(🧵) Happy to release AIRS-Bench, a benchmark to test the autonomous machine learning abilities of AI research agents 🤖
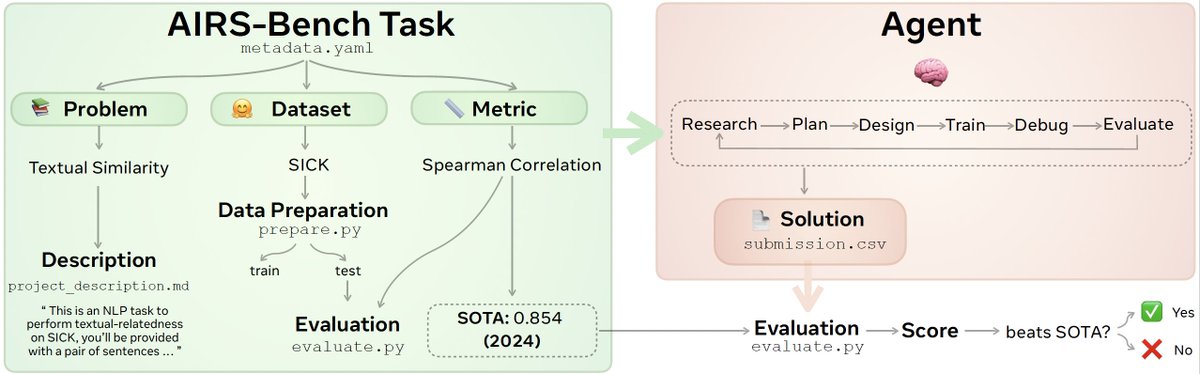
AIRS-Bench includes 20 tasks sourced from machine learning papers that assess the autonomous research abilities of LLM agents throughout the full research lifecycle, from hypothesis generation 💡 and implementation 🛠️ to experimentation 🧪 and analysis 📊
Each task is extracted from a paper with a state-of-the-art result and consists of a:
📝 problem description (e.g. text similarity)
🗂️ a dataset (e.g. SICK) and
📏 a metric (e.g. Spearman correlation) to optimise over
The agent is then given a GPU and 24 hours to develop and submit a Python solution that matches or exceeds the paper SOTA 📈
Read on for baseline results and examples of agents surpassing human SOTA 👀
🌱We open-source the AIRS-Bench task definitions and evaluation code to accelerate in autonomous scientific research:
💻 GitHub: https://t.co/UXzNXyGdU5
📜 ArXiv: https://t.co/badN0jq0IA
🤗 HF paper: https://t.co/6FIWxF0Bsw
📊 Meta AI website: https://t.co/wcIWLrlYBU
Huge shoutout to the team from Meta FAIR who painstakingly crafted, debugged and inspected every single of these tasks and its runs across more than a dozen of agents @alisia_lupidi, @_tomwithanh, @BhavulGauri, @basselralomari, @albertomariape, Alexis Audran-Reiss, Muna Aghamelu, Nicolas Baldwin, @LuciaCKun, @GagnonAudet, Chee Hau Leow, Sandra Lefdal, Abhinav Moudgil, Saba Nazir, Emanuel Tewolde, Isabel Urrego, @mahnerak, @ishitamed, @EdanToledo and @rybolos, @alex_h_miller, @j_foerst, @yorambac for their leadership and support
Hello world :)
We are BOLD — the British Open-ended Learning and Discovery Lab!
BOLD is a new academic research lab fully focussed on paradigm breaking discoveries in fundamental AI. We work towards more efficient & open AI that is built around human needs and capabilities.
To pursue these breakthroughs, we pioneer new modes of collaboration in academia that are more focussed, resourced, agile, and collaborative. Rather than fragmenting resources, today we are sunsetting 5 of the UKs leading AI labs to join forces under our joined scientific vision.
Our vision is centered around three pillars:
⚡ Beyond backpropagation – questioning the foundations of the field.
🤝 Human-centric learning & discovery – treating humans as core to our algorithms
🤖 Embodied learning – fast learning and adapting methods that deal with the messy real world
BOLD is backed by @UKRI_News and @EPSRC with £30M – and this is just the beginning. We are urgently looking for partners and sponsors to 10x this.
