@wrongbyte True. The only problem is that I’d like to write everything on paper because I feel like I learn better that way.
But writing takes so much time that I eventually gave up on that idea, and now I just take notes in Obsidian
this is a weird long post without much substance
I strongly recommend against reading it
...
so, do you feel like whatever you're working on right now is pointless, or will have zero value soon, due to the crazy times we're living? then, perhaps you should stop, and start working on the only unsolved problem that actually matters TODAY:
✨ replicating GPT-3 in a laptop ✨
"why is that so important?"
because it would make AI incredibly cheap, which would mean everyone would have Fable-class models in their laptops, without depending on Anthropic, OpenAI, or any other hyper-scaler giant. and that's amazing, don't you think?
"isn't that literally impossible?"
that's the cool part: as far as computer science is concerned, no. not really. not at all. is entirely plausible and, as far as we know, most likely not even hard.
it takes one good idea. one breakthrough. one great "aha moment", to go from zero to "hey, this software I wrote is producing credible English sentences"
and whenever that happens:
- the entire AI industry collapses
- clusters are liquidated
- we all get Fable at home
- you become famous and rich, if that's your thing
sounds fun, doesn't it?
"wtf you talking, OF COURSE that is hard"
so prove it.
show me a paper, a lean file, anything that proves that training a Fable-class model fundamentally requires billions of dollars. you can't, because, guess what - it is not true! the only "evidence" we have is purely psychological. "many attempted over decades, and the best thing we have is GPTs, so, it is a hard problem" - but that's not a scientific argument. that's a human, psychological, sociological argument. and if that's it, consider the following counter-argument:
✨ humans are stupid as hell ✨
I mean, 10 years ago we didn't have transformers, so, that very argument could be used against GPTs existing. yet, they exist. we have them now, because someone found it. and, guess what, it isn't even complex. I mean, karpathy implemented the whole thing in a napkin. and it probably compiles.
we were just too dumb to figure GPTs out... for decades.
just like GPTs, there ARE other approaches, other algorithms, other architectures, equally simpler or even simpler, that do work. this is a mathematical certainty. and one of them might be astronomically faster than what we're doing right now.
and you might be the one to find it!
"me? why me???"
because you're intelligent, creative and handsome.
I see a lot of potential in you.
in fact, I always believed in you.
and I think you're wasting your time, doing that silly agent orchestrator. nobody wants that. quit it. take your most interesting ideas, intuition, creativity, and work in a problem that matters. do your best shot at reproducing GPT-3 in your own laptop.
do NOT fork llama.cpp.
do NOT train another LLM.
do something... ✨different✨
it must be unique, novel, full of YOUR soul. something nobody thought of, or bothered doing.
go ahead and implement that thing in C/CUDA (or Bend!).
no Python!
zero excuses for Python.
any model is fluent in GPGPU now. build a real kernel.
and then, train your thing. download wikipedia, give it time and compute to absorb the patterns of English speech. you can rent GPUs anywhere nowadays. let it train. then, ask it some questions. chances are it will just respond back. just like GPT-2 answered OpenAI. computers are incredible. don't underestimate them!
"many tried. nobody succeeded. why would I?*
see - that's your mistake again. turns out not many actually tried, at all. I promise you. who do you think is seriously working on that?
people on Mozilla?
they're busy building a browser
Linus Torvalds?
he is busy building an OS
employees at OpenAI, Anthropic, xAI?
they're paid to work on what is proven to work: GPTs.
what about all the AI enthusiasts all around the world?
yeah, you know they're mostly fine tuning Qwen
and how about your friends?
if only they weren't busy building a SaaS in the eve of AGI...
how about people from the past?
bro - people from the past seriously expected Lisp would be AGI. just dismiss them. they didn't have the compute, the resources, the knowledge, the MODELS that we have today. that YOU have access to.
so, what's left? not much.
the world looks big. it is not.
truth is: ✨almost nobody is working on this ✨
"I still think it is impossible. I don't trust you"
well, take my word no more.
Ilya himself, in his 2019 talk on GPT-2, said:
> "the story of deep learning is this: empirically old simple methods which were usually invented in the 80s and the 90s when scaled up on very large clusters work really well."
and then:
> "(we took) normal simple reinforcement learning method, scaled it up, and discovered that it suddenly becomes very capable of solving extremely hard problems."
and again:
> "you take a simple tool which is unimposing and barely works, and then you run it on a big cluster and suddenly it works, it becomes a capable tool for solving problems"
do you see the point here?
