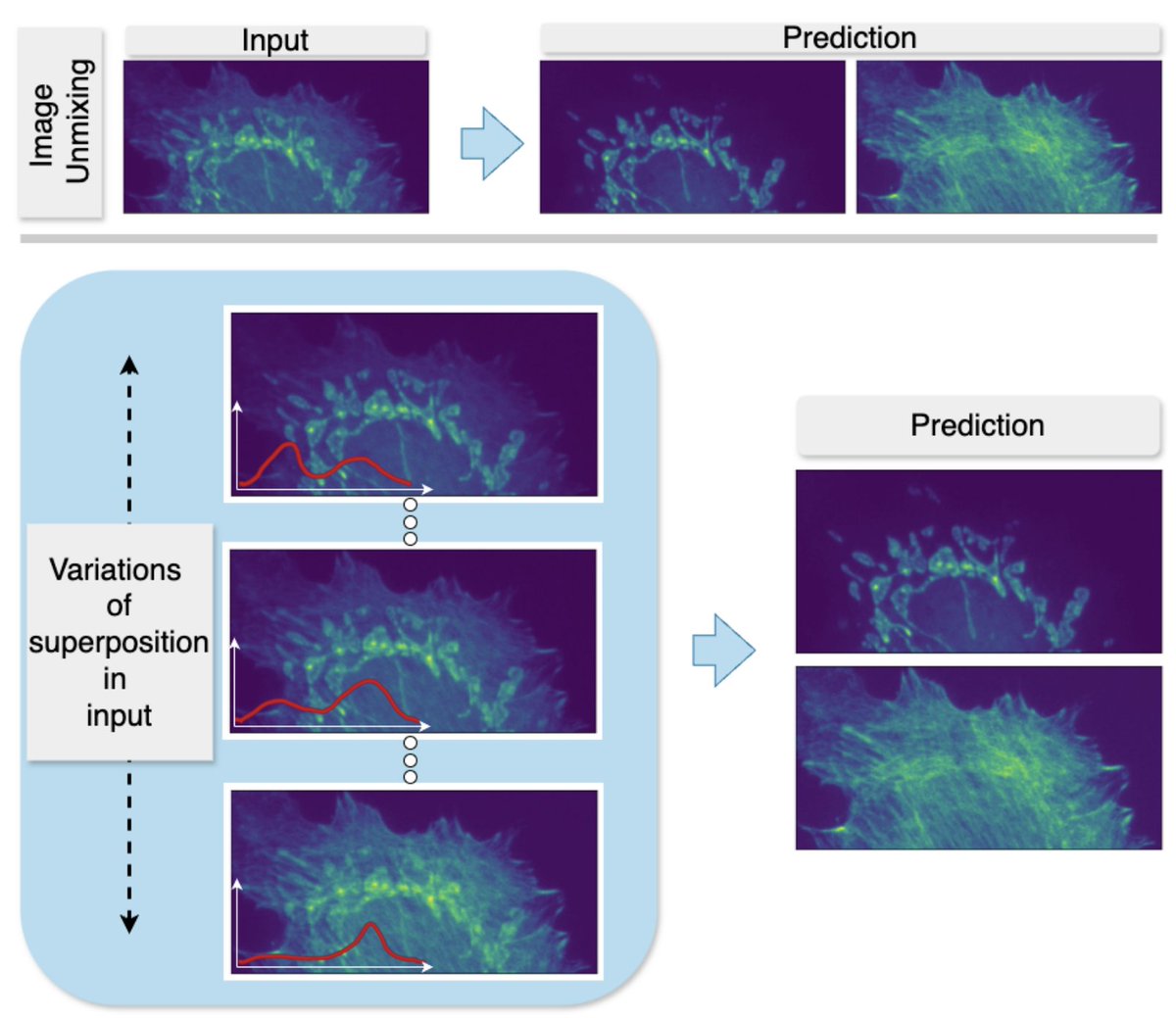
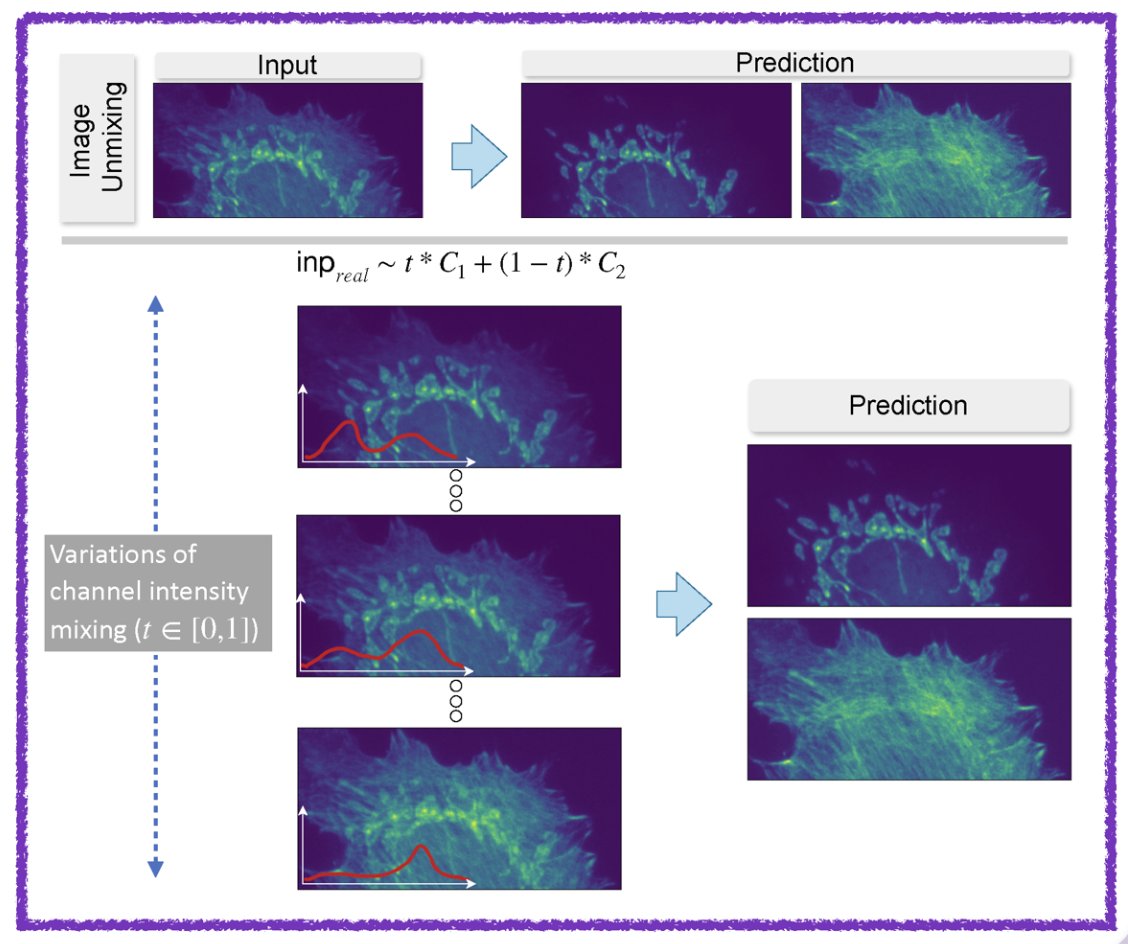
Our work on generalizing across variations in the strength of structures within superimposed images—an issue relevant for semantic unmixing and bleed-through removal in fluorescence microscopy—has been accepted at NeurIPS 2025! (https://t.co/6SQRjic7AV) @florianjug
A 19-year old broke into India's largest high school examination system of 2M+ students a year, the CBSE, and was able to view and CHANGE any students' marks.
He responsibly wrote to the team 3 months ago, and it took them 3 days to fix only one of the issues. Today, they took the entire website down.
This is a absolute embarrassment. The futures and lives of millions rests in the hands of the utterly incompetent. There is also no mass media reporting on the matter.
This topic is close to me because not only is this the education system I went through, but 12 years ago and silently for 5yrs since, I'd written about and reported a much less severe vulnerability allowing me to scrape these results too. More than a decade later, not much has changed.
This 19yo, Nisarga Adhikary, wrote a great piece outlining each vulnerability he reverse engineered:
- the master password leak
- the client-side 2fac / OTP validation workaround
- tokenless access to the entire internal app (dashboard, evaluator details, etc) setting dummy browser values
- changing any password without knowing the old one
- an IDOR vuln allowing you to act as any user and edit exam marks
For those interested in a beautiful study in security breaches, this is a must read (link below).
If there's any light at the end of the tunnel, it's that a 19yo who never went to college can do things 99% of top engineers couldn't figure out.
The last work of my PhD is finally out :). A big thanks to all authors, and especially to my PhD supervisor @florianjug! Hope to do similar quality work in India in the future ☀️.
MicroSplit: a computational unmixing method for multiplexed fluorescence imaging of up to 4 structures per imaging channel. @ashesh0@florianjug
https://t.co/HoWuCBuqaR
Happy to share that our lab has been awarded with the @ANRFIndia–Prime Minister Early Career Research Grant (PMECRG). Looking forward to making significant advancements in AL amyloidosis research🎊👏 @IISERPune @PMECRG
YIM 2026 is just 3 days away — and as we count down, here’s an inspiring #JOYI2026 story.