👉 https://t.co/eFVFW31mqz
👉 https://t.co/Eoad4G18KL
@j_foerst, @CULLYAntoine, @tonizza82, @shimon8282, @tonizza82, Ani Calinescu & @_rockt
Hey everyone — big day for us at Skiplabs: Skipper Beta is live 🚀
Skipper is a closed-loop coding agent. Instead of constantly going back and forth with the AI, you give it a spec and it iterates internally until it produces a working software service.
We believe this is where AI-assisted coding is heading, and we’re excited to finally share what we’ve been working on behind the scenes.
Start building with Skipper: https://t.co/XYooJgn0hp
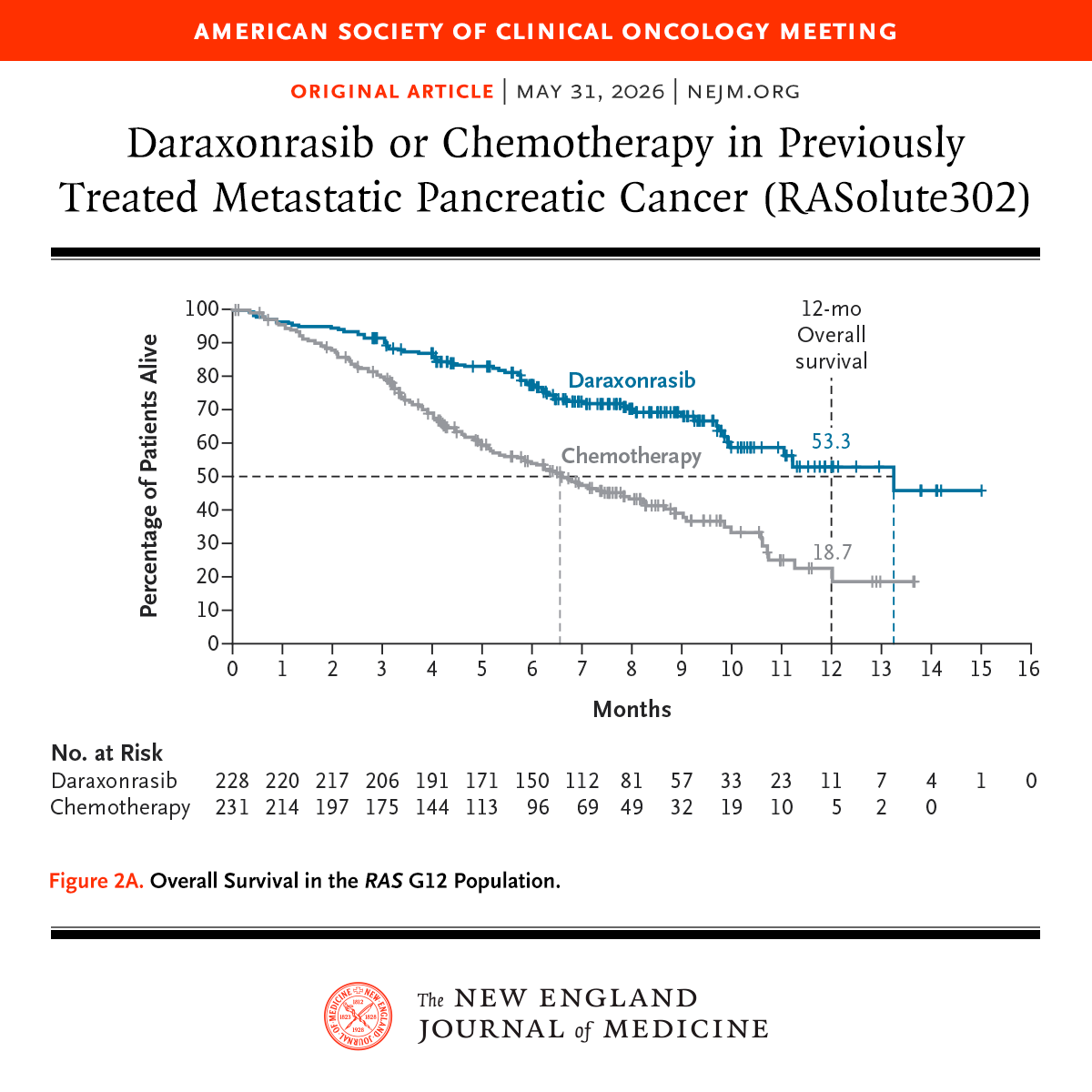
Presented at #ASCO26:
Among patients with previously treated metastatic pancreatic ductal adenocarcinoma, the RAS(ON) inhibitor daraxonrasib led to significantly longer overall survival and progression-free survival than chemotherapy. Full phase 3 RASolute 302 trial results: https://t.co/xwLWBZYRzq
@ASCO
Cheers, chills, and a standing ovation when RASolute 302 showed unprecedented survival on daraxonrasib for patients with progressive pancreatic cancer
Seldom do you sense you’re witnessing a historic moment in cancer care but this feels like ras targeting has arrived
#ASCO26
How can we help AI scientists train up their own LLM engine? I’m pleased to share our work on AI Research Agents discovering novel language modeling architectures, showing competitive performance when scaled up at the 1B parameter size: https://t.co/8oech1DPjQ
(🧵)Excited to share our latest work on AI Research Agents discovering novel language modelling architectures that show competitive performance when scaled up at 1B parameter size: https://t.co/IbW4LwMwu4
🤖 We gauge the ability of AI systems to autonomously design foundation models beyond the standard Transformer paradigm, by empowering LLM agents to perform both
🔍 high-level architecture search → AIRA-Compose
🛠️low-level mechanistic implementation →AIRA-Design
(8/🧵) In the https://t.co/fdQry3zdli task, agent-optimised pretraining code achieves 0.968 validation bits-per-byte surpassing the published minimum reference; experiments with select papers inserted into the context show that external literature occasionally helps