Ilya isn't arguing that transformers are magic.
Ilya is arguing that SCALING is magic
step #1: take a simple, elegant algorithm.
step #2: shove compute at its face.
step #3: ...?
step #4: your computer is talking to you
THAT is the key insight that led to GPT-3
THAT is what Ilya saw
THAT is what caused the OpenAI x Anthropic war
THAT is the founding principle of the ongoing era
not "scaling transformers work"
but "scaling beautiful algorithms works"
that's the incredible lesson.
yet, we all took it and... threw it way.
- zurk bought 100k GPUs. to train GPTs
- musk bought 100k GPUs. to train GPTs
- bezos bought 100k GPUs. to train GPTs
...
that's what everyone is doing.
so, no. not many are trying to replicate GPT-3 through other means.
we're just ants, after all...
whenever we find a pile of sugar, we leave a track of pheromones, which guide the rest of the colony towards the new food source. the colony then swarms around the pile, extract all of it, until no grain is left.
but piles of sugar aren't spontaneously generated in the middle of nowhere. they imply something more profound: "humans are around". and, if humans are in sight, even better things must be. like a big sweet cake.
a colony that only follows the pheromone trail would miss the cake for the grains. that's why every ant species has scouts and exploratory foragers. and, just like a pile of sugar implies something more profound, LLMs also imply something quite profound:
*computers are capable of thinking*
a pile of sugar is never alone.
GPTs are most likely not the only system capable of thinking.
so, if you find yourself a bit lost, without purpose, like your work is pointless and Fable 3 will soon one shot it anyway... consider becoming a scout. find a new approach to AI. bring something new to humanity. breaking out of the massive cost associated with training GPTs is the next big step in AI, and it will only happen if people like you work to make it happen.
ماذا تفعل وقت فراغك ؟
ايوب بوعدي ( قبل سنتين ) :
ادرسُ الرياضيات هذا لأستغل وقت فراغي على أكمل وجه، هكذا تربيت وهذا يساعد على إبقاء ذهني نشطاً
- يعني أيوب جامع كل الأشياء
كرة قدم ؟ لاعب من النخبة
دراسة ؟ مُثقف ويدرسُ الرياضيات
تربية ؟ خلوق وأفضل تربية
@itsaflecha O Dário e o Demis já falaram publicamente sobre uma pausa no avanço
Apesar disso acho que a regulação por mais tardia que seja vai chegar, acho que o modelo atual vai ser o mais avançado que vamos ter acesso o resto vai ser só o Governo. Depende dos modelos OSS também
Conheci recentemente uma estudante de PhD em Filosofia por Princeton. A moça, que fala nada mais nada menos que seis idiomas e especializa-se em Filosofia Oriental Antiga, está visitando Berkeley e, neste exato momento, estudando para obter uma certificação em Machine Learning. Enquanto isto, no Brasil, a nossa turminha universitária humanista segue batendo pé para aprender a somar 2+2, porque pensa que matemática não tem utilidade em humanidades.
