Introducing chartli 📊
CLI that turns plain numbers into terminal charts. ascii, spark, bars, columns, heatmap, unicode, braille, svg.
$ 𝚗𝚙𝚡 𝚌𝚑𝚊𝚛𝚝𝚕𝚒
I wanted terminal charts with zero setup. No browser, no Python env, no matplotlib. Pipe numbers in, get a chart out.
Again built using Command Code with my CLI taste.
$ npx chartli data.txt -t ascii -w 24 -h 8
8 chart types spanning a fun range of Unicode density:
- ascii (line charts with ○◇◆● markers)
- spark (▁▂▃▄▅▆▇█ sparklines, one row per series)
- bars (horizontal, ░▒▓█ shading per series)
- columns (vertical grouped bars)
- heatmap (2D grid, ░▒▓█ intensity mapping)
- unicode (grouped bars with ▁▂▃▄▅▆▇█ sub-cell resolution)
- braille (⠁⠂⠃ 2×4 dot matrix, highest density)
- svg (vector output, circles or polylines)
Input format is dead simple: rows of space-separated numbers. Multiple columns = multiple series.
0.0 0.1 0.1 0.1
0.2 0.4 0.2 0.4
0.3 0.2 0.4 0.2
Composes with pipes:
$ cat metrics.txt | chartli -t spark
S1 ▁▂▃▄▅▆
S2 ▁▄▂▇▅█
S3 ▁▂▄▃▆▅
S4 ▁▄▂▇▂▇
The braille renderer is my fav. Each braille character encodes a 2×4 dot grid, so a 16-wide chart gives you 32 pixels of horizontal resolution. Free anti-aliasing from Unicode.
The bars renderer uses 4 shading levels (░▒▓█) to visually separate series without color. Works on any terminal, any font.
Heatmap maps values to a 5-step intensity scale across a row×column grid, so you can spot patterns in tabular data at a glance.
SVG mode has 2 render paths: circles (scatter plot) and lines (polylines). Output is valid XML you can pipe straight to a file or into another tool.
Zero config by default, every dimension overridable (-w width, -h height, -m SVG mode).
No config files.
No themes.
No dashboards.
$ 𝚗𝚙𝚡 𝚌𝚑𝚊𝚛𝚝𝚕𝚒
Or global install it.
$ npm i -g chartli
# Skill for your agents
$ npx skills add ahmadawais/chartli
If you work in terminals and want quick data visualization without leaving your workflow, try it.
⌘ let's go!!
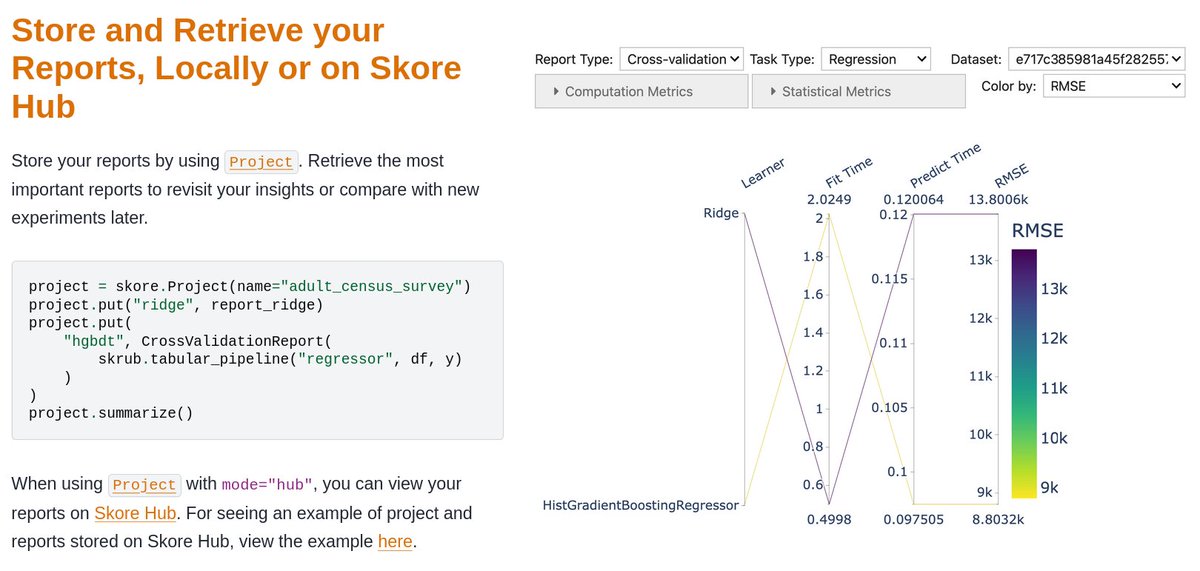
At probabl, we're focused on improving the data-science stack.
