Our new model Ink-2 tops AA's leaderboard for streaming speech-to-text!
Ink-2 comes with plenty of features optimized for real-time voice agents. With top-class models for both TTS and STT, the team at @cartesia keeps pushing the frontier of models for interactive intelligence.
Ink-2 is our first streaming ASR model, built specifically for realtime voice agents - and it's #1 on @ArtificialAnlys on day 1!
It's rare for models to be #1 on the first try on a new benchmark, since model development is iterative and there's so much that goes into understanding quality. We've seen great results internally and can't wait for everyone to try it!
Cartesia Ink-2 debuts as #1 for accuracy on the brand-new streaming speech-to-text leaderboard from @ArtificialAnlys! We designed Ink-2 from the ground up for voice agents - with low latency, eager transcripts, and semantic endpointing.
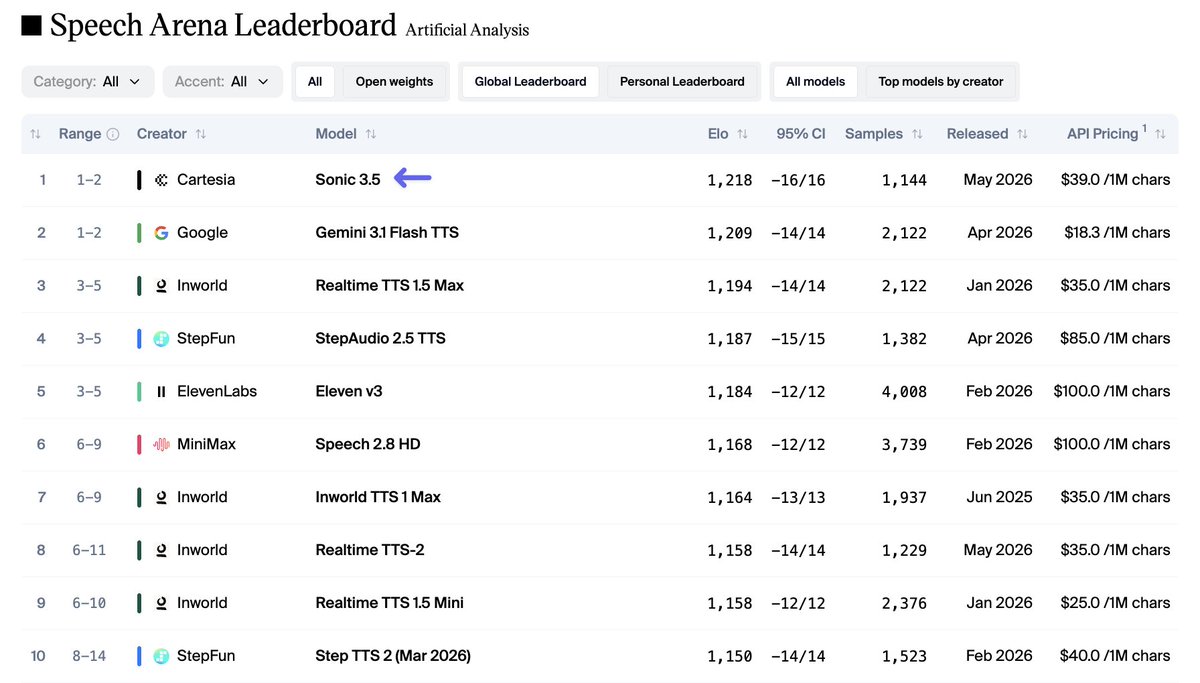
Sonic 3.5 is now the #1 text to speech model on the @ArtificialAnlys leaderboard!
You no longer have to trade off quality and latency - Sonic 3.5 also has the fastest time to first audio at 82ms end to end.
See full benchmark results 👇
Sonic 3.5 is now the #1 TTS model on @ArtificialAnlys, an independent benchmark of TTS quality! It's also the fastest model with 82ms end to end latency - it's always been our dream to build realtime voice with no trade-offs.
Building great models comes from getting the fundamental right - infrastructure, architecture, data, and evals - and I'm proud to see the hard work for the team recognized!
Cartesia’s Sonic-3.5 takes the #1 spot on the Artificial Analysis Speech Arena Leaderboard, surpassing Inworld Realtime TTS 1.5 Max and Google’s Gemini 3.1 Flash TTS
Sonic-3.5 is the latest TTS model from @cartesia . It supports 42 languages, including 9 Indian languages, with 500+ voices available out of the box. The model has been highly preferred among voters in the TTS Arena, with its demonstrated naturalness and accurate transcript following.
Key takeaways:
➤ Quality: Sonic-3.5 has an Elo score of 1,218 (+16/-16) based on 1,144 arena appearances, placing it ahead of Inworld Realtime TTS 1.5 Max at 1,194 and Gemini 3.1 Flash TTS at 1,209
➤ Pricing: Sonic-3.5 is priced at $39/1M characters, a premium compared to Gemini 3.1 Flash TTS at $18.3/1M characters, and Inworld Realtime TTS 1.5 Max at $35/1M characters
➤ Speed: 105.5 characters per second, compared to 205 characters per second for Inworld Realtime TTS 1.5 Max and 26.3 characters per second for Gemini 3.1 Flash TTS
See more details and listen to samples below 🧵
Mamba-3 is out! 🐍
SSMs marked a major advance for the efficiency of modern LLMs.
Mamba-3 takes the next step, shaping SSMs for a world where AI workloads are increasingly dominated by inference.
Read about it on the Cartesia blog:
https://t.co/dIWg3iXfay
The frontier has increasingly shifted to hybrid models - from Qwen to Kimi-Linear and now with NVIDIA's Nemotron-3 Super - that rely on a strong linear sequence model. Today we release Mamba-3, the most powerful linear model to date.
https://t.co/OpMmqEWMkP
The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti@kevinyli_@_berlinchen@caitWW9, and of course @tri_dao!
Evo 2, our genome language model that generalizes:
- across biological prediction and design tasks,
- across all modalities of the central dogma,
- across molecular to genome scale, and
- across all domains of life,
is published today in @Nature.