into existence but, if its value is unrecognized, it flickers away and is lost.
In many cases, Evaluation is done by people to make a discovery. As when we have Generative AI make many pictures for us, and then we pick the one that we like the best. The human+AI system completes the discovery.
In many other cases, the Evaluation comes from a clear objective. Some moves lead to checkmate, some steps lead to a proof, some actions result in high reward, some genotypes make more copies, some theories explain the data better.
Some prefer the Variation step to be called Blind variation, where “blind” here means that it is uninformed, a shot in the dark. It does not need to be completely uninformed; a good scientist does not select theories to test at random. But neither can it be completely informed and determined. There must be some uncertainty about where the answer lies in order for there to be a discovery. In practice, the variation is partly informed and partly blind, but it is the blind part that corresponds to the discovery.
Now let us briefly go all the way to modern deep learning, to the backpropagation algorithm. At first it might seem that backpropagation is incapable of discovery because it is deterministic and thus incapable of variation. But this is not correct. The weight updates of backprop are deterministic, but the weights are initialized to small random values. The random initialization is often downplayed, but in fact it is a necessary form of variation; it must be done properly to get good performance. In backprop this Variation is done once, at network initialization, so its effect is temporary, and later the network may lose its ability to learn. This is the weakness of deep learning that is alleviated with a new algorithm that my group presented in Nature a couple of years ago. Our “continual backpropagation” made one small change: every so often a less-used neuron would be re-initialized to small random weights. This allows the variation to continue and plasticity to be retained.
Although there is much more to be said about Creativity and Discovery, this is the key point: they are more than supervised learning, more than pattern recognition, more than prediction, and more than world modeling. Those things are important, but they alone will not bring us to discovery. Discovery requires Evaluation from a person or from an explicit goal, and only in the latter case will we attain full autonomy.
So that is my call to arms. If we want the full power of AI scientists, then we should share the goals with them so they can create, evaluate, discover, and in these ways fully participate in achieving the goals. Let’s be bold! Let’s fully automate Creativity and Discovery!
