How can we predict multiple plausible targets from a single context in joint-embedding self-supervised learning (SSL)?
Check out our paper titled “Self-Supervised Learning from Structural Invariance” accepted at #ICLR2026! Previously Best Paper Award at @unireps 2025.
https://t.co/mN5e1huPO9
We introduce AdaSSL, which models the target uncertainty and relaxes the standard assumption that the positive pair share the same semantic features.
Derived from first principles, we realize @ylecun’s JEPA with a learned latent variable for jointly learning better representations and world models, extending SSL’s utility to a broader range of data types.
1/🧵
It’s surprisingly easy to improve intuitive physics in video generative models with a powerful latent world model ;)
Talk to @DYDYYDYYYD@adri_romsor@michal_drozdzal if you are at #CVPR
Giving a talk at ICLR MemAgents Workshop tomorrow, 11:25am local, Room 205: "Does Your LLM Agent Have a Self?" Spoiler: probably not — but the reason is more nuanced than "they're just LLMs." Hope to see you there!
I’m at #iclr2026 till Monday! DM if you’re interested in image / video generation, representation learning, physics plausibility, gen diversity, and any other.
I’ll present at
1. P4 - 3114 3-5pm Thu
2. @AIatMeta booth 9-10:30am Fri, 12-1:30pm Sat
3. Lifelong agent workshop Sun
I’ll present our paper on how prompt complexity change the generated distribution in T2I models (https://t.co/P5x1cd6ACI) at ICLR 26!
Come and chat at Pavillon 4 - #3114 tomorrow 23 April 3PM :)
@hafezghm and I are in Rio presenting this work. Come by our poster and chat about SSL, world models, and continual learning!
🗓️ Saturday, April 25th, 10:30am
📍Pavilion 3-#112
How can we predict multiple plausible targets from a single context in joint-embedding self-supervised learning (SSL)?
Check out our paper titled “Self-Supervised Learning from Structural Invariance” accepted at #ICLR2026! Previously Best Paper Award at @unireps 2025.
https://t.co/mN5e1huPO9
We introduce AdaSSL, which models the target uncertainty and relaxes the standard assumption that the positive pair share the same semantic features.
Derived from first principles, we realize @ylecun’s JEPA with a learned latent variable for jointly learning better representations and world models, extending SSL’s utility to a broader range of data types.
1/🧵
Presenting Future Summary Prediction at #ICLR2026 🇧🇷
📌 Friday, 24th April, 10.30 am
📍Pavilion 3 (521)
Come over to chat about novel pretraining objectives for LLMs!
I’m in Rio presenting this work at the SPOT workshop 🇧🇷☀️!
Feel free to reach out to chat about self distillation/privileged information and/or anything to do with post-training/long horizon agents.
JEPA are finally easy to train end-to-end without any tricks!
Excited to introduce LeWorldModel: a stable, end-to-end JEPA that learns world models directly from pixels, no heuristics.
15M params, 1 GPU, and full planning <1 second.
