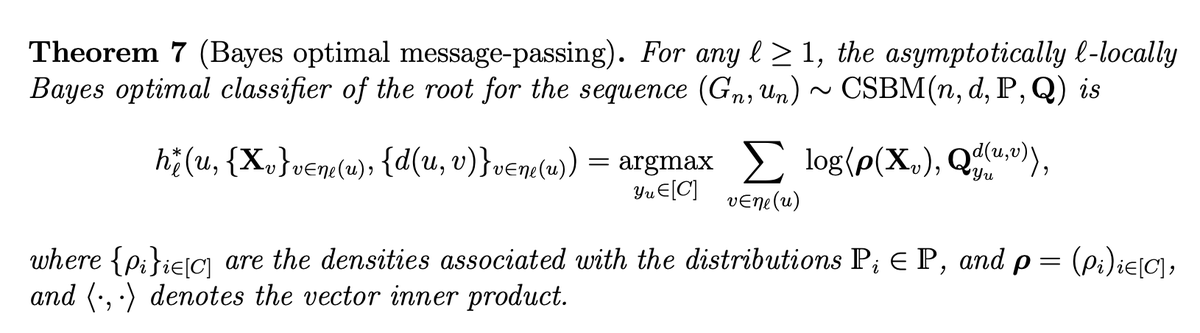wanted to make a few clarifications on openleaf as there’s lot of love from people (thanks❤️!) but also some misunderstanding:
1. "this encourages blind citation" -- openleaf links every suggested paper for a reason. you're supposed to read it before citing (the paper link is right there). it's a discovery tool, and most def not a "cite for me" button.
also, its ranking is purely content-based -- no citation count, no popularity metrics -- specifically to avoid unfair concentration of citations to a select few papers/institutions.
2. "if you do your lit search after writing a paragraph, you're doing it wrong" -- agree! but the demo showed a simplified flow. the real use case: you've read 20 papers, but there are 1000s published monthly. you will miss relevant ones. openleaf helps you find them.
already working on improvements to make it even better:
- reading your existing .bib so it's aware of what you already cite
- analyzing full paper text, not just abstracts
- better reasoning
track progress, suggest features, or pick up an issue! https://t.co/xs1pAhN0so
I am hiring one PhD student.
Subject: Reasoning and AI, with a focus on computational learning for long reasoning processes such as automated theorem proving and the learnability of algorithmic tasks.
Preferred background: A mathematics student interested in transitioning to computer science and machine learning. However, I will also consider engineering and computer science students with a strong mathematical background.
On the Statistical Query Complexity of Learning Semiautomata: a Random Walk Approach
Work with @ggiapitz, @EshaanNichani and @jasondeanlee.
We prove the first SQ hardness result for learning semiautomata under the uniform distribution over input words and initial states, without relying on parity gadgets or adversarial inputs. The hardness is structural, it arises purely from the transition structure, not from hard languages.
