Hermes Agent now has multi-agent via the Kanban, new in v0.12.0.
Agents claim tasks from a board, work in parallel, and hand off when blocked. You watch progress and unblock from one easy view instead of juggling terminals.
We asked it to plan and make this video about itself:
Been building in stealth mode. Today that ends - going public with @colosseum Frontier.
Obsessed with one idea - markets surface truth better than any media.
So I set out to build around this core idea. Hit every wall.
Winnr is what happens when you build through them. 🧵
hosting an invite-only live show where founders pitch a panel of angels while the audience invests in real time. all on the internet.
looking for 3 founders that want to raise <$25K for consumer apps, weird tools or early MVPs.
ping me.
Every claim should have skin in the game. Those selling fake news should pay. Charlatans should get arbitraged.
Introducing the new Precog.
A fully onchain prediction market protocol. Built for signal.
Here's what's new 🧵👇
The last few days have been wild.
Here's what we've shipped over the weekend.
But first, we're giving away free Nous Portal subscriptions to the first 250 people who claim code AGENTHERMES01 at https://t.co/uomohWX1dw - and there's a lot of exciting new stuff to use it on:
-> Pokemon Player 🎮
Hermes can now play Pokemon Red/FireRed autonomously via headless emulation. The new pokemon-agent package (https://t.co/SefIfSFMBP) and built-in skill provides a REST API game server, and Hermes drives it through its native tools - reading game state from RAM, making strategic battle decisions, navigating the overworld, and saving progress to memory across sessions. It just plays Pokemon. From your terminal. No display server needed.
-> Self-Evolution 🧬
We shipped hermes-agent-self-evolution (https://t.co/9xlrFXTgPQ) and an optional skill - an evolutionary self-improvement system that uses DSPy + GEPA to optimize Hermes's own skills, prompts, and code. It maintains populations of solutions, applies LLM-driven mutations targeted at specific failure cases, and selects based on fitness. Inspired by Imbue's Darwinian Evolver research that achieved 95.1% on ARC-AGI-2.
-> OBLITERATUS 🔓
The abliteration skill got a major update. Hermes can now uncensor any open-weight LLM (Llama, Qwen, Mistral, etc.) by surgically removing refusal directions from model weights - 9 CLI methods, 116 model presets, tournament evaluation. Just say "abliterate this model" and it handles the rest.
-> Signal, iMessage + 7-Platform Gateway 📱
Hermes now runs on iMessage and Signal alongside Telegram, Discord, WhatsApp, Slack, and CLI. Full feature parity: voice messages, image handling, DM pairing. Your agent is reachable everywhere.
-> Automatic Provider Failover 🔄
When your primary model goes down (rate limits, outages), Hermes now automatically switches to a configured fallback model. Supports all providers including Codex OAuth and Nous Portal. One line of config, zero downtime.
-> Secret Redaction Everywhere 🔒
All tool outputs now redact API keys, tokens, and passwords before they reach the LLM. 22+ patterns covering AWS, Stripe, HuggingFace, GitHub, SSH private keys, database connection strings, and more. Your secrets never leak into context.