📑: https://t.co/cpTzgvbTS0
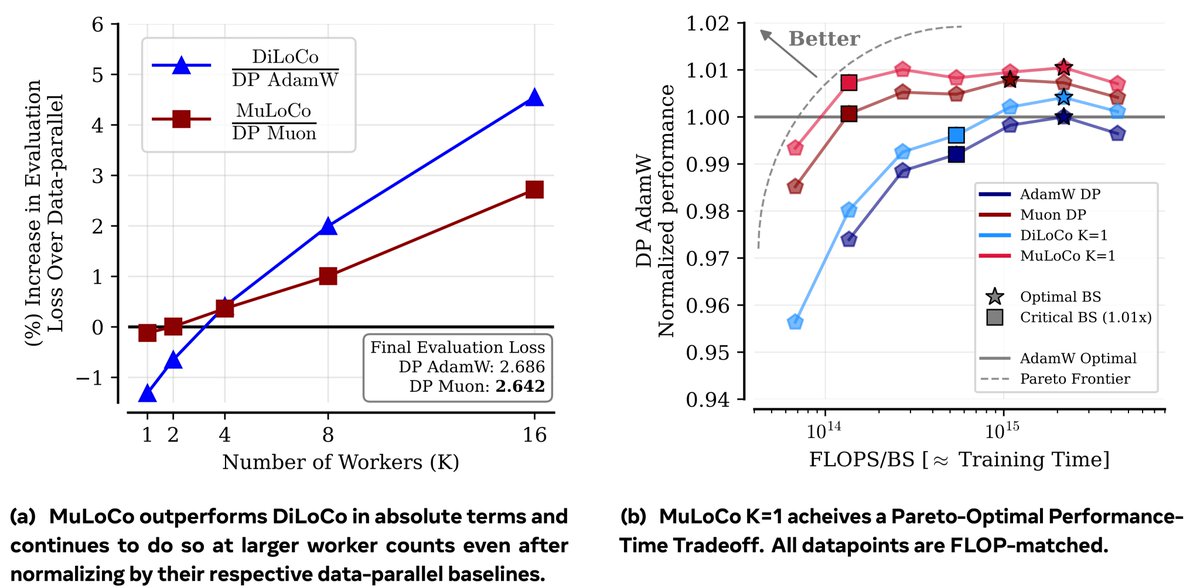
Are frontier LLMs trained across datacenters? One thing is certain: if the pre-training optimizer’s critical batch size is too small, they are NOT! Excited to announce MuLoCo, a pre-training optimizer that can efficiently pre-train across datacenters while having large enough batch sizes to warrant doing so. 🧵1/N
World Modeling research needs fast iteration, reproducibility, optimized baselines, open-source, and precise zero-shot stress testing. Here comes stable-worldmodel!
Paper: https://t.co/aGmoYOId8U
Code: https://t.co/YN3PS5xxV9
Come stress-test your model/idea!
DINO-WM results ⬇️
I had a lot of fun meeting all the smart people at this workshop and presenting my work "On the Identifiability of Latent Action Policies" as an oral! A huge thanks to the organizers!
Paper: https://t.co/FqTwVTxI4Z
Remember all the self-distillation papers that came out last week. Well, we also propose it 😅, but…
But alongside something better 😎 π-Distill
We show that with this method, you can distill closed-source frontier models even tho their traces are hidden 🔒.
Both our methods can reach and even surpass the performance of the industry-standard SFT + RL with access to reasoning traces 🤯.
🔬And we spent ~100,000 hours GPU hours on a comprehensive analysis, not because the method is finicky, but because we wanted to understand why it works so well.
🧵
1/10
How can we predict multiple plausible targets from a single context in joint-embedding self-supervised learning (SSL)?
Check out our paper titled “Self-Supervised Learning from Structural Invariance” accepted at #ICLR2026! Previously Best Paper Award at @unireps 2025.
https://t.co/mN5e1huPO9
We introduce AdaSSL, which models the target uncertainty and relaxes the standard assumption that the positive pair share the same semantic features.
Derived from first principles, we realize @ylecun’s JEPA with a learned latent variable for jointly learning better representations and world models, extending SSL’s utility to a broader range of data types.
1/🧵
We hope AdaSSL inspires new ideas for using joint-embedding SSL to learn better representations and world models on naturally structured data.
Kudos to my amazing collaborators: @hafezghm@yololulu_@ShahabBakht@NeuralEnsemble@lcharlin
Paper: https://t.co/mN5e1huPO9. Code coming soon.
See you in Rio 🇧🇷
🧵/🧵
How can we predict multiple plausible targets from a single context in joint-embedding self-supervised learning (SSL)?
Check out our paper titled “Self-Supervised Learning from Structural Invariance” accepted at #ICLR2026! Previously Best Paper Award at @unireps 2025.
https://t.co/mN5e1huPO9
We introduce AdaSSL, which models the target uncertainty and relaxes the standard assumption that the positive pair share the same semantic features.
Derived from first principles, we realize @ylecun’s JEPA with a learned latent variable for jointly learning better representations and world models, extending SSL’s utility to a broader range of data types.