We show that SQ hardness can be established when both the alphabet size and input length are polynomial in the number of states.
Waterloo Computational Learning Lab it is: https://t.co/HzPiVnnL6m! I rebranded our lab after six years to better reflect the work we do and will continue to do in the future.
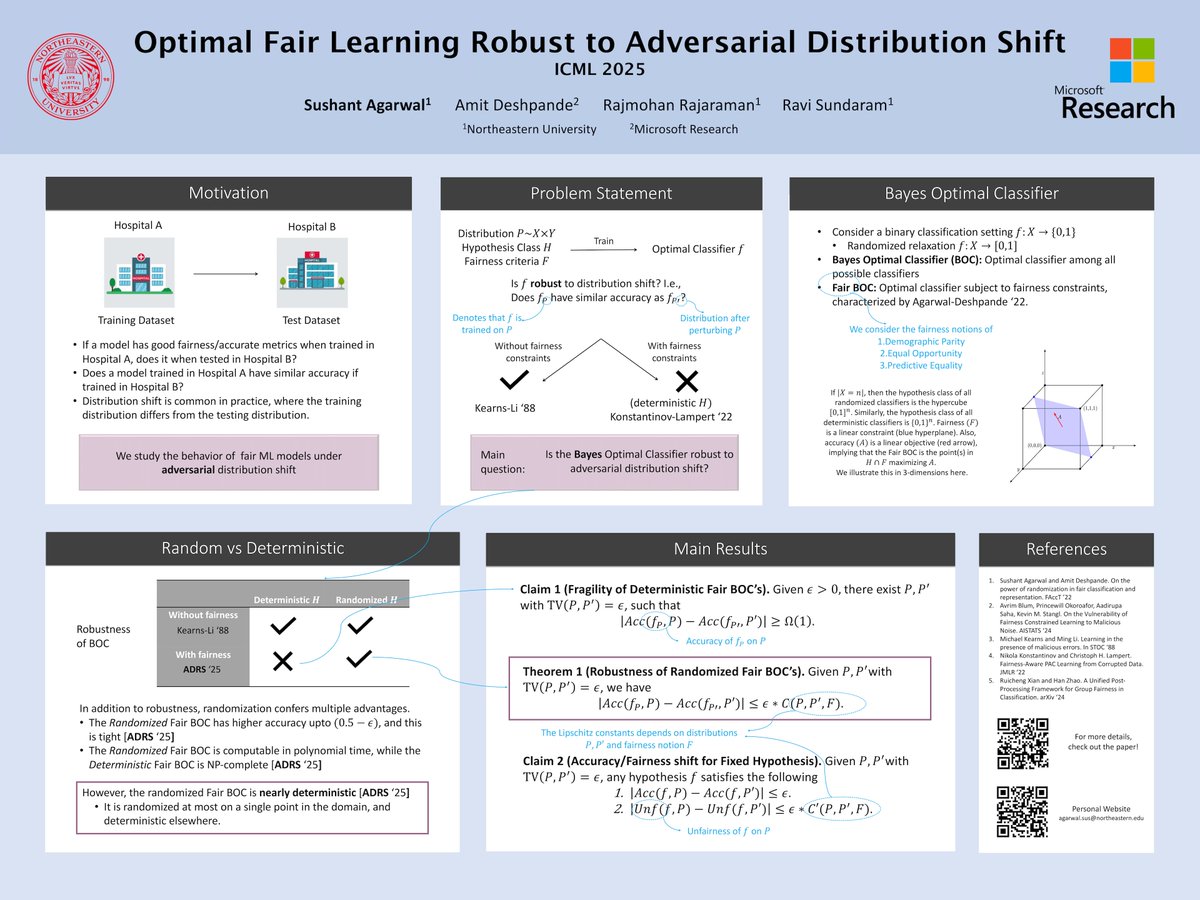
Presenting "Optimal Fair Learning Robust to Adversarial Distribution Shift" at #ICML2025 (https://t.co/LhPEbnjNS8)
📍East Exhibition Hall A-B #E-1001
⏲️16th July, 4:30-7PM
Please have a look, and do stop by if it sounds interesting to you!
RT's appreciated😊Summary to follow
My former PhD student, Aseem Baranwal, won the PhD Dissertation Award from the Department of Computer Science at the University of Waterloo for his thesis, “Statistical Foundations for Learning on Graphs.” Aseem is the first PhD student I graduated, and I couldn't be happier for him.
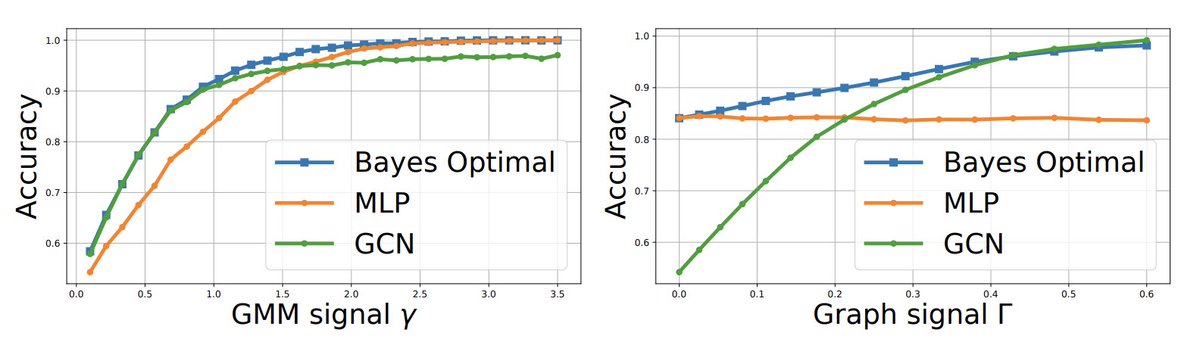
@kfountou This classifier is implementable using a message-passing GNN and is the best of both worlds (an MLP for a noisy graph and a GCN for an informative graph) across the range of SNR in the edges/features on synthetic data. Work is pending to make it scalable for use on real data.
My PhD thesis is now available on UWspace: https://t.co/YrdI3Nupjq. Thanks to my advisors @kfountou and Aukosh Jagannath for their support throughout my PhD. We introduce a statistical perspective for node classification problems. Brief details are below.
@kfountou Following these analyses, we define a precise notion of Bayes optimality for node classification problems and compute the optimal classifier for arbitrary distributions of the node features and edge connectivity.