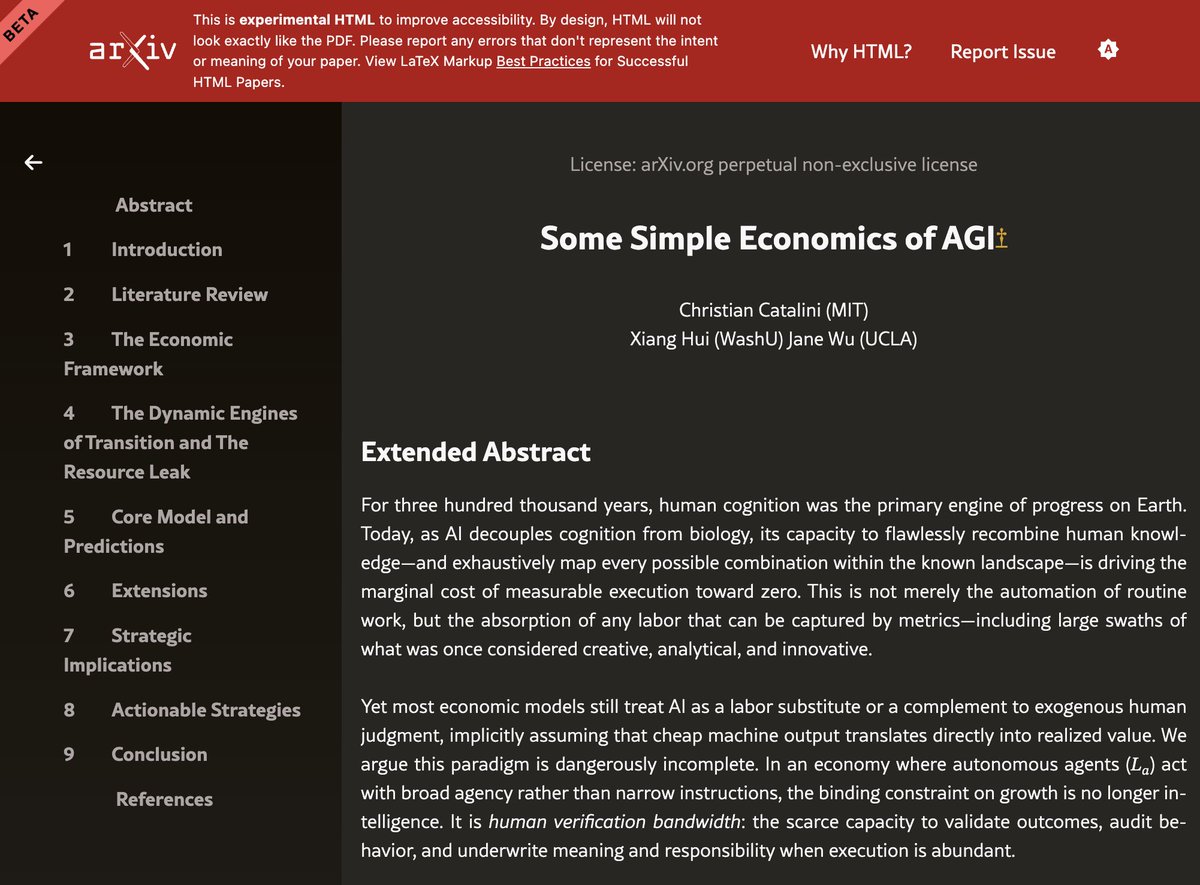
1/ Some Simple Economics of AGI—🔥🧵
Right now, there is a low-grade panic running through the economy. Everyone is asking the same anxious question: what exactly is AI going to automate, and what will be left for us?
encrypt V2 is LIVE!
Private bridging across 6 chains — Solana, Polygon, BNB Chain, Base, Arbitrum & Ethereum.
✔ No wallet connection
✔ No wrapping or shielding
✔ Under 2min execution
✔ Lower fees vs Houdini/ChangeNow
Powered by @near_intents ⚡️
Try it 👇
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
yes things are changing fast, but also I see companies (even faang) way behind the frontier for no reason.
you are guaranteed to lose if you fall behind.
the no unforced-errors ai leader playbook:
For your team:
- use coding agents. give all engineers their pick of harnesses, models, background agents: Claude code, Cursor, Devin, with closed/open models. Hearing Meta engineers are forced to use Llama 4. Opus 4.5 is the baseline now.
- give your agents tools to ALL dev tooling: Linear, GitHub, Datadog, Sentry, any Internal tooling. If agents are being held back because of lack of context that’s your fault.
- invest in your codebase specific agent docs. stop saying “doesn’t do X well”. If that’s an issue, try better prompting, https://t.co/SOjpn47yxo, linting, and code rules. Tell it how you want things. Every manual edit you make is an opportunity for https://t.co/S1ZvtYQwta improvement
- invest in robust background agent infra - get a full development stack working on VM/sandboxes. yes it’s hard to set up but it will be worth it, your engineers can run multiple in parallel. Code review will be the bottleneck soon.
- figure out security issues. stop being risk averse and do what is needed to unblock access to tools.
in your product:
- always use the latest generation models in your features (move things off of last gen models asap, unless robust evals indicate otherwise). Requires changes every 1-2 weeks - eg: GitHub copilot mobile still offers code review with gpt 4.1 and Sonnet 3.5 @jaredpalmer. You are leaving money on the table by being on Sonnet 4, or gpt 4o
- Use embedding semantic search instead of fuzzy search. Any general embedding model will do better than Levenshtein / fuzzy heuristics.