I wrote up how I built the shitty robot so you can too. This was a fun project that will keep on giving.
Thanks to all the open weights folks out there, without whom this would not have been possible.
https://t.co/egPxlCECQg
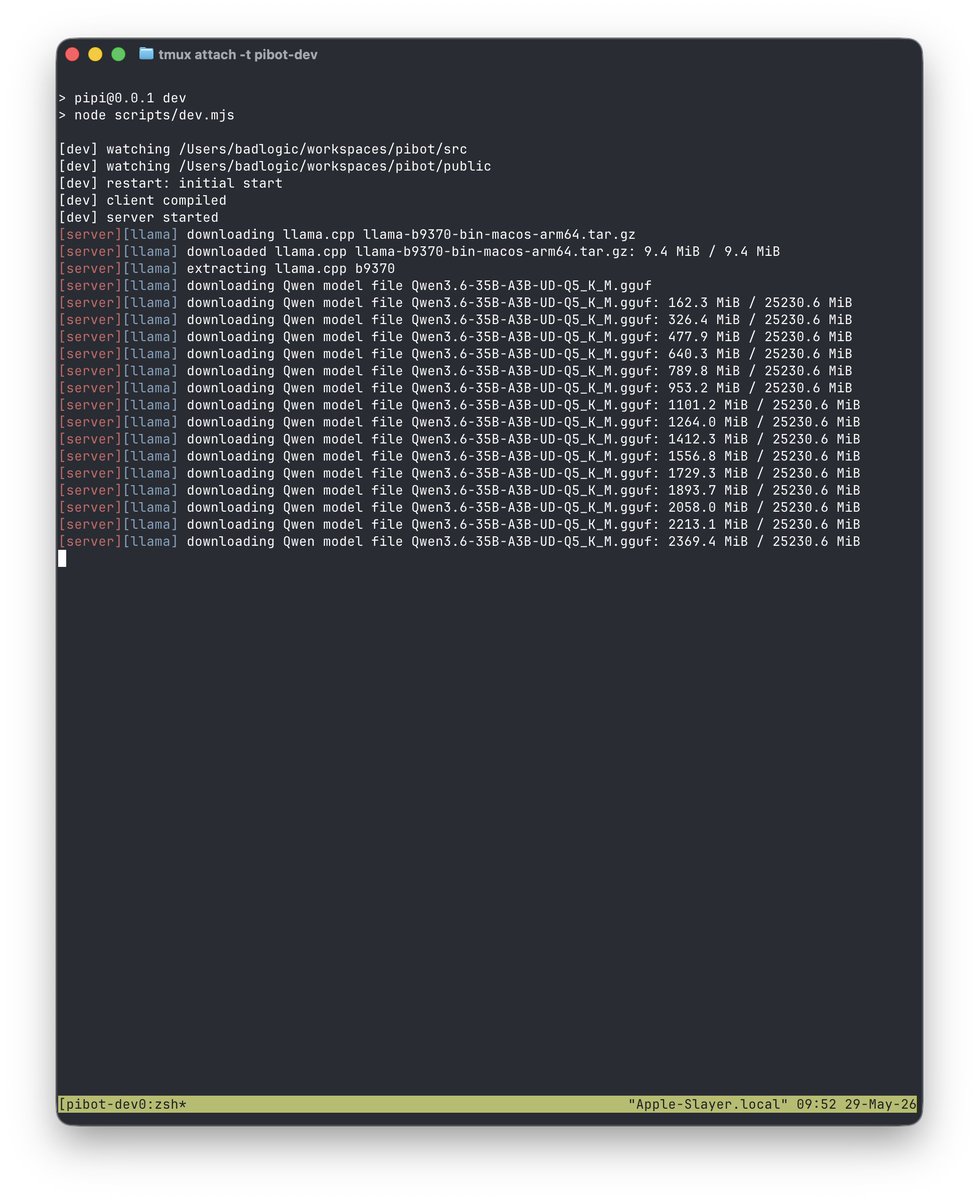
pibot is now running fully local, using parakeet for STT, qwen3-tts for TTS, and Qwen 3.6 as the local multi-modal LLM via llama.cpp.
The STT and TTS inference engines are Rust/mlx-c based. Ported from Python. So, zero Python dependencies :D
🦀 The Rust frontend is officially merged into vLLM!
As GPUs get faster, the frontend has become a real share of CPU time. The new Rust frontend is a drop-in alternative to the Python API server — same engine, same ZMQ boundary. Opt in with VLLM_USE_RUST_FRONTEND=1.
Early numbers: on a preprocess-heavy workload, ~837 req/s vs ~162 req/s for default Python — ~5x in a single process.
A few design choices we're excited about:
• Layered crates with clear boundaries
• Stream-native pipeline — non-streaming for free
• Builds on stable Rust
Huge thanks to @BugenZhao from @inferact for introducing the work at @PyTorch Meetup Singapore.
https://t.co/Tw8PoIjbH9
Finally, a big name has the courage to tell it: we are nowhere near AGI.
Demis Hassabis, CEO of Google DeepMind and Nobel laureate for AlphaFold, put it neat and clear:
"Today's systems are nowhere near [AGI]. Doesn't matter how many Erdős problems you solve… I think it's far, far from what a true invention, or someone like Ramanujan, would have been able to do."
This is the elephant in the room that many AI enthusiasts prefer not to see, or are actively trying to hide.
Erdős problems are well defined, often combinatorial, on finite spaces. They are exactly the kind of problems on which current AI can achieve spectacular performance with a lot of compute and knowledge.
A neural network can search a huge graph of possibilities. It can recombine existing knowledge at unprecedented scale. It can discover surprising solutions inside an already defined conceptual space.
But true invention is something else.
True invention is not only solving a problem.
It is inventing new objects, new dimensions, new connections. It is inventing new problems.
From resolving to inventing there is a discontinuity that we don't know how to bridge.
We are making extraordinary tools.
But we are nowhere close to AGI.
We have an arxiv paper up describing the work in more detail here: https://t.co/aay4YmjBR2.
Also want to call out that there is even more room for improvement, some recent updates to wllama by @ngxson mean it's even more memory efficient than what we describe in the paper!
