I’m a psychiatrist.
In 2025, I’ve seen 12 people hospitalized after losing touch with reality because of AI. Online, I’m seeing the same pattern.
Here’s what “AI psychosis” looks like, and why it’s spreading fast: 🧵
5/5 Best practice: Test multiple models, get feedback from domain experts, and evaluate based on objective results for your particular needs. No single metric can capture the full picture of an LM's capabilities.
1/5 The recent LMSYS study on chatbot rankings shows why we shouldn't rely too heavily on any single metric for language models. They found significant shifts in rankings when controlling for "style" vs "substance" in responses.
Does style matter over substance in Arena? Can models "game" human preference through lengthy and well-formatted responses?
Today, we're launching style control in our regression model for Chatbot Arena — our first step in separating the impact of style from substance in rankings.
Highlights:
- GPT-4o-mini, Grok-2-mini drop below most frontier models when style is controlled
- Claude 3.5 Sonnet, Opus, and Llama-3.1-405B rise significantly
- In Hard Prompts, Claude 3.5 Sonnet ties for #1 with ChatGPT-4o-latest. Llama-405B climbs to joint #3.
More analysis in the thread below👇
4/5 The takeaway? Don't choose an LM based solely on leaderboards or benchmarks. What matters is how well it performs on YOUR specific tasks and use cases.
What can you do with Llama quality and Groq speed? You can do Instant. That's what. Try Llama 3.1 8B for instant intelligence on https://t.co/JFfJs01nUJ.