We just made public the skore platform, augmenting the open-source library.
Our dream is that, with skore, a data scientist will not feel overwhelmed by the iterative process of data science, but empowered
Today's blog discusses how to project a neural network's (high-dim) loss landscape to 2D, while preserving local information, so that the "a ball rolling down a hill" picture is realistic and insightful -- we can clearly see why/when stick plateaus happen
https://t.co/9BlKhkk16h
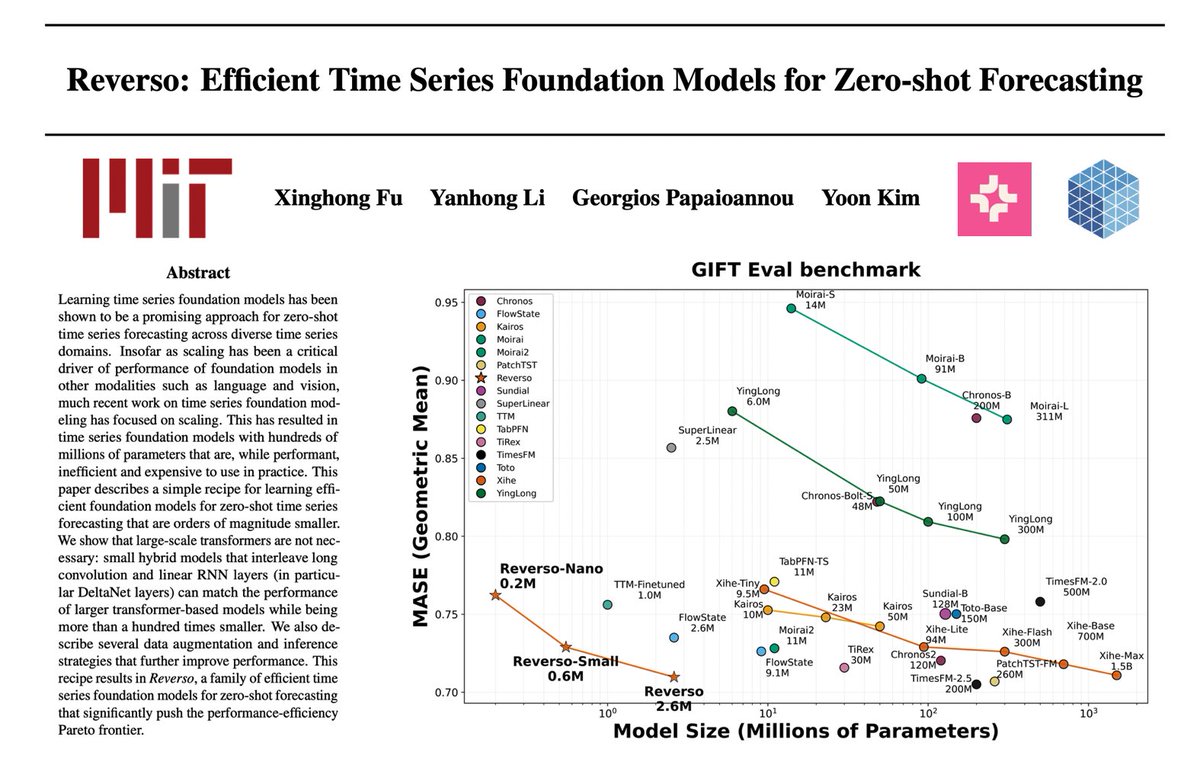
Do we really need billion-parameter transformers for time series forecasting?