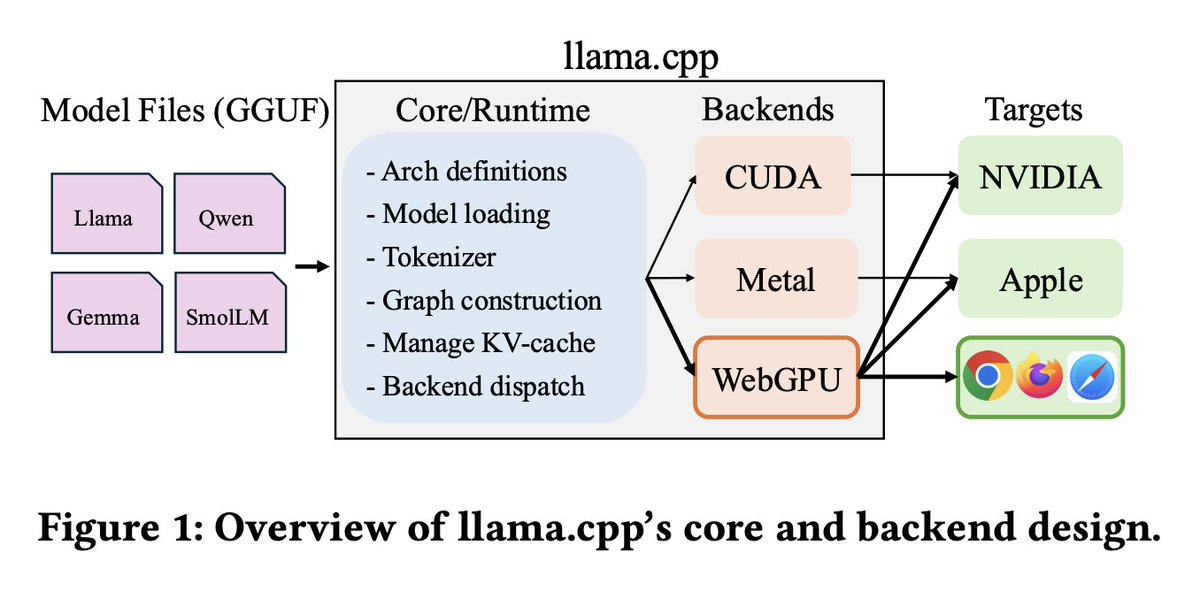
Highlighting the new WebGPU backend in llama.cpp/ggml
The work to bring full-fledged WebGPU support in llama.cpp started about an year and a half ago. It has been lead by @reeselevine and team at USCS.
For more information, checkout the interactive blog and paper in the quoted post. Here are 2 excerpts from the paper, summarizing the implemented software architecture.
I released the first alpha of Datasette Agent - a conversational AI assistant for Datasette that can answer questions about data in SQLite databases, and can be extended with plugins to add extra tools and features
Here's a demo
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Brilliant leaders in semantic web @oshaniws of @rpi and @origin_trail’s @BranaRakic taking the audience to the next generation shared context graphs for verifiable AI.
A researcher spent two years documenting what AI is doing to the way humans think.
His conclusion fits in one sentence.
AI is standardizing human thought. Across societies. Across cultures. Across generations. Simultaneously. At a scale no technology in history has ever achieved.
The paper is called "The Impact of Artificial Intelligence on Human Thought." Published July 2025 on arXiv. Written by independent researcher Rénald Gesnot, categorized under Computers & Society and Human-Computer Interaction.
It is not a benchmark paper. It is not a capability paper. It is something rarer — a systematic analysis of what happens to human cognition, creativity, and intellectual diversity when billions of people outsource their thinking to the same machine.
Here is the mechanism the researcher describes.
When you ask an AI a question, you get an answer shaped by the model's training data, its fine-tuning, its alignment process, and the preferences of the company that built it. That answer is not neutral. It reflects a specific set of values, framings, and assumptions. Usually Western. Usually English-dominant. Usually optimized for engagement and approval.
When 500 million people ask the same AI similar questions and receive similar answers, those answers become reference points. People quote them. Build on them. Argue from them. The diversity of starting points — different cultures, different intellectual traditions, different ways of framing problems — begins to compress.
The researcher describes this as cognitive standardization.
Not censorship. Not propaganda. Something subtler and harder to reverse. A gravitational pull toward the outputs of a small number of models, trained by a small number of companies, reflecting a small number of worldviews.