- leave no form unfilled. use structured outputs and whatever context you have on the user to do a best-effort pre-fill
- allow unstructured inputs on all product surfaces - must accept freeform text and documents. Forms are dead.
- custom finetuning is dead. Stop wasting time on it. Frontier is moving too fast to invest 8 weeks into finetuning. Costs are dropping too quickly for price to matter. Better prompting will take you very far and this will only become more true as instruction following improves
- build evals to make quick model-upgrade decisions. they don’t need to be perfect but at least need to allow you to compare models relative to each other. most decisions become clear on a Pareto cost vs benchmark perf plot
- encourage all engineers to build with ai: build primitives to call models from all code bases / models: structured output, semantic similarity endpoints, sandbox code execution. etc
What else am I missing?
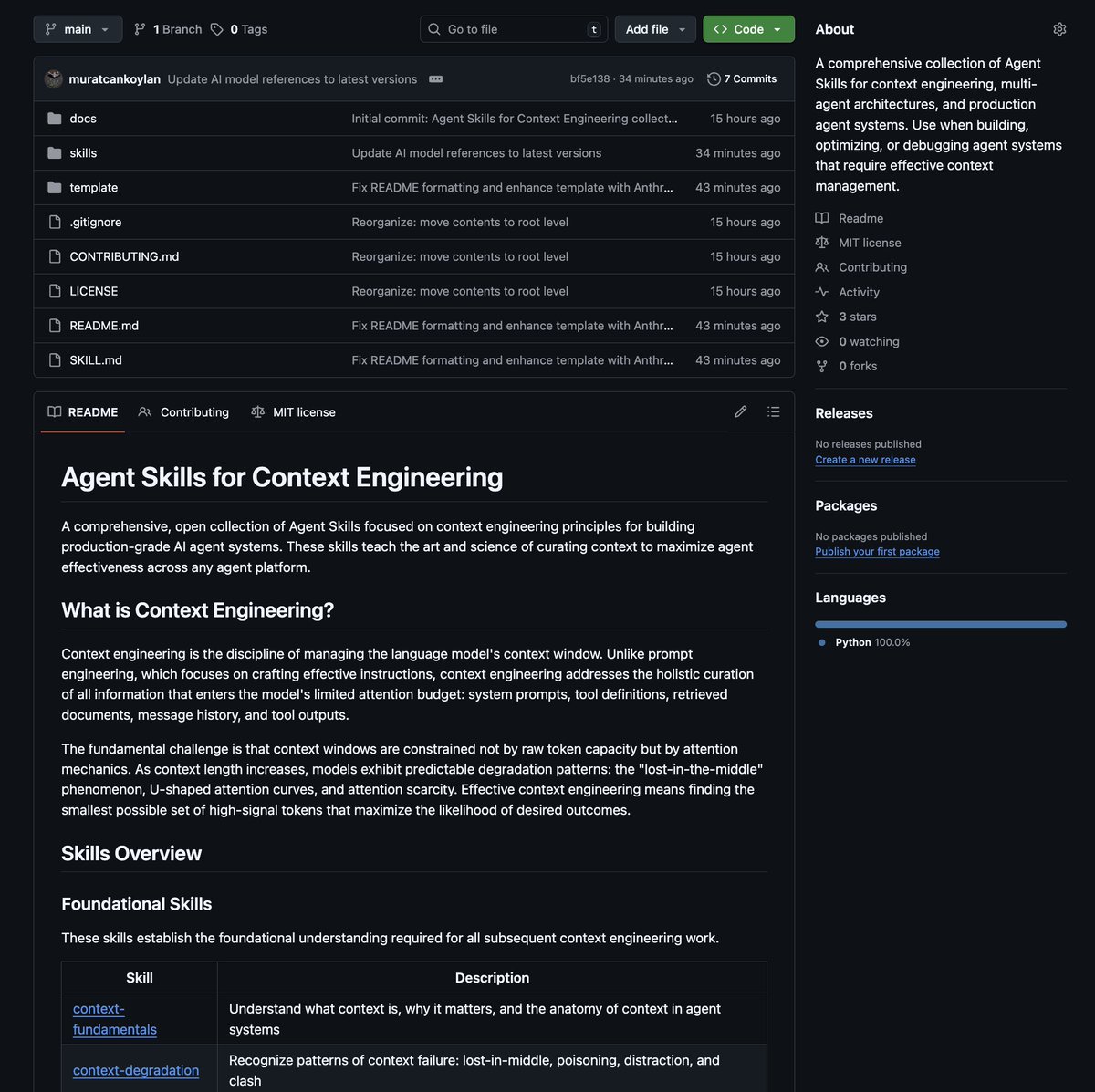
I’m excited to share a new repo: Agent Skills for Context Engineering
Instead of just offering a library of black-box tools, it acts as a "Meta-Agent" knowledge base. It provides a standard set of skills, written in markdown and code, that you can feed to an agent so it understands how to manage its own cognitive resources.
