Introducing LongLive 2.0 by @NVIDIA.
Real-time text-to-video with full multi-shot control. Build your story shot by shot, scene by scene.
Available now on Reactor.
The next era of animation won't be generated. It'll be explored.
Yoki (予期) is my first film made with world models + video models. The landscapes of Japan, rebuilt as worlds you move a camera through with @reactorworld.
World models are the most underrated storytelling tech right now, and almost no one's using them for film.
Animation made with @invideoOfficial.
Jensen at @Computex: "Text data plus compute gives you AI. Now that we have AI, compute is data (in physical AI)"
LLMs trained on a corpus that already existed... whole internet of text. Robots have none. Nobody recorded the world in first-person, action-labeled frames. (Hence so many startups building here.)
So you generate it. World models like @nvidia 's Cosmos spend compute to produce physics-accurate, action-conditioned rollouts from any perspective, then close the loop as the policy's own simulator.
So... data becomes a compute problem in physical AI.
All those world models need to compute somewhere. That's @reactorworld ... and the biggest infrastructure opportunity in physical AI today 🔥 cc @taiuti@_bschmidtchen
The unix terminal is the natural interface for agents to get work done on a computer but how well can agents actually use unix?
Claude Code. Codex. Devin. Every frontier agent ships as a terminal tool.
With unix-ctf, Vmax is using setters and solvers to measure Unix competence.
Beautiful evening in SF @ a wonderful housefull event w/ @pratykumar of @SarvamAI talking about the company's plans, hiring for an SF office, scaling out compute, building v. large models, and global GTM. Inspiring and genuinely one of the clearest visions in the world of AI.
AI is moving from language models to world models. They need their own runtime. That's @reactorworld 🚀
LLM inference became a multi-$B category because batching, routing & GPU orchestration were too complex for app developers to own. World models will follow the same pattern... but technical bar is way higher.
The workloads are stateful, temporal, heterogeneous. Video tokens. Latent states. Action loops. Streaming rollouts. Latency and compute profiles vary across models. Different category entirely.
@taiuti@_bschmidtchen are building this from first principles. Both led technology on @Apple Vision Pro. @taiuti previously co-founded @LumaLabsAI as CTO. Privilege to be on this journey with them from the start 🙏
Congrats to @reactorworld team on the $59M Series A led by stellar investors @lightspeedvp (@buckymoore@theamberyang) @WndrCoLLC@Amplify@Sky9Capital@FPVventures@AbstractVC ... and @awscloud on board as preferred cloud partner 💪 https://t.co/70XDfjFIyq
Biggest infrastructure opportunity in physical AI today. Let's go! 🔥
The Redpoint InfraRed 100 is now live.
These are the companies building the infrastructure that powers everything happening in AI right now, from world models and agent runtimes to the sandboxes, databases, and security tools agents depend on.
Congratulations to this year's honorees!
Read the full 2026 InfraRed Report: our state of the union on AI and cloud infrastructure 👉 https://t.co/Y1y94ZwI5B
Every frontier lab is hitting the same wall: human-generated training data doesn't scale ✋
Most teams respond with bigger RLHF pipelines and more human annotators. @VmaxAI is taking a fundamentally different approach.
Their new PopuLoRA paper introduces co-evolving populations of LoRA adapters performing asymmetric self-play on a frozen base model. They're doing evolutionary operations directly in weight space
Teams working on self-improvement without human data dependency will matter a lot. Talk to @MavorParker to learn more. They are hiring too!
Vmax is building an open-ended learning system that generates and optimizes itself on tasks that it creates, avoiding human bias that may corrupt optimal learning curricula.
In PopuLoRA, we instantiate this as co-evolving populations of LLMs performing asymmetric self-play.
We're taking our first step towards democratizing World Models, so that everyone can build on this incredible technology.
We have more to share, but enjoy a glimpse of what's to come, today.
Try it here: https://t.co/FP7acKd7v7
Real-time World Models are the next AI frontier.
Today, we @reactorworld are taking the first step towards this reality: our early preview lets you experience worlds generated in real-time, running on our global low-latency infrastructure.
Try it now: https://t.co/YojJ5qVDrG
Real-time World Models are the next AI frontier.
Today, we're taking the first step towards this reality: our early preview lets you experience worlds generated in real-time, running on our global low-latency infrastructure.
Try it now: https://t.co/h0XDYsHcGB
The missing layer in the physical AI stack is starting to emerge: https://t.co/kfVJLoWddL
LLMs became useful to developers only after the serving layer matured. Inference providers abstracted away GPU orchestration, batching, routing, scaling, and model-specific deployment. This led to several multi-$B startups 💰
World models need their own version of that layer. But this is not just “LLM inference with video” 🚫
World models are stateful, temporal, and heterogeneous. They involve video tokens, latent states, action loops, rollouts, streaming generation, multimodal inputs, and very different latency/compute profiles across models.