What if we did it in under 3M parameters?
Introducing Reverso: time series foundation models as small as 200K paramters significantly pushing the Pareto frontier in zero-shot time series forecasting!
Google just released TimesFM (a Time Series Foundation Model) - a 200M-parameter model that can forecast time-series data it has never seen before, with no additional fine-tuning required.
Time-series forecasting is required everywhere - retail, finance, healthcare, etc. And for the longest time, this was the domain of traditional statistical methods. Then deep learning models came along and did better, but they involved long training and validation cycles before you could even test them on new data.
TimesFM changes this. All we need to do is point it at a new dataset, and it gives you a solid forecast immediately - zero-shot.
The architecture is decoder-only, the same idea as GPT. Instead of words, it works with "patches" - groups of contiguous time-points treated as tokens. The model predicts the next patch from all the ones before it.
The model was pre-trained on 100 billion real-world time-points, mostly from Google Trends and Wikipedia Pageviews - which naturally capture a huge variety of patterns across domains.
On benchmarks, zero-shot TimesFM matches PatchTST and DeepAR that were explicitly trained on those datasets, and even beats GPT-3.5 on forecasting tasks despite being far smaller.
The model is open on HuggingFace and GitHub if you want to try it.
fff.nvim is the fastest file search on a planet
here is a live demo showing out 18x performance gain over ripgrep on skia repo and this is not even the largest gain I've seen + it's using a really unoptimal bun javascript cli lol
Thanks for hosting us, @askalphaxiv!
Get started with computing your own embeddings:
Example molab notebooks: https://t.co/9RJ18M6msr
Paper: https://t.co/dOSXaJIjYV
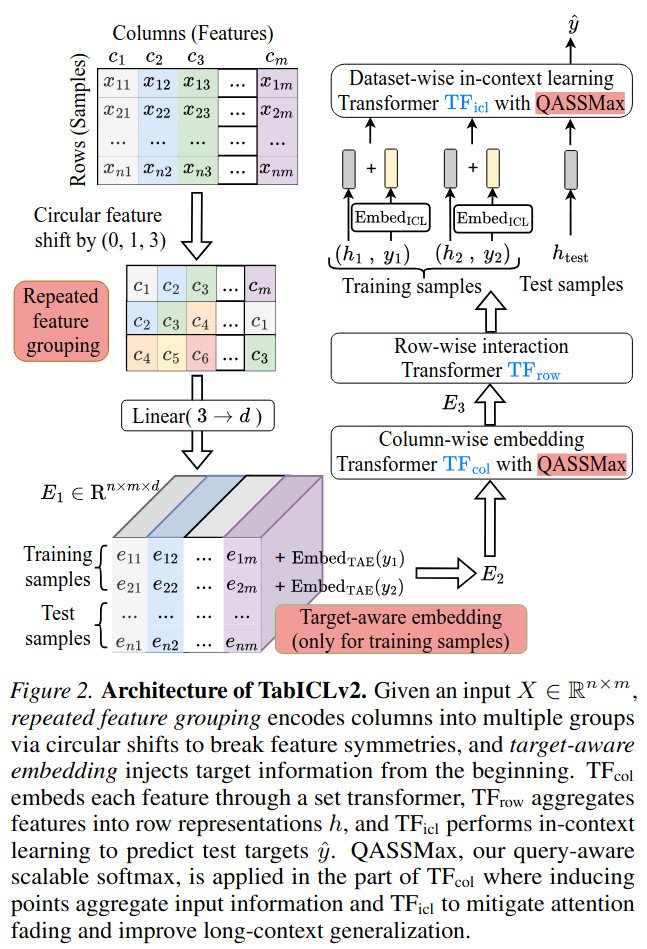
🎉 Announcing TabICLv2: State-of-the art Table Foundation Model, fast and open source
A breakthrough for tabular ML: better prediction and faster runtime than alternatives, work by @JingangQu, @DHolzmueller, @MarineLeMorvan, and myself 👇
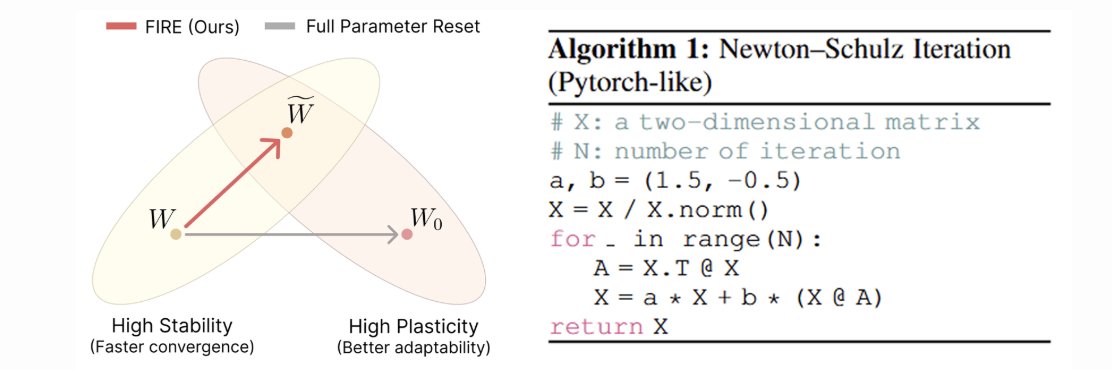
🔥Introducing FIRE (ICLR'26 Oral) -- a principled way to reinitialize neural nets so they keep learning on nonstationary / expanding data without wiping useful knowledge.
Project page: https://t.co/056w3wJKE5
Uncomfortable question for AI folks:
In self-supervised learning, does lower validation/test loss really mean better representations?
Our solvable model suggests: not always.
https://t.co/HVpiXLCCIG
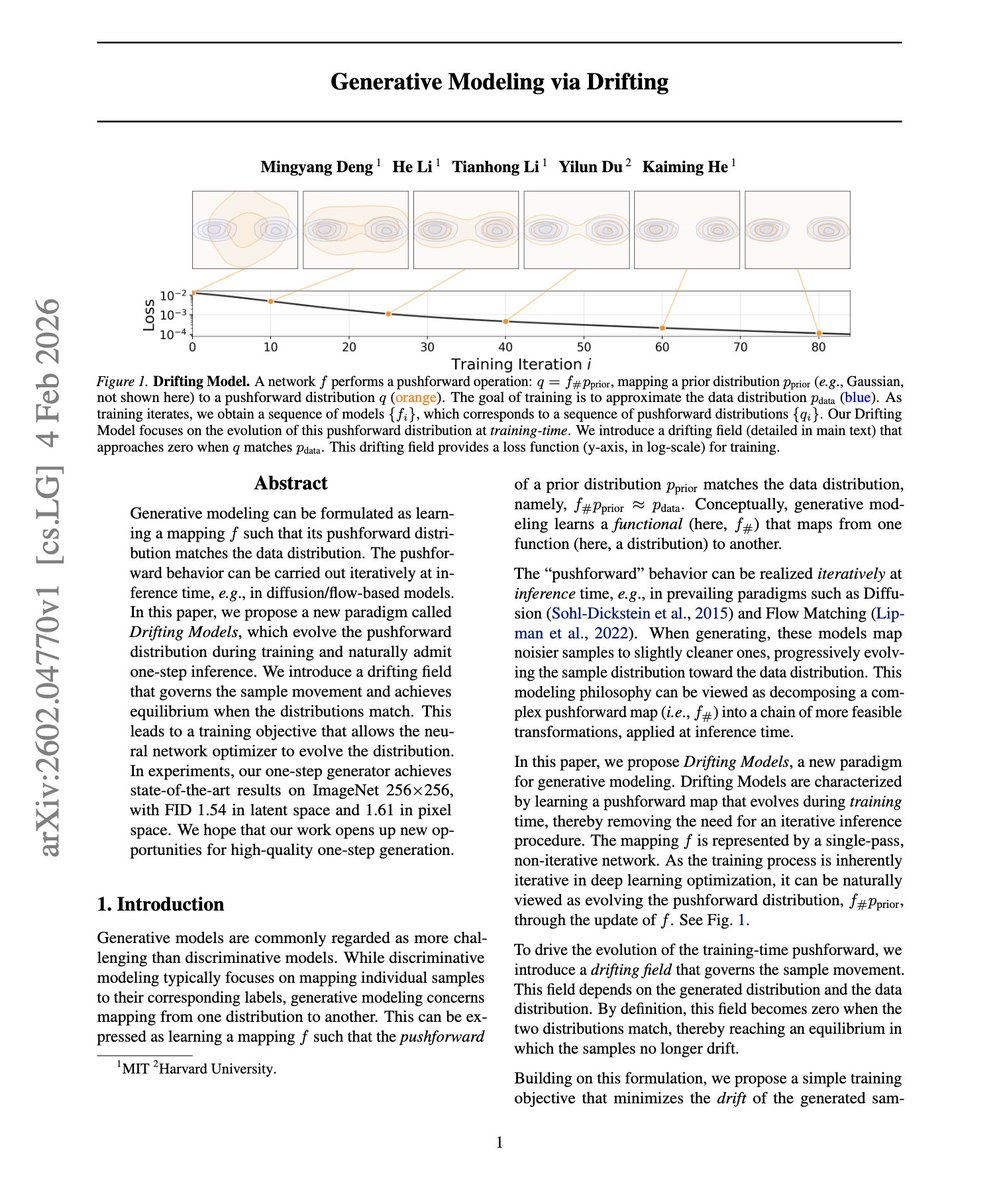
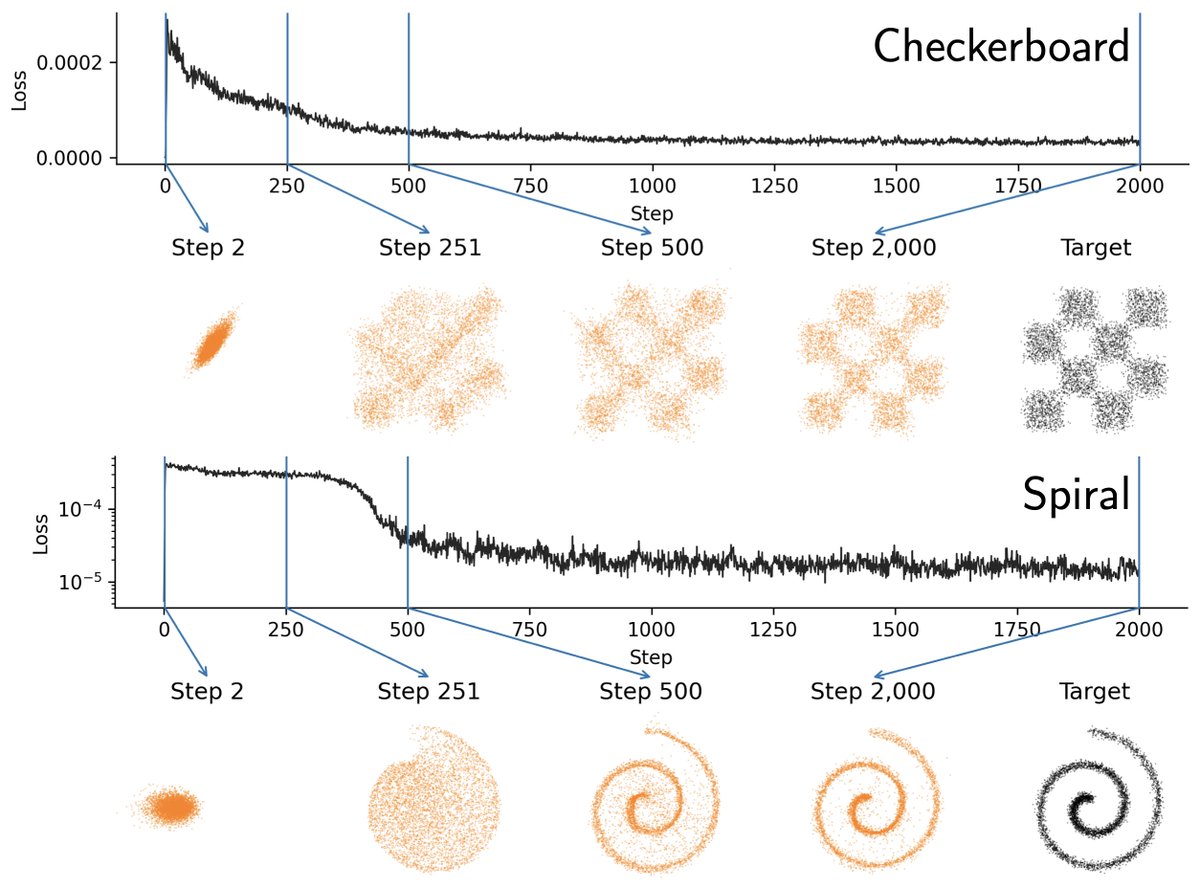
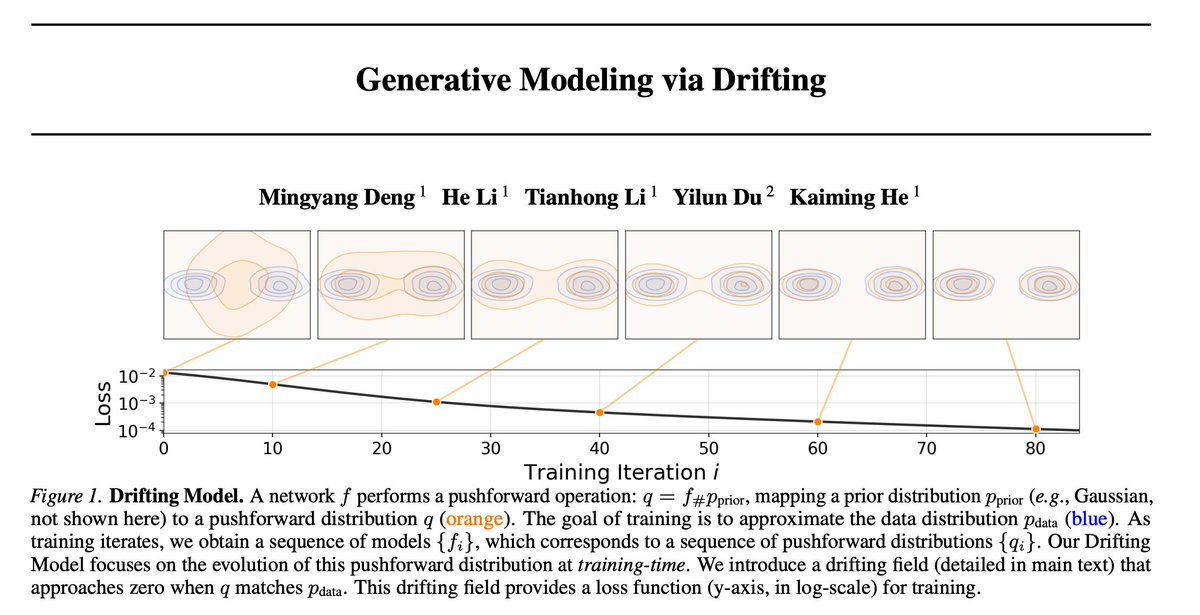
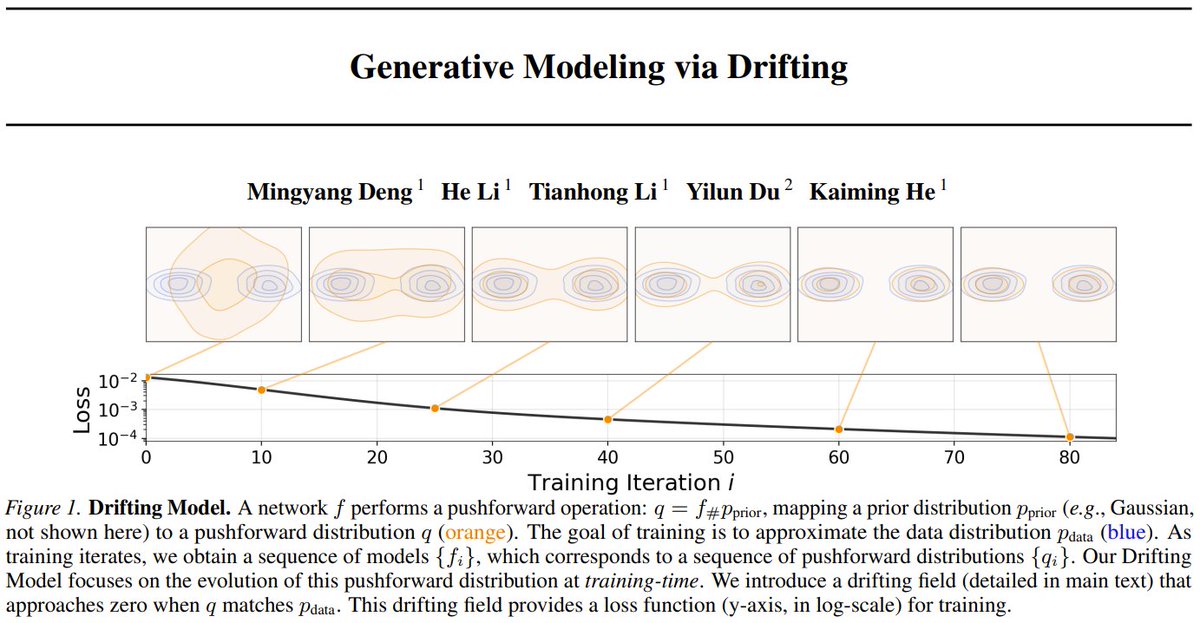
New generative model paradigm: Drifting Models
1 step inference but at SoTA fidelity!
Think of this as diffusion, but the steps happen in training instead of at sampling time. During training, they define a drifting field that tells how a generated point should move given real data samples and current generated samples.
The training process is basically:
1. Make a fake sample
2. Which way should this image move?
3. Train the model to jump there in one go
4. Stop when there’s nothing left to fix
So at test time you don't need to do many refinement steps as the model has already learned them, which means you can generate high quality samples in one forward pass!
I'm trying to get an intuition for the 'Generative Modeling via Drifting' paper. This video is my first go at (badly) explaining what I think are the key ideas. I'd love pushback (pun intended) on what I'm missing!
(cc old fastdiffusion crew @iScienceLuvr@benjamin_warner )
