Lewis Hamilton recently pointed to a mismatch between simulation and reality as a major factor behind a challenging race weekend.
It's a problem every systems engineer recognizes: how do you simulate a system operating at the edge of chaos?
In our latest blog, we explore how Unconventional AI builds digital twins that faithfully model hardware operating in these highly sensitive regimes, capturing the physical and numerical effects that can significantly influence real-world performance.
Read the full post: https://t.co/f1mv15xMcZ
Most real-world systems are dynamic.
So why do we still treat computation as static?
Our latest blog explores computation through motion using gyroscopes, rods, springs, and ordinary differential equations to perform handwritten digit classification.
A deep dive into:
• dynamical systems as compute
• differentiable ODE solvers
• physics-inspired machine learning
• emergent computation through interaction
Read here: https://t.co/pIwwvT72Bw
Tomorrow, May 15, is the final day to submit pre-proposals for the Unconventional Grant.
Over the past several weeks, we’ve seen proposals spanning:
• computation as dynamics
• in-memory and in-physics compute
• architectures that minimize data movement
• new abstractions beyond linear algebra
Many converge on the same intuition: meaningful efficiency gains in AI will not come from scaling existing approaches alone, but from fundamentally different ways of representing and computing.
We are looking for technically grounded ideas that challenge assumptions across hardware, systems, and learning.
We’re not looking for taller ladders to the moon. We’re looking for rockets.
https://t.co/7ups8vMcdZ
Getting to 1000x energy efficiency in AI isn’t about one breakthrough.
It’s about solving two hard constraints:
1. Data movement dominates energy
2. Amdahl’s Law caps system-level gains
Which means you have to rethink everything: models, hardware, and how they’re designed together.
If this kind of problem excites you, you’ll enjoy our latest blog: https://t.co/3FFKWIm1nc
At [un] @unconvAI we're not only rethinking computers, but also how intelligence emerges from the physical world. We're working at the frontier and our computing primitives are physics.
If you're interested in the intersection of nonlinear dynamics and language and reasoning, apply here:
https://t.co/iGpuKvuJxe
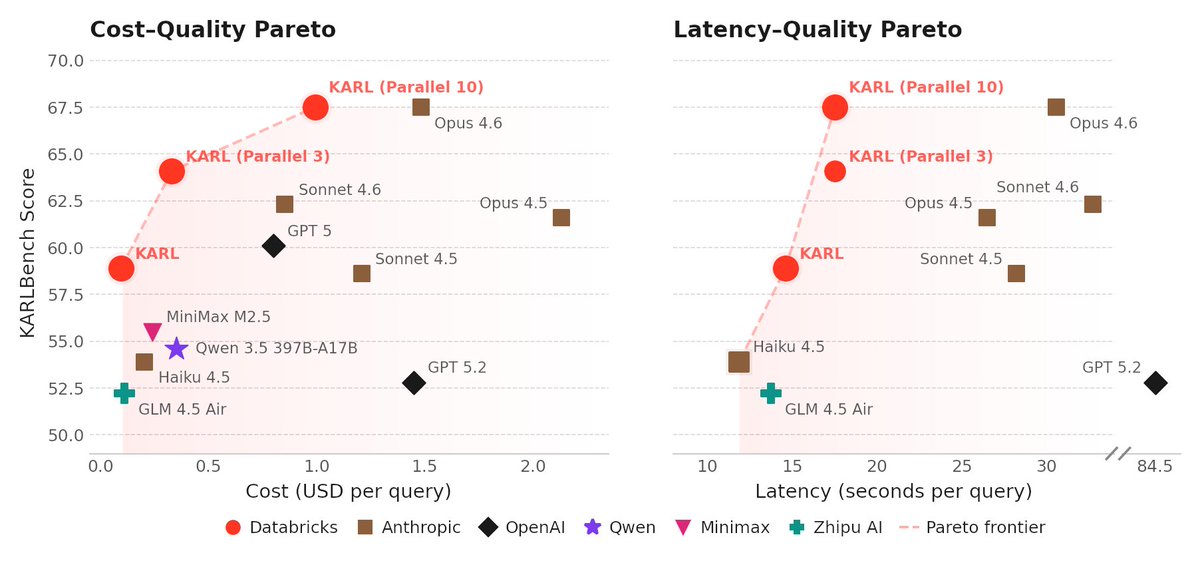
Meet KARL: a faster agent for enterprise knowledge, powered by custom reinforcement learning (now in preview).