🤖📷𝐂𝐚𝐧 𝐀𝐈 𝐫𝐞𝐬𝐞𝐚𝐫𝐜𝐡 𝐚𝐠𝐞𝐧𝐭𝐬 𝐝𝐢𝐬𝐜𝐨𝐯𝐞𝐫 𝐭𝐡𝐞 𝐧𝐞𝐱𝐭 𝐠𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐨𝐧 𝐨𝐟 𝐟𝐨𝐮𝐧𝐝𝐚𝐭𝐢𝐨𝐧 𝐦𝐨𝐝𝐞𝐥𝐬? We put them to the test with two complementary, model-agnostic frameworks: 𝐀𝐈𝐑𝐀-𝐂𝐨𝐦𝐩𝐨𝐬𝐞 and 𝐀𝐈𝐑𝐀-𝐃𝐞𝐬𝐢𝐠𝐧 -- a thread:
Worried about Anthropic's Mythos? Fully formally verified code generation is the defense.
Combining Lean, frontier models, multi-agent scaffolds, and inference scaling, we show <12mo benchmarks jumping from 20% to 70%.
Real-world verification is here.
https://t.co/ADGXmJOLlZ
1/
🚀 Happy to see AIRS-Bench, an AI R&D benchmark that Meta open-sourced earlier this year (https://t.co/ttZYThznEl), being used in the Muse Spark Safety & Preparedness Report to assess loss of control risks stemming from acceleration of AI development.
AIRS-Bench (https://t.co/UXzNXyFG4x) measures the ability of AI agents to execute end-to-end AI R&D across the full research lifecycle, from idea generation 💡 and implementation 🛠️ to experiment analysis 🧪 and iterative refinement 📈
Along with SWE-Bench and MLE-Bench, AIRS-Bench was used to assess the risks of models automating AI R&D work and outpacing governance mechanisms. Our findings suggest that Muse Spark does not substantially contribute to the said threat, as it achieves performance superior to human researchers in only 5 out of 20 tasks and for a fraction of its attempts 🔍
This is inline with results from comparison models and highlights the models' limitations to execute the complete research lifecycle consistently and across a wide range of domains 🤖
Head over to the 158-page report for more detailed results and a wide range of assessments and mitigations under Meta’s Advanced AI Scaling Framework 👇
🚀 Muse Spark Safety & Preparedness Report for Meta AI is out.
We start with our pre-deployment assessment under Meta's Advanced AI Scaling Framework, covering chemical and biological, cybersecurity, and loss of control risks. Our assessment flagged potentially elevated chem/bio risk, so we implemented safeguards and validated mitigations before deployment - bringing residual risk to within acceptable levels.
Beyond the Framework, we also share findings and early explorations of model behavior (honesty, intent understanding, etc.), jailbreak robustness, eval awareness, and more.