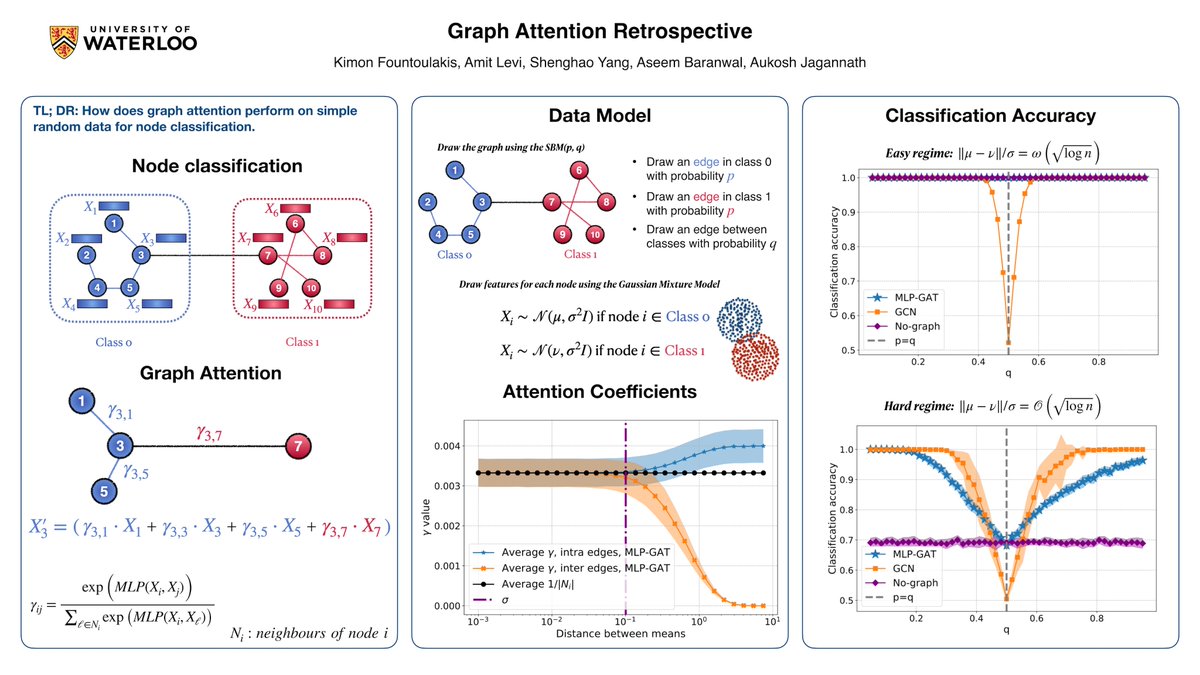
@kfountou We analyze GNNs from this statistical perspective. We isolate the convolutions from the layers for GCN architectures to understand its variance reduction effects on the data. For GAT, we identify regimes of the SNR of the node features where attention helps or does not help.
Positional Attention: Out-of-Distribution Generalization and Expressivity for Neural Algorithmic Reasoning
We propose calculating the attention weights in Transformers using only fixed positional encodings (referred to as positional attention). These positional encodings remain the same across layers, and no other data is used to compute attention weights. We call this architecture positional Transformer, an illustration is shown in the attached figure.
Contribution 1: We show that positional Transformer achieves an average improvement of 1000x (ranging from 400x to 3000x) in out-of-distribution (OOD) value generalization (informally defined below) compared to traditional Transformers during end-to-end training on various algorithmic tasks.
Value generalization describes an OOD setting where the input lengths remain the same, but the values in the test set differ in magnitude or are larger than those seen during training. This is particularly important because, when learning to solve an algorithmic task, the model is expected to perform the task across a range of numbers that it may not have encountered during training. It also serves as an indication that the model is truly learning to solve the underlying problem.
We present OOD generalization results on five tasks: cumulative sum, cumulative minimum, cumulative median, sorting, and cumulative maximum sum subarray. Our results are compared to standard self-attention and various configurations of traditional Transformers, and different positional encodings.
Contribution 2: We prove that positional Transformers can simulate any algorithm defined in a parallel computation model.
Our motivation for positional attention for algorithmic reasoning stems from the following two facts. First, many problems are solved by parallel algorithms, where data communication does not depend on the values of the data but solely on the positions (IDs) of each machine. Second, it is also known that Transformers can function as parallel computers, with data communication managed through attention mechanisms.
arXiv link: https://t.co/X1TljZy31W
code: https://t.co/V9UuAA1ihv
This paper was just accepted at NeurIPS. I am particularly happy about this because it originated as a course project by Robert in our Graph Neural Networks course.