Enterprise knowledge work isn’t just Q&A. Agents need to search for documents, find facts, cross-reference information, and reason over dozens or hundreds of steps.
KARL (Knowledge Agent via Reinforcement Learning) was built to handle this full spectrum of grounded reasoning tasks. The result: frontier-level performance on complex knowledge workloads at a fraction of the cost and latency of leading proprietary models.
These advances are already making their way into Agent Bricks, improving how knowledge agents reason over enterprise data.
And Databricks customers can apply the same reinforcement learning techniques used to train KARL to build custom agents for their own enterprise use cases.
Read the research → https://t.co/eFyXxCWUAd
Blog: https://t.co/03sLHTUcLl
Databricks just signed a Series K term sheet at >$100B valuation to scale two flagship products:
🔥 Lakebase — serverless Postgres with true compute/storage separation
🧠 Agent Bricks — agentic framework with built-in reasoning guardrails for enterprise data
https://t.co/rgM5vMggwe
RLVR isn't just for math and coding! At @databricks, it's impacting products and users across domains. One example: SQL Q&A. We hit the top of the BIRD single-model single-generation leaderboard with our standard TAO+RLVR recipe - the one rolling out in our Agent Bricks product.
I'm at ICML 🇨🇦 and I'm hiring at @databricks. Visit our booth if you're interested. My scientific focus: It's 1972 in AI, there's an AI crisis, Dijkstra isn't here to save us, and maybe RL can. Why Databricks? The long road to AGI is being paved here and we have the real evals 🧵
Deep learning training is a mathematical dumpster fire.
But it turns out that if you *fix* the math, everything kinda just works…fp8 training, hyperparameter transfer, training stability, and more. [1/n]
Thrilled to partner with @AIatMeta to release the latest Llama 3 models on Databricks. The Llama 3.2 release pushes the frontier of enterprise GenAI w/smaller models for cost-sensitive use cases & larger multimodal models. Available in Databricks Mosaic AI https://t.co/P5gYzceh9F
Mosaic AI Model Training now supports 131K tokens for fine-tuning Meta Llama 3.1!
Build even more powerful RAG and tool use systems with long context enterprise data: https://t.co/UUDnJl6Ymz
some notes from paper!
- 405B trained on 15.6T tokens, 3.8e25 flops
- use SFT, rejection sampling and DPO
- annealing is used to judge quality of domain specific data (s/o dbrx paper)
Popular #LLM scaling laws only factor in training costs, and ignore the costs of deployment. In a paper presented at @icmlconf 2024, @databricks Mosaic AI researchers Nikhil Sardana, @JacobianNeuro, and @sashadoubov propose a modified scaling law that considers the cost of both training and inference and experimentally demonstrate how “overtrained” LLMs can be the optimal choice: https://t.co/3HgHD0RBEO
🎶🎶 Do you want to build an MoE? 🎶🎶
It was great collaboration with the team at PyTorch to integrate the tooling needed to makes MoE training easier and more efficient.
Fun collaboration between @DbrxMosaicAI and @PyTorch team! We've been working hard to scale MoEs and PyTorch distributed to thousands of GPUs, and this is a great summary of a lot of the cool things we've added to PyTorch.
Quick rundown (1/N)
We are excited to announce Vid3D, a technique for generating 3D video using only 2D video diffusion models and Gaussian splatting!
Paper: https://t.co/RnbnyRZHJU
Github: https://t.co/ZmYJEe6hOb
Project Page: https://t.co/gYQXnb9xkX
















![davisblalock's tweet photo. Deep learning training is a mathematical dumpster fire.
But it turns out that if you *fix* the math, everything kinda just works…fp8 training, hyperparameter transfer, training stability, and more. [1/n] https://t.co/wtiPo5pFsL](https://pbs.twimg.com/media/GuwROgLXcAIAyTL.jpg)




