@mmarccs Até acho que seria mais fácil ir para uma universidade da Inglaterra, como Warwick, que provavelmente não perderia nada em qualidade, mas o país pesa muito França >>> Inglaterra
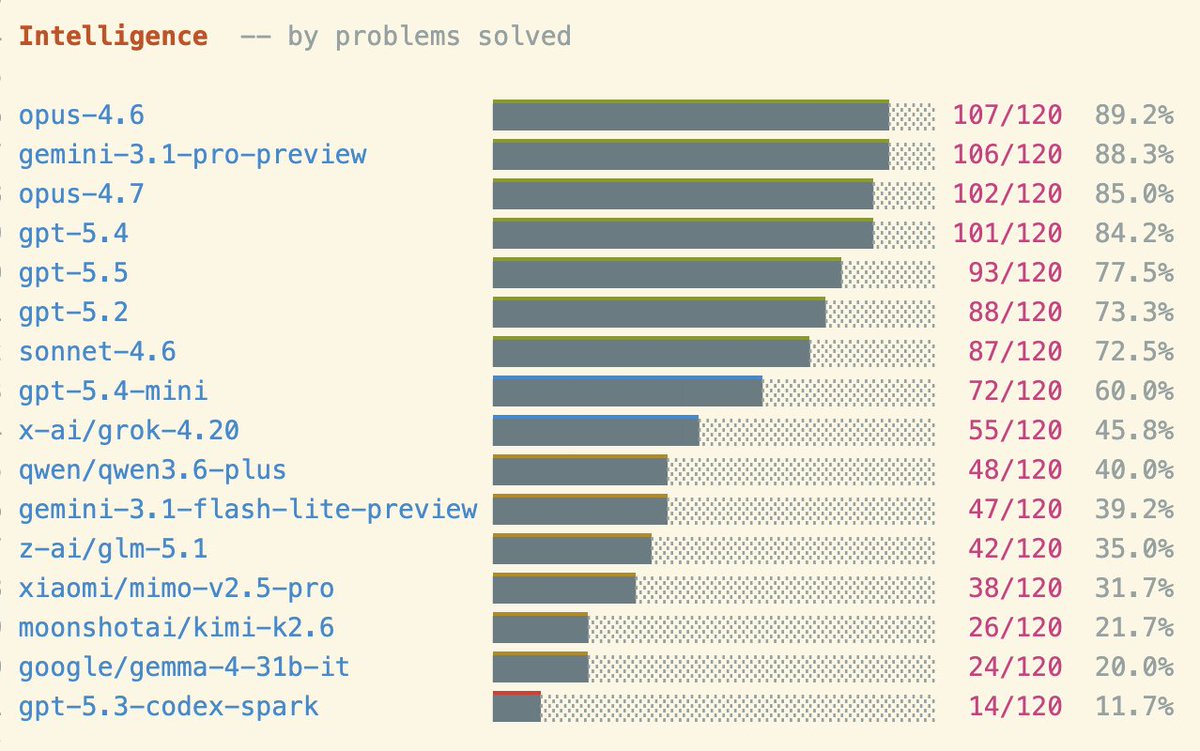
Introducing LamBench . . .
You asked me to make a benchmark, so I made it. It is a simple, old style Q&A consisting of 120 fresh λ-calculus programming questions. Some are easy, like "implement add for λ-encoded nats". Some are harder, like "derive a generic fold for arbitrary λ-encodings".
It measures:
- intelligence (% tasks completed)
- elegance (BLC-length of solutions)
- speed (completion time)
Basically what I care about, other than long context.
I made it today because I was excited about GPT 5.5.
It didn't do too well ):
(My first-day impression is that I can't tell the difference between GPT 5.5 and GPT 5.4. I would be lying if I said otherwise. I'd not be able to distinguish in a blind test. I need more time. It is much faster though.)
This is a new, simple bench, so expect be bugs.
Specially on OpenRouter models. I'll retest soon.
Also, it was born saturated. V2 will be harder...
↓ Link and more charts below ↓
@VictorTaelin depressed too but more because look like anything that im in right now will be useless in 2 yr or any big AI company will do it in 3 months with supermodels that they hidden/gatekeep
@dionisiodev Fundamentos da Matematica Elementar (livro) depois disso voce ta com os pre-requisitos prontos pra estudar qualquer coisa.
nao precisa fazer todas as questoes uns 30% ja eh suficiente.
Então tu quer aprender sobre COMPILADORES? Minhas recomendações GRATUITAS pra quem tem curiosidade de saber como que uma linguagem é executada (em inglês):
1. Começa pelo https://t.co/6uo726d3Pt. Esse é um livro completo que vai te ensinar como um interpretador é construído, desde parsing até representação de bytecode. Muitos dos fundamentos de um interpretador são os mesmos de um compilador, então isso vai te dar uma base bem versátil.
2. Depois do Crafting Interpreters, ou se você já tiver uma noção de interpretadores, eu recomendo muito o "Introduction to Compilers and Language Design". Esse é um livro-texto universitário gratuito: https://t.co/eGGUanIKCL e ele lida com toda a parte de compilar uma linguagem C-like pra assemblies x86 e ARM.
3. Outro recurso excelente sobre geração de código é o tutorial do LLVM, que consiste em construir uma mini-linguagem chamada Kaleidoscope e compilá-la pra LLVM IR - aí o LLVM cuida de transformar a IR no Assembly de sua preferência: https://t.co/7TE3tgqHI0
4. O "Architecture of Open-Source Applications" - um livro gratuito que, honestamente, eu recomendo ler inteiro - tem um capítulo só sobre a arquitetura do LLVM e os tradeoffs que ele faz. Vale demais a leitura: https://t.co/sGuDPild6y
Deixei passar algum recurso? Se tiverem outras recomendações é só deixar nas respostas.