1/🧵
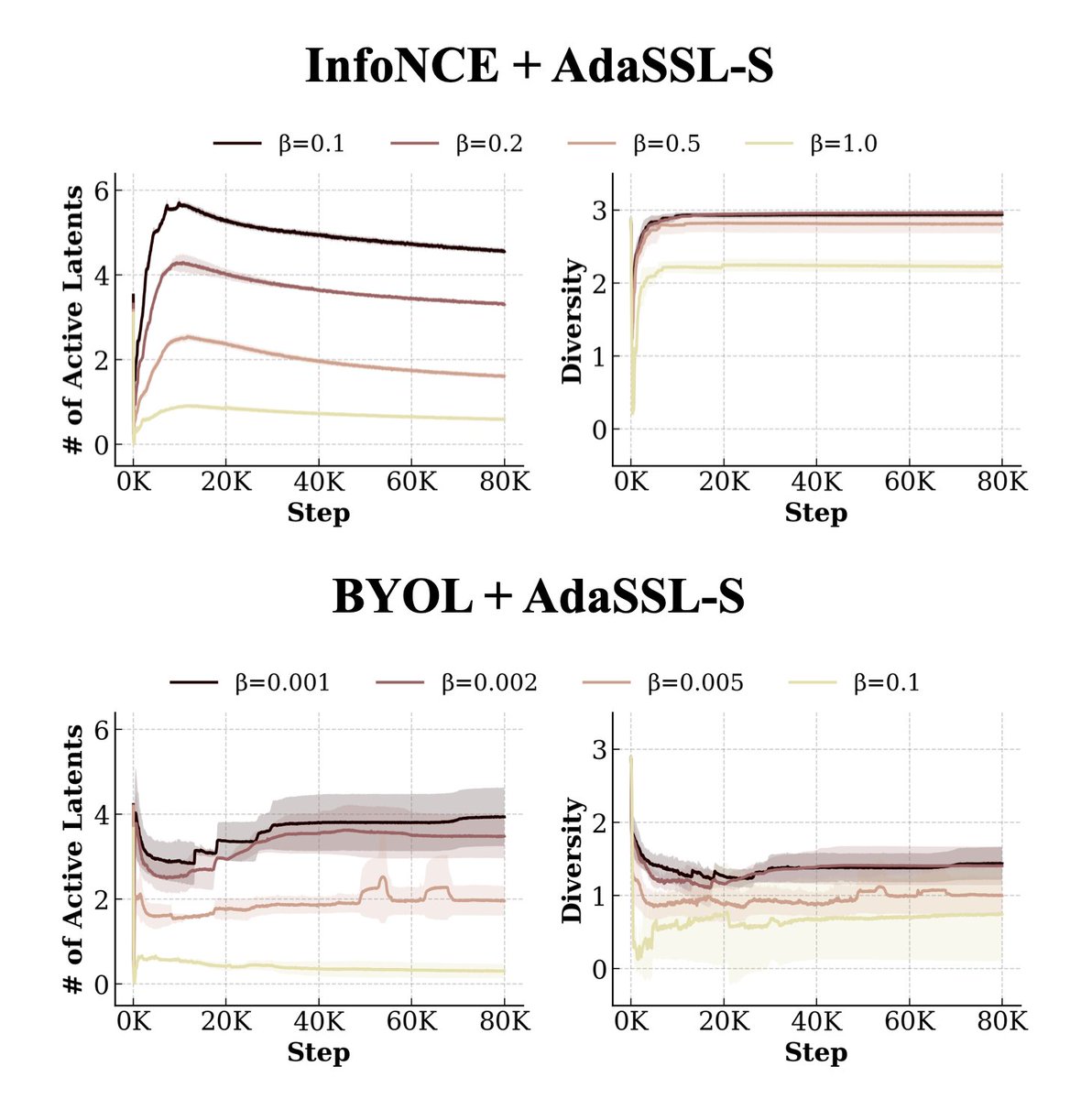
Across experiments, AdaSSL-V consistently improves both contrastive and distillation-based SSL. AdaSSL-S reliably improves contrastive SSL, but less so with distillation.
Why? Here are the plots of r-space usage (sparsity and diversity of the gated modules), on InfoNCE vs BYOL. With BYOL, AdaSSL-S often underutilizes r, reflected by lower diversity.
Hypothesis: (sample- or dimension-)contrastive objectives explicitly regularize information content in the embeddings, which forces the model to use r. Distillation lacks this direct pressure, so r may need extra regularization.
Curious to see how this finding affects practical use cases…
10/🧵