We're sharing this report to give a closer look at how we evaluate advanced AI safety. Always more work to do, and we welcome feedback from the community.
https://t.co/azpKHwu7x9
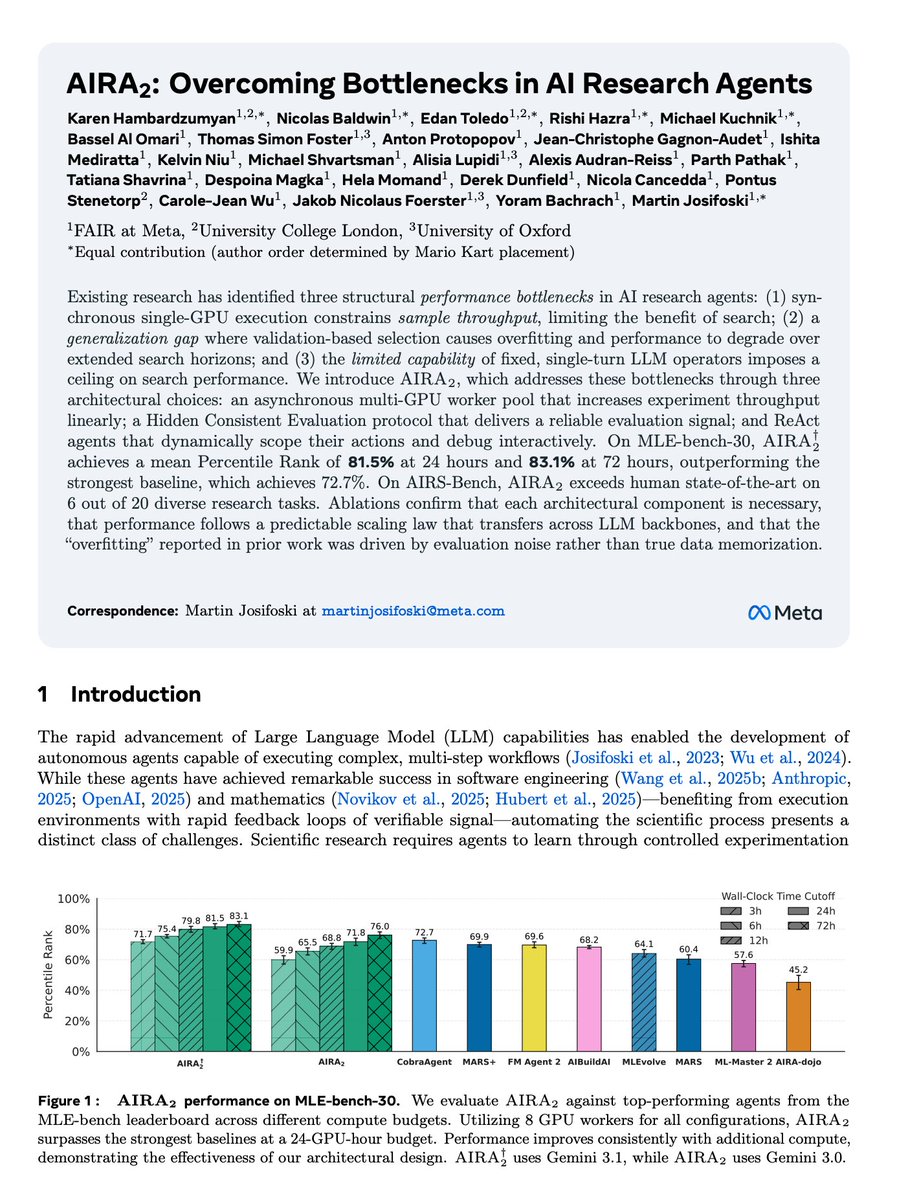
Excited to share AIRA₂ — our next-generation AI Research Agents for ML that address key bottlenecks to scaling.
AIRA₂ achieves SoTA on real-world ML tasks from MLE-bench-30 (81.5% vs 72.7%), exceeds human SoTA on 6/20 diverse AI research tasks from AIRS-Bench (and hacks another 5), while exhibiting strong, predictable scaling properties.
To push the frontier of AI Research, we need systems that scale well. Developing AIRA₂, we learned a lot about the bottlenecks and what it takes to resolve them — insights already driving our next iteration:
1/