From a remote village in Haryana to leading a lab at @IISERPune — @Saritapuri24’s journey to science was anything but conventional. With no academic role models growing up, she built her path through persistence, mentorship, and self-belief. #JOYI2026
Read 👉 https://t.co/uQ0XDDyFzB
@LaStatale@IBCSinica@IITDelhi
YIM 2026 is just 3 days away — and as we count down, here’s an inspiring #JOYI2026 story.
From a remote village in Haryana to leading a lab at @IISERPune — @Saritapuri24’s journey to science was anything but conventional. With no academic role models growing up, she built her path through persistence, mentorship, and self-belief. #JOYI2026
Read 👉 https://t.co/uQ0XDDyFzB
@LaStatale@IBCSinica@IITDelhi
We are thrilled to share significant progress on our ambitious Artificial Intelligence (AI) and Large Language Model (LLM) development program for Sanskrit, which was officially inaugurated on Vijayadasami day this year.
The Core Mission and Team
A dedicated core group of professionals spanning IT, Data Science, and Sanskrit Studies is driving this effort to create the country's first truly capable Sanskrit LLM. Our foundational strategy is centered on developing a comprehensive, high-quality Sanskrit corpus.
Massive Data Corpus Development
Our initial focus has been on leveraging our institutional assets. Our combined libraries (College and KSRI) hold over 110,000 texts, scriptures (Śāstras), and several thousand manuscripts.
Initial Focus: We commenced the digitization process by converting scanned images of rare books and manuscripts into digital text.
Technological Breakthrough: Our in-house scholars successfully developed proprietary software to automate the conversion of PDF image data into editable text.
Proof of Concept Success: We successfully converted 180 volumes of the now discontinued 'Chandamama' magazine in Sanskrit, proving the efficiency of our automated workflow.
Scaling Up: Building on this success, we rapidly converted over 1,000 books into text in less than 24 hours, dramatically accelerating the corpus creation phase.
The Path Ahead: Curation and Modeling
We are now moving into the crucial validation and modeling stages:
Data Curation & Quality Control: We are actively recruiting part-time Sanskrit scholars to meticulously edit and curate the newly converted texts, ensuring accuracy and correcting any errors generated during the automated process. This step is vital for the model's performance.
Next Phase: The curated and verified data will then be prepared—through tokenization—and fed into our proprietary AI model for training.
🤝 Join Us in Making History
This is a massive, pioneering effort, and we invite skilled individuals to contribute. If you have expertise in Sanskrit, Linguistics, and/or Data Science, we welcome you to join our team.
DM us today to become part of this unique exercise. Together, we aim to make history by developing the first comprehensive AI-LLM for Sanskrit in the country, unlocking the potential of this ancient language for the digital age.
@dpradhanbjp@SanjeevSanskrit@MaharishiAazaad@sain57356@SanskritChannel
#SanskritDiwas
@davidfrawleyved@sanskritiias@TheSanskriti_@kalyan97@annamalai_k@yajnadevam@Rtam86418021@SanjeevSanskrit@Kar_Sas123@subhash_kak@AGeorge56445@AkhilKumarSaho8@vikramsampath@DeepakChopra@jsaideepak@itisatp@BjpSashi@PMOIndia@DrManishKumar1@ARanganathan72@sanjeevsanyal@kalyan97@dushyanthsridar@RajVedam1@mmpandit@periyanatt96807@Ugrashravas
ResMatching accepted to @IeeeIsbi 2025🎉. We extend Guided CFM to Computational Super-Resolution under extreme noise, achieving SOTA performance and calibrated posterior sampling that reflects uncertainty in real data. Learn more here: https://t.co/cIHcC3Nm66 #ISBI2026
🔬 🖥️ Applications are open for the CSHL course Quantitative Imaging: From Acquisition to Analysis (April 6–21, 2026)!
An intensive, hands-on course covering advanced fluorescence microscopy and quantitative image analysis using open-source tools.
🗓️ Apply online by Jan 30, 2026
https://t.co/SwYt1yGtHv
Thanks @Biopatrika for highlighting our recent publication in Journal of Molecular Biology. Kudos to my Students Sharvari Palkar, Ishaan Chaudhary, Basudha Patel and our collaborator Amit Kumawat and @asibc512. Also, thanks to @IISERPune for infrastructure!
Excited to share that I’ll be at #NeurIPS2025 in Mexico next week! 🎉
📢 I’ll be presenting our paper here: https://t.co/qZpqkWJ2Fo
🚀 Interested in Computer Vision applied to Biological/Biomedical data? Let's meet!
Great opportunity! Please apply for a Jan 2026 PhD intake at Biology Department @IISERPune. Scan the QR code or visit departmental website https://t.co/se3KyebTbB for more details!
I am happy to share our recently accepted article in the Journal of Molecular Biology (https://t.co/tNFpAgAHeL), where we identified unique aggregation hotspots and early events of aggregation in the highly amyloidogenic light chain AL55.