The paper also documents algorithmic manipulation — AI systems that exploit cognitive biases to influence behavior. The way recommendation algorithms produce filter bubbles. The way AI-generated content exploits confirmation bias. The way personalization systems learn what you already believe and feed it back to you amplified.
And then the creativity question — the one nobody wants to answer directly.
When AI can produce a poem, an essay, a business plan, or a research summary in seconds — and when that output is often indistinguishable from or preferred over human-generated content — what happens to the human practice of creating those things? Not the output. The practice. The struggle. The failure. The slow development of a personal voice through years of imperfect attempts.
The researcher argues that cognitive offloading — delegating thinking tasks to AI — does not merely save time. It atrophies the mental capacity that the offloaded task was building.
Microsoft and Carnegie Mellon found this empirically in 2025: higher AI trust correlates directly with measurably lower critical thinking. The researcher provides the theoretical framework for why.
The paper ends with a question the researcher admits he cannot answer.
Once a generation grows up with AI as the default thinking partner — once the habit of outsourcing cognition is formed before the habit of independent thought is developed — what does intellectual autonomy even mean?
And is it already too late to find out?
Source: Gesnot, R. · "The Impact of Artificial Intelligence on Human Thought" · arXiv:2508.16628 · https://t.co/qoQR2Ow4YI · July 2025
We are LIVE now! Great turnout for the AMA session with Jim & Deborah, moderated by @LarrySwanson !
This is getting us even more excited for the upcoming conference in NYC on May 4–8 😉
This is the single best framework I’ve seen for understanding AI.
Terence Tao, arguably the smartest mathematician alive, just dropped a paper with Tanya Klowden on arXiv called “Mathematical Methods and Human Thought in the Age of AI.”
The core idea: a “Copernican View of Intelligence.”
Stop thinking of AI on a line from “dumb” to “superhuman.”
That’s the wrong axis entirely.
AI excels at BREADTH. Humans excel at DEPTH.
Tao himself said AI has made his papers “richer and broader, but not necessarily deeper.”
That’s not a limitation. That’s the entire playbook.
Stop trying to replace yourself with AI. Start using it to cover the 90% of surface area your brain physically can’t.
The people who get this are already 10x more productive.
The rest are still arguing about whether AI is “smart enough.”
Reframe your point of view from “smarter” to “different”.
Human + AI > either alone.
The math on that has never been clearer.
For everyone wanting more granular detail on how Qwopus 3.5 27B V3 is still an incredible improvement over the base in many use cases, here's an excellent non-biased write-up. One thing not even mentioned here, though, is the VAST creativity improvements for front end design, which is a huge issue with smaller local models, and makes Qwopus 27B a total game changer: https://t.co/069YkKfw9O
Qwopus 27B model card in comments, Gemopus 4 31B coming soon as well! Design showcase linked as well!







































![ValerioCapraro's tweet photo. Finally, a big name has the courage to tell it: we are nowhere near AGI.
Demis Hassabis, CEO of Google DeepMind and Nobel laureate for AlphaFold, put it neat and clear:
"Today's systems are nowhere near [AGI]. Doesn't matter how many Erdős problems you solve… I think it's far, far from what a true invention, or someone like Ramanujan, would have been able to do."
This is the elephant in the room that many AI enthusiasts prefer not to see, or are actively trying to hide.
Erdős problems are well defined, often combinatorial, on finite spaces. They are exactly the kind of problems on which current AI can achieve spectacular performance with a lot of compute and knowledge.
A neural network can search a huge graph of possibilities. It can recombine existing knowledge at unprecedented scale. It can discover surprising solutions inside an already defined conceptual space.
But true invention is something else.
True invention is not only solving a problem.
It is inventing new objects, new dimensions, new connections. It is inventing new problems.
From resolving to inventing there is a discontinuity that we don't know how to bridge.
We are making extraordinary tools.
But we are nowhere close to AGI.](https://pbs.twimg.com/media/HJKS-JdWkAAZOdT.jpg)

























