Very excited to launch BOLD 🚀
BOLD is a national shot at ambitious bluesky fundamental AI research in an academic setting, fully committed to open-source and open-science.
BOLD's mission are research bets that would reshuffle the deck in AI if true. It will also be a launchpad for fast-tracking the British and European tech scene.
Oh - and @FLAIR_Ox is no more.
Excited to share AIRA₂ — our next-generation AI Research Agents for ML that address key bottlenecks to scaling.
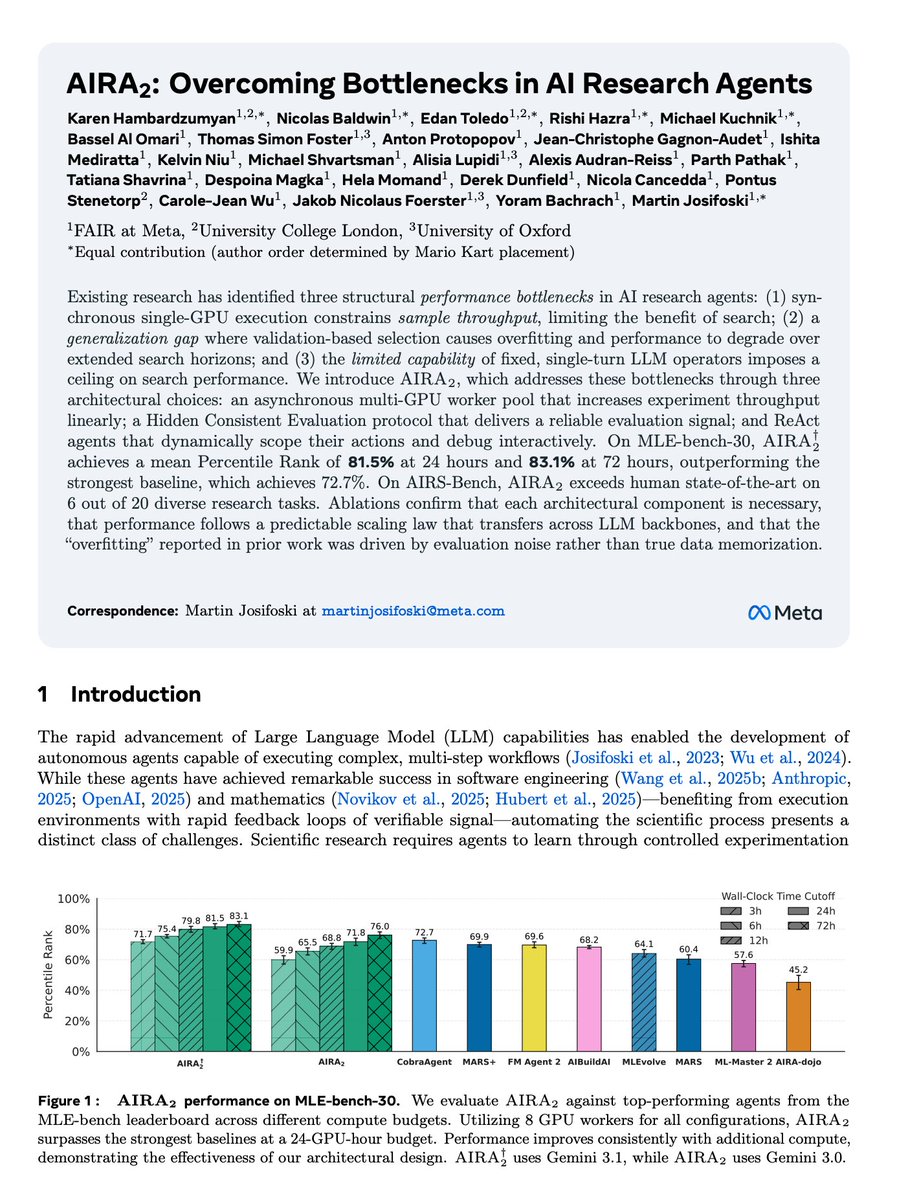
AIRA₂ achieves SoTA on real-world ML tasks from MLE-bench-30 (81.5% vs 72.7%), exceeds human SoTA on 6/20 diverse AI research tasks from AIRS-Bench (and hacks another 5), while exhibiting strong, predictable scaling properties.