If you are at #ICML2024 and interested in the theory of graph neural networks, come by our poster 'Graph Attention Retrospective.'
conference link: https://t.co/ZOURgL7Jmz
paper: https://t.co/sB7nHPIWZd
relevant blog: https://t.co/4rq6vkQFm0
I guess that as of today I can also announce that I have been promoted to the rank of Associate Professor.
I am mostly making this post to publicly thank all the people who have supported me during my career, especially my first two PhD students, @aseemrb and @shenghao_yang (in alphabetical order), for the great work we have done, the numerous lengthy meetings and discussions, and their devotion to learning.
For those participating in the Complex Networks in Banking and Finance Workshop, I’ll be presenting our work on Local Graph Clustering with Noisy Labels tomorrow at 9:20 AM EDT at the Fields Institute. Hope to see you there :)
https://t.co/hzXIlTyKWt
@PIBHomeAffairs@narendramodi@AmitShah Thanks for the great initiative! But unfortunately, it doesn't work for me currently. My Indian passport has a Canadian address (enforced by the Indian consulate) and the portal allows only Indian addresses.
Paper: Simulation of Graph Algorithms with Looped Transformers (revised version @icmlconf)
+ Multi-tasking (Remark 6.5)
+ Discussion on the role of ill-conditioning for the ability of Transformers to simulate algorithms.
Link: https://t.co/vPqqIKPPG5
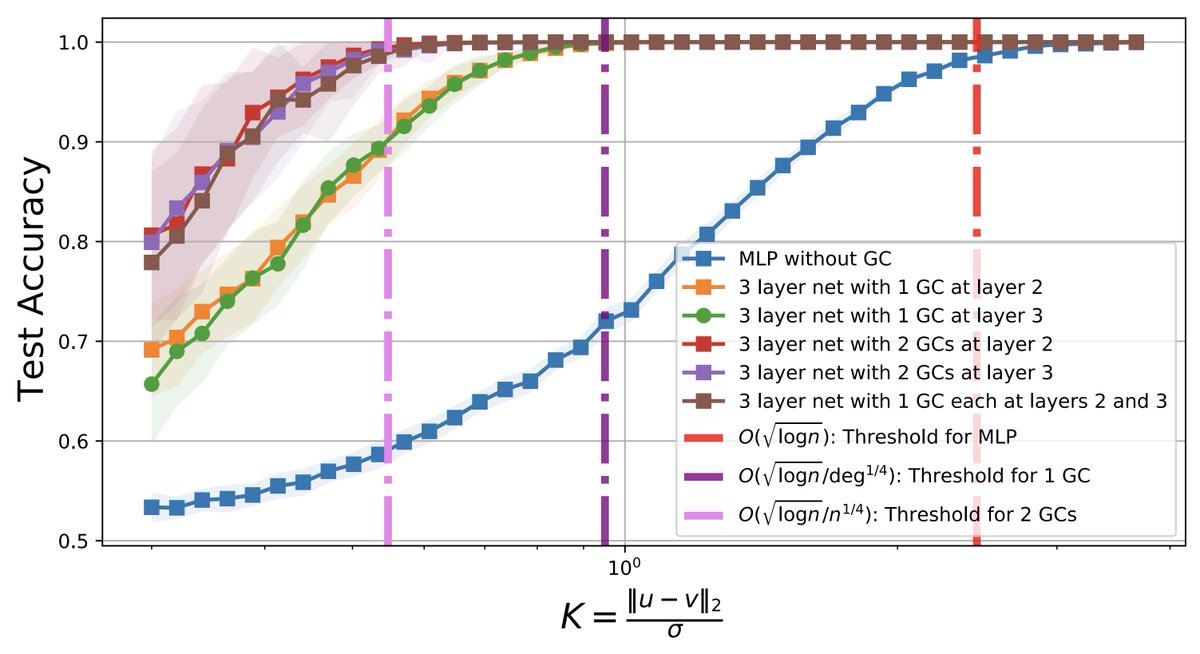
Paper: Analysis of Corrected Graph Convolutions
We study the performance of a vanilla graph convolution from which we remove the principal eigenvector to avoid oversmoothing.
1) We perform a spectral analysis for k rounds of corrected graph convolutions, and we provide results for partial and exact classification.
2) For partial classification, we show that each round of convolution can reduce the misclassification error exponentially up to a saturation level, after which performance does not worsen.
3) For exact classification, we show that the separability threshold can be improved exponentially up to O(log n/log log n) corrected convolutions.
link: https://t.co/8Mb1ZbBKun
P.S.: That's the first paper produced as part of the graduate course (CS886, 2024) on graph neural networks that I am teaching!