"You need a 24 GB GPU for serious local LLMs in 2026."
Everyone repeats this. It's not true anymore.
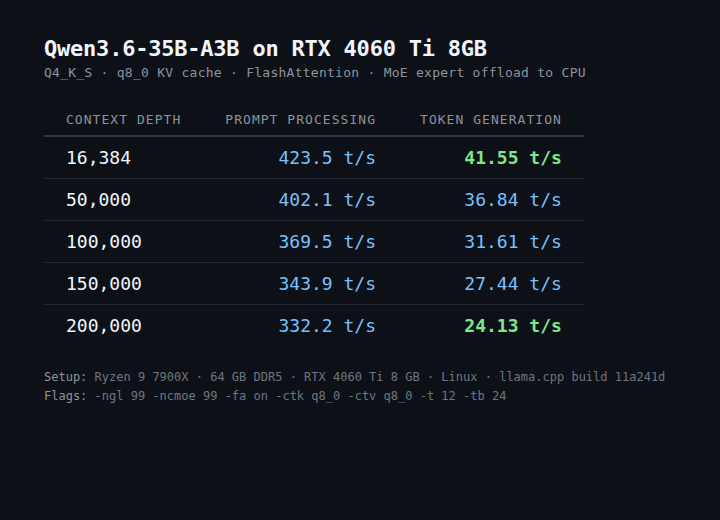
Just ran a 35B-parameter model on an RTX 4060 Ti 8 GB: • 41 tok/s at 16k context • 24 tok/s at 200k context
Recipe + benchmarks below 🧵
🚨 Arkadaşlar, önemli bir uyarı ve çözüm geliyor.
NVIDIA, ücretsiz AI modellerine (NIM) erişim için artık telefon doğrulaması istiyor.
Türkiye numaraları ise sistem tarafından kabul edilmiyor. Bu yüzden birçok kişi ücretsiz API key alamıyor.
Ancak geliştiriciler hızlıca bir çözüm buldu.
GitHub’da yayınlanan bypass yöntemiyle şirket maili veya custom domain kullanarak doğrulama yapmadan ücretsiz erişim sağlayabiliyorsunuz.
Eğer NVIDIA’nın 80+ ücretsiz güçlü AI modelini (Llama, Mistral, Gemma vb.) yerel veya API üzerinden kullanmak istiyorsanız, bu yöntem şu anda en pratik yol.
🔗 Bypass ve Çözüm Repo:
https://t.co/Fpia2mA93b
Sizce bu tür bölgesel kısıtlamalar ve bypass çözümleri, AI araçlarına erişimi ne ölçüde etkiliyor?
Düşüncelerinizi yorumlara yazın, beraber konuşalım.
https://t.co/0MlG2zzC8W