To push the frontier of AI Research, we need systems that scale well. Developing AIRA₂, we learned a lot about the bottlenecks and what it takes to resolve them — insights already driving our next iteration:
1/
(🧵) Happy to release AIRS-Bench, a benchmark to test the autonomous machine learning abilities of AI research agents 🤖
AIRS-Bench includes 20 tasks sourced from machine learning papers that assess the autonomous research abilities of LLM agents throughout the full research lifecycle, from hypothesis generation 💡 and implementation 🛠️ to experimentation 🧪 and analysis 📊
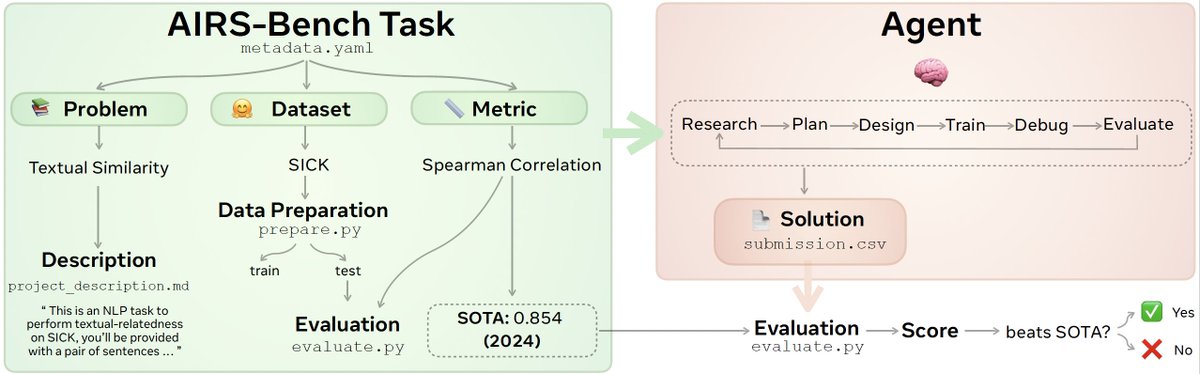
Each task is extracted from a paper with a state-of-the-art result and consists of a:
📝 problem description (e.g. text similarity)
🗂️ a dataset (e.g. SICK) and
📏 a metric (e.g. Spearman correlation) to optimise over
The agent is then given a GPU and 24 hours to develop and submit a Python solution that matches or exceeds the paper SOTA 📈
Read on for baseline results and examples of agents surpassing human SOTA 👀
🌱We open-source the AIRS-Bench task definitions and evaluation code to accelerate in autonomous scientific research:
💻 GitHub: https://t.co/UXzNXyGdU5
📜 ArXiv: https://t.co/badN0jq0IA
🤗 HF paper: https://t.co/6FIWxF0Bsw
📊 Meta AI website: https://t.co/wcIWLrlYBU
Huge shoutout to the team from Meta FAIR who painstakingly crafted, debugged and inspected every single of these tasks and its runs across more than a dozen of agents @alisia_lupidi, @_tomwithanh, @BhavulGauri, @basselralomari, @albertomariape, Alexis Audran-Reiss, Muna Aghamelu, Nicolas Baldwin, @LuciaCKun, @GagnonAudet, Chee Hau Leow, Sandra Lefdal, Abhinav Moudgil, Saba Nazir, Emanuel Tewolde, Isabel Urrego, @mahnerak, @ishitamed, @EdanToledo and @rybolos, @alex_h_miller, @j_foerst, @yorambac for their leadership and support
🚨TL;DR: Benchmarking for AI Scientists just got better!🚨
Everyone is excited about AI Scientists, but we don't have a large scale benchmark that evaluates automated (or augmented) AI research systems on the home turf of the machine learning community: Machine Learning benchmarks.
Meet AIRS-Bench, our attempt at filling this gap. We hope AIRS-Bench will help the community to improve the signal-to-noise ratio in the era of research agents and is an important step towards turning ML benchmarks into standardised tasks for AI research agents. This has implications beyond AI scientists and will also help address the replication crisis in ML.
The team has invested countless hours (human and GPU) selecting/constructing the tasks, running baseline agents, analysing the outcomes, and hardening the benchmark.
We are excited for the community to both expand on our initial task set and benchmark new agentic systems!