Generative Models via Drifting in MLX.
A minimal single file implementation showing how we evolve a pushforward distribution with a drifting field during training for single-step inference. No ODE/SDE solvers, adversarial loss, or complex nets.
code: https://t.co/7eea96wToy
Drifting generative models are so fun!
I explain the physical interpretation and discuss why anti-symmetry is needed. Lots of fun visualizations in today's blog.
The kernel is indeed tricky to tune for my toy cases. More study is needed, but definitely an exciting direction!
New paradigm from Kaiming He's team: Drifting Models!
With this approach, you can generate a perfect image in a single step.
The team trains a "drifting field" that smoothly moves samples toward equilibrium with the real data distribution.
The result? A one-step generator that sets a new SOTA on ImageNet 256x256, beating complex multi-step models.
The early design decisions for the Categorical type were under strain because of our streaming engine. Every data chunk carried its own mapping between the categories and their underlying physical values, forcing constant re-encoding. The global StringCache we built to solve it caused lock contention and wasn't designed for a distributed architecture.
The new Categories object, released in 1.31, solves this, and gives you:
• Control over the physical type (UInt8/16/32)
• Named categories with namespaces
• Parallel updates without locks
• Automatic garbage collection
When you know the categories up front you can use Enums. They're faster because of their immutability and allow you to define the sorting order of values.
The StringCache is now a no-op, but the code will keep working how it used to (with global Categories). You can also migrate by replacing it with explicit Categories where needed.
The result is a Categoricals data type that works well on the streaming engine without performance degradation, and is compatible with a distributed architecture.
Read the full deep dive: https://t.co/kkikdqxrER
DuckDB now supports reading from and writing to the Vortex file format! The DuckDB Labs and Spiral teams have worked together to make Vortex available as a core extension in DuckDB.
Vortex is an open source, columnar file format whose design is heavily influenced by recent research in lightweight compression encodings, computing and IO techniques.
We gave it a test drive, and it performed very well. Read the full article to learn more https://t.co/qBZUrQ81Ni