Super stoked to share my first first-author paper that introduces a hybrid architecture approach for real-time neural decoding. It's been a lot of work, but happy to showcase some very cool results!
New preprint! 🧠🤖
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7
🚨Excited to announce our workshop Context Beyond the Window hosted at COLM in SF! 🚨
LLMs have finite context windows, yet real-world tasks demand absorbing, retaining, and acting on information that far exceeds any single prompt.
1/3
We're looking for submissions across:
https://t.co/6y1ILeeC9A
• Context compression 🧃 — token compaction, recursive subagent calls, and external memory for storing and retrieving information
• Efficient architectures 🚀 — sub-quadratic attention variants that make extremely long context computationally feasible
• Continual training 🌱 — test-time training on streaming data, context distillation, and knowledge accumulation through continued pre-training
• Agentic memory systems 🐘 — scaffolds and test-time scaling techniques that improve knowledge retention and acquisition in LLMs
• Evaluation 🎯 — benchmarking models on increasingly long-horizon tasks
The Montreal Expos are exiting the baseball space. During Q2 and Q3 2026, we will transition to acquiring high-performance GPU assets. This is all part of our long-term vision to become a fully integrated GPU-as-a-Service (GPUaaS) and AI-native cloud solutions provider.
How do neural circuits in the brain implement normalization? 🧠
In our new paper, we show that just normalizing sensory input isn't enough. Crucially, we must also normalize the error signals! 🧵👇
Paper: https://t.co/IMZPSulQAH
very important to fly out of Toronto’s Pearson airport at least once in your life so you can experience what it’s like to be inside an airport that personally and specifically hates you
JEPA are finally easy to train end-to-end without any tricks!
Excited to introduce LeWorldModel: a stable, end-to-end JEPA that learns world models directly from pixels, no heuristics.
15M params, 1 GPU, and full planning <1 second.
📑: https://t.co/cpTzgvbTS0
Montreal deep tech scene is getting hot!! Many recent hires of Cohere, Mistral, Periodic Labs, Poolside are all based in Montreal. And now, AMI will have an office here 🔥
It's a no-brainer, though. @Mila_Quebec has the highest concentration of deep learning expertise with interdisciplinary connections.
Thanks to recent US regulation changes on immigration, no more brain drain! Let's build more in Canada!
Hot Take: Canada should bid for the Summer Olympics with a joint Toronto-Montréal hosting arrangement, and then use this public event in order to create political pressure that will accelerate the completion of the high-speed rail project.
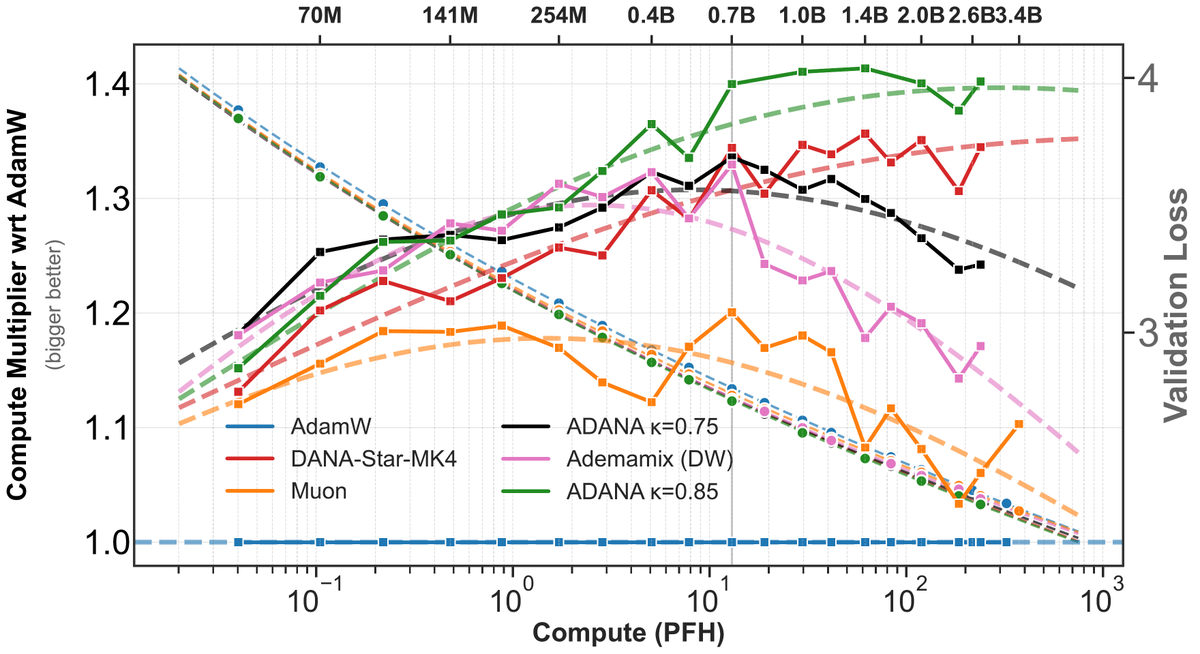
1/10 We built ADANA, an optimizer that gets better as you scale.
It extends AdamW with log-time schedules for momentum and weight decay — same hyperparameter count, no extra engineering. Scaled from 45M to 2.6B, it saves ~40% compute vs tuned AdamW, and the gap keeps growing.🧵
Remember all the self-distillation papers that came out last week. Well, we also propose it 😅, but…
But alongside something better 😎 π-Distill
We show that with this method, you can distill closed-source frontier models even tho their traces are hidden 🔒.
Both our methods can reach and even surpass the performance of the industry-standard SFT + RL with access to reasoning traces 🤯.
🔬And we spent ~100,000 hours GPU hours on a comprehensive analysis, not because the method is finicky, but because we wanted to understand why it works so well.
🧵
1/10
How can we predict multiple plausible targets from a single context in joint-embedding self-supervised learning (SSL)?
Check out our paper titled “Self-Supervised Learning from Structural Invariance” accepted at #ICLR2026! Previously Best Paper Award at @unireps 2025.
https://t.co/mN5e1huPO9
We introduce AdaSSL, which models the target uncertainty and relaxes the standard assumption that the positive pair share the same semantic features.
Derived from first principles, we realize @ylecun’s JEPA with a learned latent variable for jointly learning better representations and world models, extending SSL’s utility to a broader range of data types.
1/🧵
Hi @YouJiacheng. Thanks for going through our paper.
Just to clarify, when we refer to "k3-in-loss" (or any estimator in loss) in the paper, we mean using it in the manner GRPO did, i.e. without the importance sampling correction, and we are just pointing out that it is biased. We mention this in Section 3.
We are not saying that the estimator is wrong and agree that the correct way to use it is with the importance sampling ratio as pointed out in @yifan_zhang_'s paper.
Discover the Workshop orkshop Foundation Models for the Brain and Body, co-organized by Mila student Nanda Harishankar Krishna (@nandahkrishna) at @NeurIPSConf room 24ABC.
Excited to present PITA at #NeurIPS2025 Spotlight! 🎉 Catch us tomorrow (Fri, Dec 5) 4:30–7:30pm, poster #1604. Come talk sampling + AI for science and kick off your Friday night right ✨