There is an alternate reality where Cray took their vector supercomputers, ditched FP64 calculations, and went with one FP32 pipe and a BF16 tensor core pipe. The same instruction set, memory architecture, and vector registers would have made a sweet deep learning machine, in many ways nicer than SIMT CUDA programming on GPUs. A Y-MP class machine like that could have delivered the AlexNet and DQN moments two decades earlier.
Even doing everything in FP64 with no architectural changes, a Cray-1 would have been the best machine in the world for neural networks. If @geoffreyhinton had access to one for early research, the case could have been made for the architectural modifications to 10x the performance.
🌟We have had an amazing time at #RISCVSummitEurope so far! Watch #RISCV Ambassador @FlorianWoh's #recap video, highlighting a few of the incredible Summit announcements, sessions, and activities. We can't wait to see everyone for another packed day tomorrow! #RISCVeverywhere
In order to put to rest incorrect information that recently appeared on social media and several more prominent websites, we have published a summary of our project Occamy: https://t.co/GMps7YYIcB
We’re thrilled to share that we have closed our $27million Series A and are ready to launch our AI acceleration platform in early 2023! https://t.co/5PGK6KfUjj
#deeptech#ai#ml#edgeai
@pulp_platform That’s amazing 😍! Looking at the etron homepage I think you are on the path for the smallest Linux-booting RISC-V system. Looking forward to first alive terminal pictures!
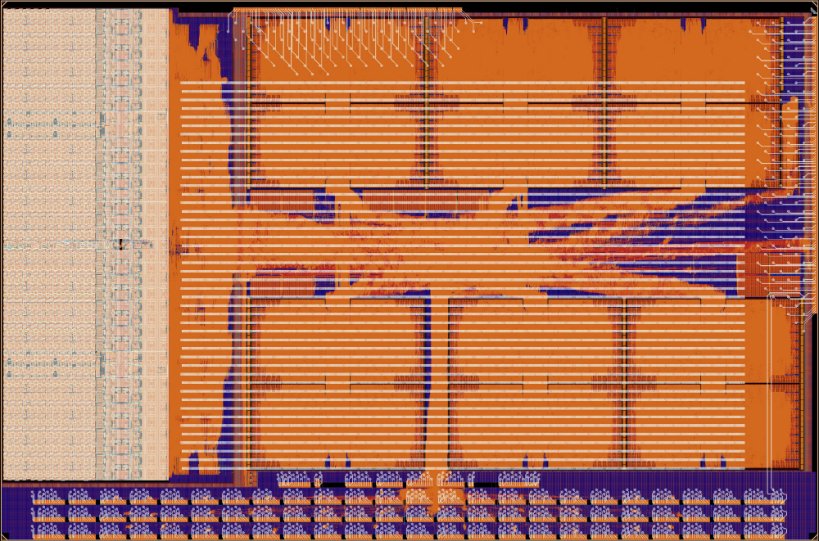
Here is Occamy: 216 Snitch cores, an HBM controller in GF12LPP, designed as a chiplet. Enough said 😇🦉. This work wouldn't be possible without the generous support of @GlobalFoundries and @rambusinc. https://t.co/mdsCEhAD8y
Found another chip that is manufactured in Intel 4. This is a 8-core RISC-V (RV64GC) CPU with compute near LLC called Vela.
- 64 kB SRAM for each core
- 512 kB shared LLC
- the silicon is just 1,92 mm² (1,939 x 0,991 mm)
Hello (ex) @pulp_platform's Ariane/@openhwgroup's CVA6!
Thanks to Massimiliano.G's LiteX port, it's possible to regain some freedom:
- No longer restricted to Xilinx/Genesys2/MIG.
- New peripherals to play with :)
- 100% open-source SoC!
- ...
Try it: litex_sim --cpu-type=cva6
@bilalzafar@LucaBeniniZhFe@pulp_platform@niwist And I would make sure from the beginning that large state holding elements (e.g., predictors) could be implemented as SRAMs, so can cope with at least one cycle latency
@bilalzafar@LucaBeniniZhFe@pulp_platform@niwist I would group functional units into fixed latency (alu, fp, etc.) and variable latency (lsu, div). For the fixed latency you can be more lean and clever about your implementation because you know exactly when the result will be produced. While in Ariane everything is handshaked
@_O_N_LANG__ Hey! As of now we manage everything via GitHub (issues). We are happy to help out there! We don’t (yet) have any instant messaging for the public 😕