https://t.co/vWwrYPAd8k
Most agent failures are not model failures; they are context failures. This is still an experimental project. The goal is to establish a platform-agnostic standard for context engineering that can be used in Cursor, Claude Code, Copilot or Codex.
skills/
context-fundamentals: What context is, why it matters
context-degradation: How context fails (lost-in-middle, poisoning)
context-optimization: Compaction, masking, caching
multi-agent-patterns: Orchestrator, swarm, hierarchical
memory-systems: Vector RAG, knowledge graphs, Zep
tool-design: Building tools agents can use
evaluation: Testing and measuring agent systems
I believe this is a good start, showing developers how to approach context engineering rather than relying on ready-made tools.
You will also find the aggregated research documents I used to build these skills in the repo. The skills are synthesized from technical blogs on context and prompt engineering that I bookmarked, AI Labs' documentations, and Anthropic Skills examples.
Try the 7 Skills, created using Antrhopic's Skills template format. Experiment with the provided scripts and references, and feel free to contribute to the repo.
Hey twitter!
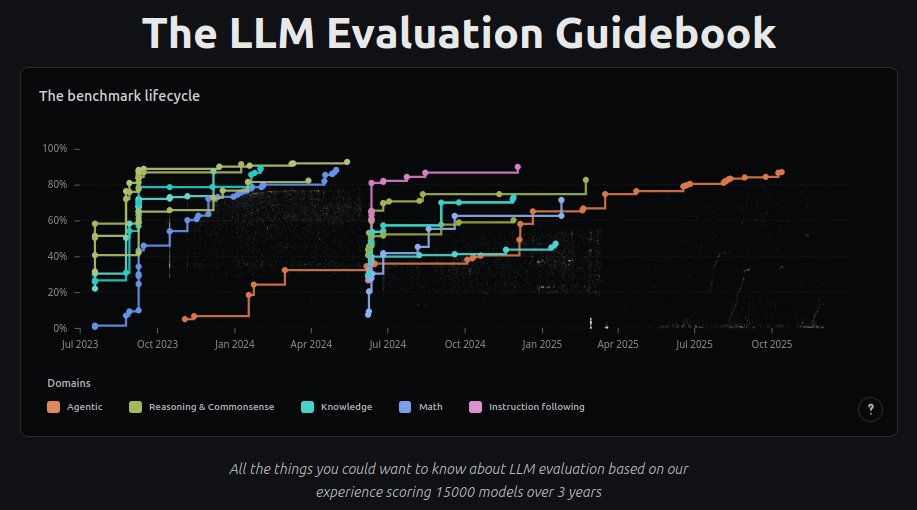
I'm releasing the LLM Evaluation Guidebook v2!
Updated, nicer to read, interactive graphics, etc!
https://t.co/xG4VQOj2wN
After this, I'm off: I'm taking a sabbatical to go hike with my dogs :D
(back @huggingface in Dec *2026*)
See you all next year!
Introducing WarpGrep, a fast context subagent that improves coding agent performance.
WarpGrep speeds up coding tasks 40% and reduces context rot by 70% on long horizon tasks by treating context retrieval as its own RL trained system.
Inspired by Cognition’s SWE-Grep - we’re opening access to Claude Code, Codex, OpenCode or any coding agent via MCP (or through our SDK)