Every "free" resume builder on the internet runs the same scam.
They let you build. They let you write. They let you spend two hours picking fonts, adjusting margins, perfecting bullet points.
Then you click "Download PDF."
$15.
Your words. Your experience. Your career history. Locked behind a button that says "Upgrade to download."
You wrote the document. They own the export.
https://t.co/5unSB7LA9q does this. Zety does this. Novoresume does this. Enhancv does this. Every single one.
Zety is the worst. Sign up for a $2.99 "trial." Get charged $23.70 the next month. Automatically. No warning. Their Trustpilot page reads like a crime scene. Thousands of job seekers. Already stressed. Already broke. Fighting to cancel a subscription they never meant to start.
One developer decided this was wrong.
His name is Amruth Pillai. Indian. Self-taught. He watched millions of people get trapped by the same paywall on every resume site on the internet.
So he built one without a paywall. No trick. No trap. No "free tier" that expires. No premium templates locked behind a credit card. No auto-renewing trial buried in fine print.
He called it Reactive Resume. Then he gave it to the world.
36,000+ stars on GitHub. Almost 1 million resumes built. MIT licensed. Free since day one.
→ Professional templates. Every one ATS-friendly by default.
→ Real-time preview. See your resume change as you type.
→ Export to PDF. One click. No paywall. No watermark.
→ No account required to start.
→ Drag-and-drop sections. Rearrange everything.
→ Custom colors, fonts, spacing, layouts.
→ Multiple resumes. Tailor each for each job.
→ Share a live link with any recruiter.
→ AI writing assistant for summaries and descriptions.
→ 30+ languages.
→ Self-host with Docker.
→ Try it now. https://t.co/qih5d8FzaU. No signup.
Here's the part the paid builders do not want you to know:
75% of resumes are thrown away by ATS software before a human ever sees them. Not because the person was unqualified. Because the format was unreadable by the machine.
The paid builders know this. They put ATS-optimized templates behind the premium paywall. They know your free template will fail the scan. They wait for you to get rejected. Then they sell you the fix.
Every Reactive Resume template passes ATS by default. No upgrade needed. No premium tier. The fix is free.
https://t.co/5unSB7LA9q: $25/month.
Zety: $2.99 trial. $23.70/month after.
Novoresume: $19.99/month.
Reactive Resume: $0. No paywall. No auto-renewal. No trap. Every feature. Forever.
One Indian developer built what a billion-dollar industry charges monthly for. Then he open sourced it.
Your resume. Your words. Your future. No scam in between.
100% Open Source.
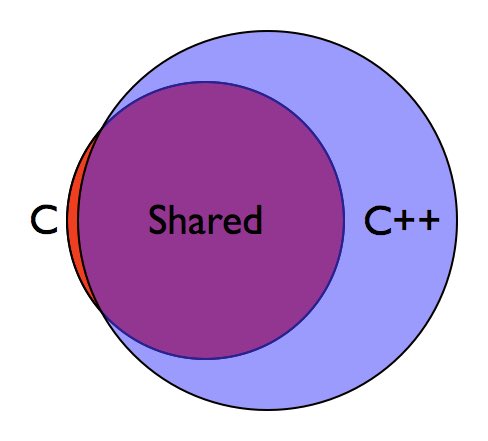
Stop saying C/C++
C++ is not a strict superset of C. No it’s just “C with classes”. Not anymore.
This diagram perfectly illustrates the relationship between two languages.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Terrifying fact: we figured this out at Google and it was part of why we stopped the program. The folks who left the program to start Starlink knew all this.
Horrifying out of Microsoft. The false positive rate won't be exactly pretty...
I wouldn't be surprised if this results in quite some communications in affected orgs being moved to other channels...
This formula—and a general recipe for uniformly sampling from 2-dimensional shapes—can be found in the excellent article,
Jim Arvo
"Stratified Sampling of 2-Manifolds"
SIGGRAPH Course Notes (2001)
https://t.co/KwajsOrze9
3/3
Intuitively: in the first formula, there are about as many points concentrated in a small annulus around the middle as there are in a large outer annulus.
The second formula effectively corrects for the circumference of the annulus, by "warping" samples in the r direction. 2/3
I taught this in my game engines class a couple weeks ago in the context of particle emitters. Extending to a solid unit sphere, you pick two random angles and take the *cube* root of a random radius.
@joeabrah I've been following your course "Getting Started with Endpoint Log Analysis" on Pluralsight. It's pretty fun! Unfortunately, I can't seem to log in to the pre-built VMs you've provided. Could you please help me?
@joeabrah @joeabrah, thanks for the quick response! I'm still a VMware Player newbie, and I'm looking for the VM's IP, to access Kibana. I'm also not sure the instructions in the class notes - "Import the VM and change the virtual network adapter to match". I appreciate any guidance.