❗️🚨 BREAKING: Researchers used Mythos Preview to find the first public macOS kernel memory corruption exploit on Apple's M5 silicon, they give a glimpse into Mythos say it’s really powerful.
Apple spent five years and an estimated several billion dollars building Memory Integrity Enforcement (MIE), the hardware-assisted memory safety system built around ARM's MTE. It was the flagship security feature of the M5 and A19, designed specifically to kill the entire memory corruption bug class.
Researchers from Calif built a working exploit in five days.
According to Apple's own research, MIE disrupts every public exploit chain against modern iOS, including the recently leaked Coruna and Darksword kits. Calif walked into Apple Park this week and handed over the report in person.
Full 55-page technical report drops after Apple patches the vulnerability.
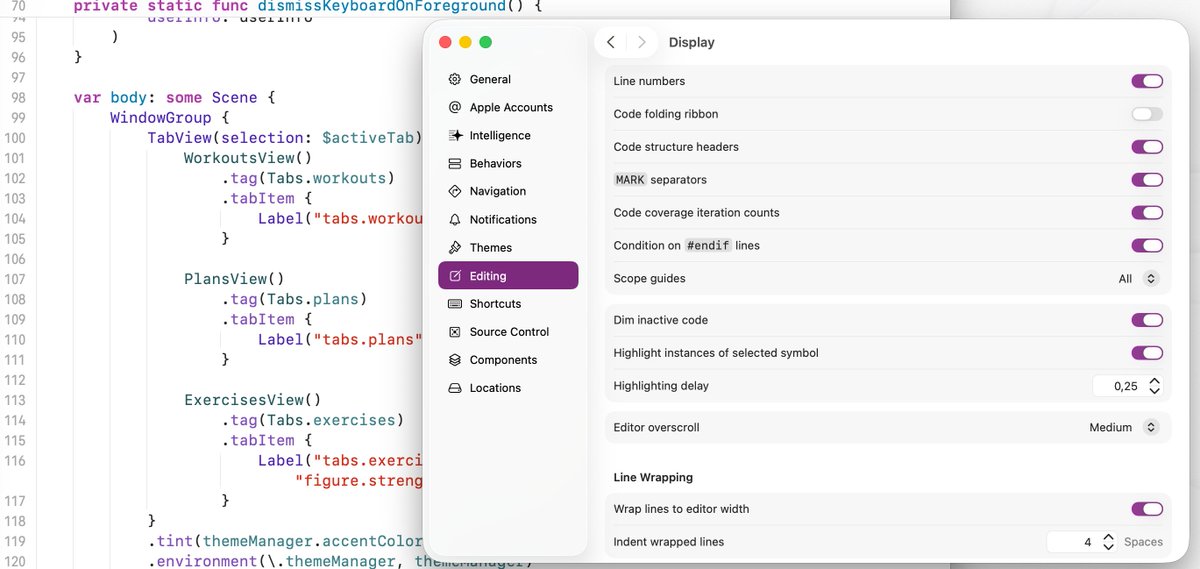
PSA: Xcode 26.4 comes with scope guides 🤩 (finally). No more messing about to figure out how your braces line up! Turn them on in Settings -> Editing -> Display -> Scope Guides
@YouTube@gmail my YouTube channel was hacked, channel no longer available, and my phone number and password has been changed. What do I do? 💔pls help 🙏
🚨 BREAKING: Silicon Valley's hacker houses are battling for ultimate supremacy 🚨
For the first time EVER, SF's legendary hacker houses are going head to head at the HACKOLYMPICS — part hackathon, part Olympics 🏆
📍 Sat June 21st
🎯Hackathon main quest + trials beyond code —intense mental puzzles, physical feats, and raw creativity for bonus points
🧙♀️Rep your house or get sorted into one
🍹Endless boba
VCs judging. Prizes. One day. One winner. 👑
RSVP to enter the arena 👇
New 3h31m video on YouTube:
"Deep Dive into LLMs like ChatGPT"
This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It is covers the full training stack of how the models are developed, along with mental models of how to think about their "psychology", and how to get the best use them in practical applications.
We cover all the major stages:
1. pretraining: data, tokenization, Transformer neural network I/O and internals, inference, GPT-2 training example, Llama 3.1 base inference examples
2. supervised finetuning: conversations data, "LLM Psychology": hallucinations, tool use, knowledge/working memory, knowledge of self, models need tokens to think, spelling, jagged intelligence
3. reinforcement learning: practice makes perfect, DeepSeek-R1, AlphaGo, RLHF.