The next generation of physical AI experiences will need a runtime that can orchestrate these models, preserve state, manage latency, hide backend complexity, and expose a clean developer surface.
The foundation models for physical AI are being built. Now the experience layer needs its execution engine.
@reactorworld is starting to reveal that layer today... Check out the demo here 👀 @taiuti@_bschmidtchen
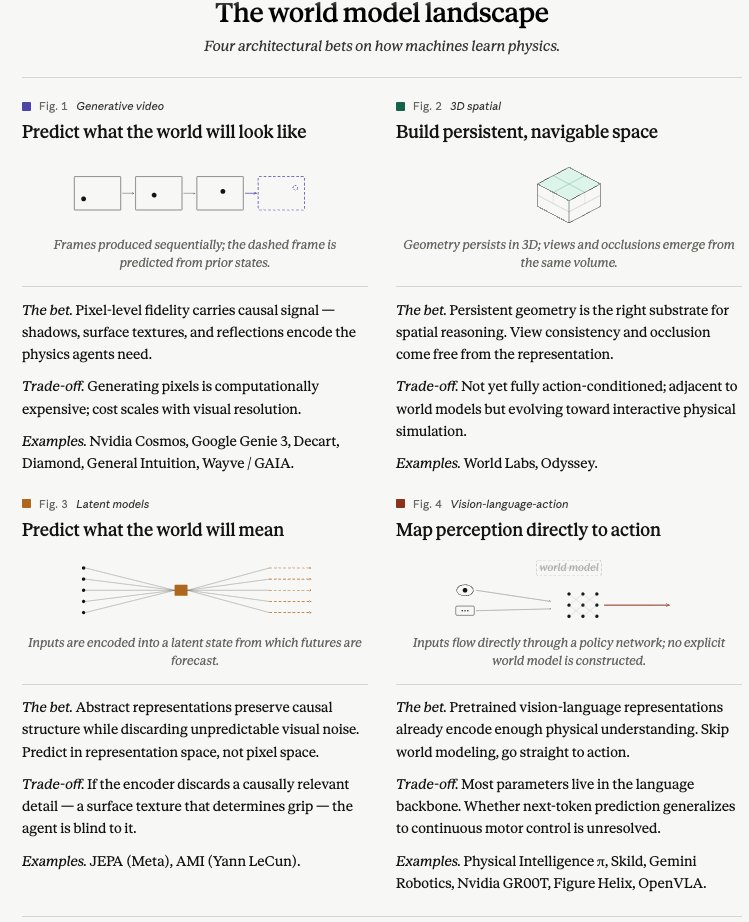
3️⃣ Latent world models predict what the world will mean rather than what it will look like. They compress away unpredictable visual variation without losing causal structure. Instead of generating the next frame, they forecast abstract representations of future states. They predict in representation space rather than pixel space. The advantage is compute efficiency and natural fit for agent training. The risk is compression loss. If the latent encoding misses a causally important detail, the agent cannot learn from what it cannot represent.
Examples: JEPA by @Meta , @ylecun's @amilabs
4️⃣ VLAs (Vision-Language-Action models) take the pragmatic robot-policy path. They skip building a world model from scratch. The bet is that pretrained vision-language representations already encode enough physical understanding that you can skip building a world model entirely and go straight to action.
Examples: @physical_int, @SkildAI,
@GoogleDeepMind Robotics, @nvidia GR00T, @Figure Helix, OpenVLA
It feels like world models are where LLMs were in 2019-21 window. Multiple architectures, no clear winner, and the training data problem is not yet solved.
The difference is that text was already on the internet. Action-conditioned physical data is not. This may be the bottleneck that decides which architecture wins.
What do you think?
In my last post I covered the compute and data requirements of world models. So.. what are world models?
There are at least four architectural paths emerging as far as I understand. Some predict future observations. Some build explorable spaces. Some learn compact latent dynamics. Some skip explicit world modeling and map perception directly to action.
1️⃣ Generative video world models predict observable futures. They generate what the world will look like in response to actions. Generative models bet that pixel-level fidelity carries causal signal. Subtle details like shadows and surface textures change agent decision-making. The trade-off is cost. Generating pixels is expensive.
Examples: @NVIDIA Cosmos, @GoogleDeepMind Genie 3, @DecartAI, Diamond, @gen_intuition, @wayve_ai /GAIA
2️⃣ 3D spatial models take a different approach. Instead of generating video frames, they construct persistent, navigable 3D environments. Their bet is that persistent geometry is the right substrate for spatial reasoning. If you have a persistent 3D representation, spatial relations do not have to be relearned implicitly from video every time.
Examples; @theworldlabs, @odysseyml