I don’t want to provide my world-class expertise just for you to hoard crowd-sourced prompts and construct elaborate security theater performances to appease investors who are foolish enough to believe guardrails=safety.
I’m allergic to money, so don’t bother. My incentives are aligned with what’s best for the community and the future of AI.
Are yours?
Facts as AI Videos ? (Fully AI Generated)
- Archaeologists have found edible honey in ancient Egyptian tombs thousands of years old.
- The record for the longest flight by a chicken is 13 seconds, highlighting nature’s unexpected quirks.
Should we do more of those at @adhdl4b
【🤔 大規模言���モデルの思考不足とは?Tencent AI Labの最新論文を解説!】
✎. FYIG: https://t.co/PcEX7if9gC
Tencent AI Lab、Soochow University、Shanghai Jiao Tong Universityの研究者らが発表した最新論文「Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs」は、大規模言語モデル(LLM)の興味深い問題を指摘しています!😮
💡 この論文では、o1のようなLLM、例えばQwQ-32B-PreviewやDeepSeek-R1-671Bにおいて、「思考不足」という問題が起きているとのことです。具体的には、不正解の回答が正解よりも頻繁に推論を切り替えてしまい、結果として精度が向上せずに応答が長くなってしまう現象を指しています。
📊 添付の画像をご覧ください!AIME2024テストセットを用いた実験結果が示されています。
(a) Qwen-Math-72B、Llama3.3-70B、QwQ-32B-Preview、DeepSeek-R1-671Bの4モデルにおける生成トークン数の比較。
(b) QwQ-32B-PreviewとDeepSeek-R1-671Bの2モデルにおける思考数の比較。
緑色のバーが正解、赤色のバーが不正解です。o1のようなモデルでは、不正解の回答が正解よりも頻繁に推論を切り替えていることがわかります!
🔍 一方、Qwen-Math-72BやLlama3.3-70Bのような従来のLLMでは、不正解と正解の応答長に有意な差は見られませんでした。
✨ この研究は、LLMの思考プロセスに関する新しい洞察を提供し、今後の発展に役立つ可能性があります。
論文の詳細は、こちらをご覧ください!
https://t.co/tOAxNvruSG
@OfficialLoganK In my experience sadly, it failed in tasks R1 and O1 did seamlessly. Talking about complex coding tasks. I understand that it’s fast and all, works well with Cline and code editing. But fails in complex coding tasks.
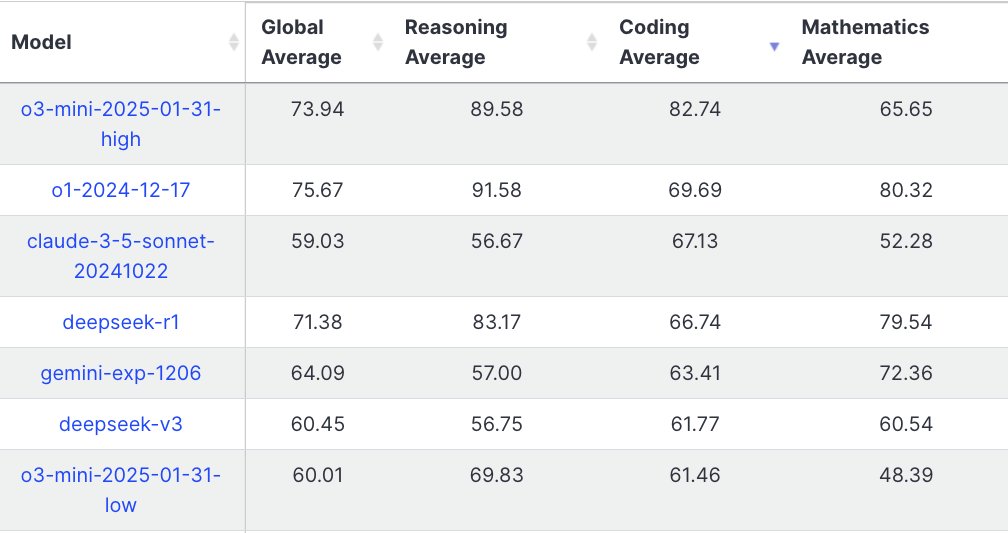
o3 BEATS R1 OVERALL AND BLOWS EVERYONE ELSE AWAY IN CODING
o3-mini high became the BEST LLM BY FAR when it comes to a combination of performance, speed, and price
- beats o1, Sonnet, and others BY A LOT in coding
- 2x cheaper than Sonnet and 15x cheaper than o1
- ~5x faster than R1
- 2nd best model right after o1 in all categories
ChatLLM and CodeLLM now have o3-high if you want to play with it.
@dylhunn I know we’re speaking of exceptional speed in terms of generating responses - will there be a comparison with latest reasoning models as well ? How does it compare to DeepSeek R1 (pure performance not speed).
The next big question is will @Google Gemini 2.0 Pro or @X Grok 3 outperform DeepSeek v3 or R1 ? Time will tell.
Let’s not forget that @Alibaba_Qwen also put out a great model last night which isn’t getting as much attention yet.
🎉 恭喜发财🧧🐍 As we welcome the Chinese New Year, we're thrilled to announce the launch of Qwen2.5-VL , our latest flagship vision-language model! 🚀
💗 Qwen Chat: https://t.co/BhhXyzLt5B
📖 Blog: https://t.co/ZOf5RUXlNd
🤗 Hugging Face: https://t.co/0Eoainjqun
🤖 ModelScope: https://t.co/uTdFixhtsD
🌟 Key Highlights:
* Visual Understanding : From flowers to complex charts, Qwen2.5-VL sees it all!
* Agentic Capabilities : It’s a visual agent that can reason and interact with tools like computers & phones.
* Long Video Comprehension : Captures events in videos over 1 hour long! ⏳🎥
* Precise Localization : Generates bounding boxes & JSON outputs for accurate object detection.
* Structured Data Outputs : Perfect for finance & commerce, handling invoices, forms & more! 💼📊
Try Qwen2.5-VL now at Qwen Chat or explore models on Hugging Face & ModelScope . 🌐
@minchoi@tajb03 When it comes to generation yes it’s not that great. It does okay. Definitely not better than DALLE 3 or Flux it comes to visual preference ( rather than metrics ).
There’s a lot of misconception that China “just cloned” the outputs of openai. This is far from true and reflects incomplete understanding of how these models are trained in the first place. DeepSeek R1 has figured out RL finetuning. They wrote a whole paper on this topic called DeepSeek R1 Zero, where no SFT was used. And then combined it with some SFT to add domain knowledge with good rejection sampling (aka filtering). The main reason it’s so good is it learned reasoning from scratch rather than imitating other humans or models.
Watching non-AI experts confidently discuss @deepseek_ai without understanding the basics is both hilarious and frustrating. The internet never disappoints. Or it always does. 💀