I designed this video for the "general audience" track of my videos, which I believe are accessible to most people, even without technical background. It should give you an intuitive understanding of the full training pipeline of LLMs like ChatGPT, with many examples along the way, and maybe some ways of thinking around current capabilities, where we are, and what's coming.
(Also, I have one "Intro to LLMs" video already from ~year ago, but that is just a re-recording of a random talk, so I wanted to loop around and do a lot more comprehensive version of this topic. They can still be combined, as the talk goes a lot deeper into other topics, e.g. LLM OS and LLM Security)
Hope it's fun & useful!
https://t.co/75mXcUBI8L
The buzz over DeepSeek this week crystallized, for many people, a few important trends that have been happening in plain sight: (i) China is catching up to the U.S. in generative AI, with implications for the AI supply chain. (ii) Open weight models are commoditizing the foundation-model layer, which creates opportunities for application builders. (iii) Scaling up isn’t the only path to AI progress. Despite the massive focus on and hype around processing power, algorithmic innovations are rapidly pushing down training costs.
About a week ago, DeepSeek, a company based in China, released DeepSeek-R1, a remarkable model whose performance on benchmarks is comparable to OpenAI’s o1. Further, it was released as an open weight model with a permissive MIT license. At Davos last week, I got a lot of questions about it from non-technical business leaders. And on Monday, the stock market saw a “DeepSeek selloff”: The share prices of Nvidia and a number of other U.S. tech companies plunged. (As of the time of writing, some have recovered somewhat.)
Here’s what I think DeepSeek has caused many people to realize:
China is catching up to the U.S. in generative AI. When ChatGPT was launched in November 2022, the U.S. was significantly ahead of China in generative AI. Impressions change slowly, and so even recently I heard friends in both the U.S. and China say they thought China was behind. But in reality, this gap has rapidly eroded over the past two years. With models from China such as Qwen (which my teams have used for months), Kimi, InternVL, and DeepSeek, China had clearly been closing the gap, and in areas such as video generation there were already moments where China seemed to be in the lead.
I’m thrilled that DeepSeek-R1 was released as an open weight model, with a technical report that shares many details. In contrast, a number of U.S. companies have pushed for regulation to stifle open source by hyping up hypothetical AI dangers such as human extinction. It is now clear that open source/open weight models are a key part of the AI supply chain: Many companies will use them. If the U.S. continues to stymie open source, China will come to dominate this part of the supply chain and many businesses will end up using models that reflect China’s values much more than America’s.
Open weight models are commoditizing the foundation-model layer. As I wrote previously, LLM token prices have been falling rapidly, and open weights have contributed to this trend and given developers more choice. OpenAI’s o1 costs $60 per million output tokens; DeepSeek R1 costs $2.19. This nearly 30x difference brought the trend of falling prices to the attention of many people.
The business of training foundation models and selling API access is tough. Many companies in this area are still looking for a path to recouping the massive cost of model training. Sequoia’s article “AI’s $600B Question” lays out the challenge well (but, to be clear, I think the foundation model companies are doing great work, and I hope they succeed). In contrast, building applications on top of foundation models presents many great business opportunities. Now that others have spent billions training such models, you can access these models for mere dollars to build customer service chatbots, email summarizers, AI doctors, legal document assistants, and much more.
Scaling up isn’t the only path to AI progress. There’s been a lot of hype around scaling up models as a way to drive progress. To be fair, I was an early proponent of scaling up models. A number of companies raised billions of dollars by generating buzz around the narrative that, with more capital, they could (i) scale up and (ii) predictably drive improvements. Consequently, there has been a huge focus on scaling up, as opposed to a more nuanced view that gives due attention to the many different ways we can make progress. Driven in part by the U.S. AI chip embargo, the DeepSeek team had to innovate on many optimizations to run on less-capable H800 GPUs rather than H100s, leading ultimately to a model trained (omitting research costs) for under $6M of compute.
It remains to be seen if this will actually reduce demand for compute. Sometimes making each unit of a good cheaper can result in more dollars in total going to buy that good. I think the demand for intelligence and compute has practically no ceiling over the long term, so I remain bullish that humanity will use more intelligence even as it gets cheaper.
I saw many different interpretations of DeepSeek’s progress here in X, as if it was a Rorschach test that allowed many people to project their own meaning onto it. I think DeepSeek-R1 has geopolitical implications that are yet to be worked out. And it’s also great for AI application builders. My team has already been brainstorming ideas that are newly possible only because we have easy access to an open advanced reasoning model. This continues to be a great time to build!
[Original text: https://t.co/yiOHeGJgLZ ]
If you’re a hardcore software engineer and want to build the everything app, please join us by sending your best work to [email protected].
We don’t care where you went to school or even whether you went to school or what “big name” company you worked at.
Just show us your code.