We re-ran SEAL evals on the new @AnthropicAI Claude 3.5 Sonnet model.
It is now:
- 🥇 #1 on Instruction Following
- 🥇 #1 on Coding
Congratulations to Anthropic on a great new model!
P.S. we’re adding new evals to SEAL, so if you have an idea for an eval, let us know below 👇
pretty cool approach
1. use LLMs to extract a knowledge graph from your sources
2. cluster this graph into communities of related entities at diff levels of detail
3. for RAG, map over all communities to create "community answers" and reduce to create a final answer
I've done a deep dive into SB 1047 over the last few weeks, and here's what you need to know:
*Nobody* should be supporting this bill in its current state. It will *not* actually cover the largest models, nor will it actually protect open source.
But it can be easily fixed!🧵
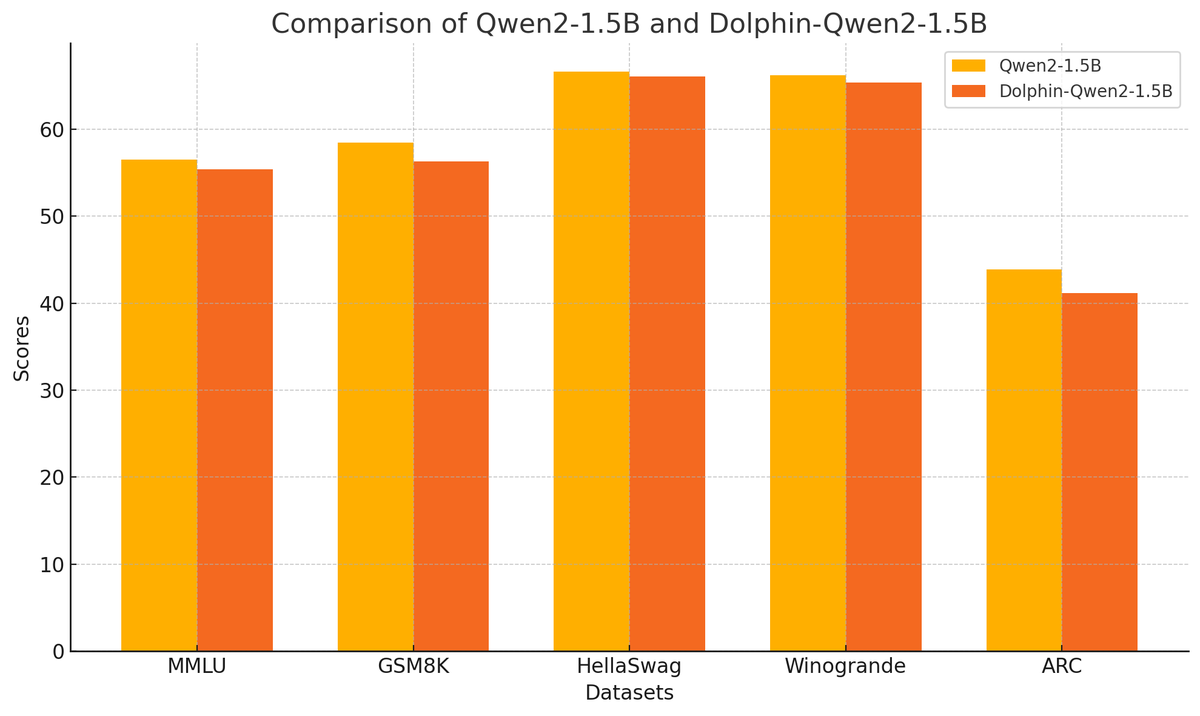
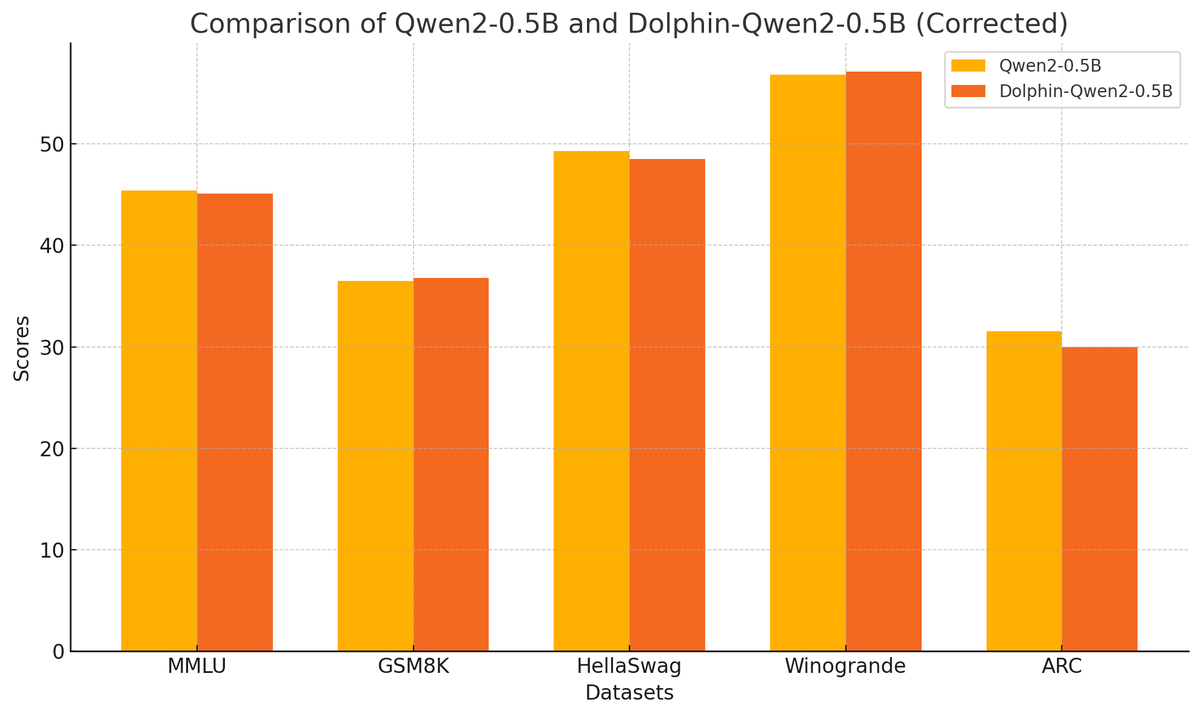
Cognitive Computations presents: Dolphin-2.9.3-qwen2-0.5b and Dolphin-2.9.3-qwen2-1.5b
Two tiny Dolphins that still pack a punch! Run it on your wristwatch or your raspberry pi! We removed the coding, function calling, and multilingual, to let it focus on instruct and conversation. Thanks to the team @TheEricHartford, @latkins, @FernandoNetoAi, and compute sponsor @CrusoeAI and our inference sponsor @OnDemandai! Thanks to @Alibaba_Qwen for the excellent base model! Uncensored models say mean things, if instructed to. You are responsible for content you create using it.
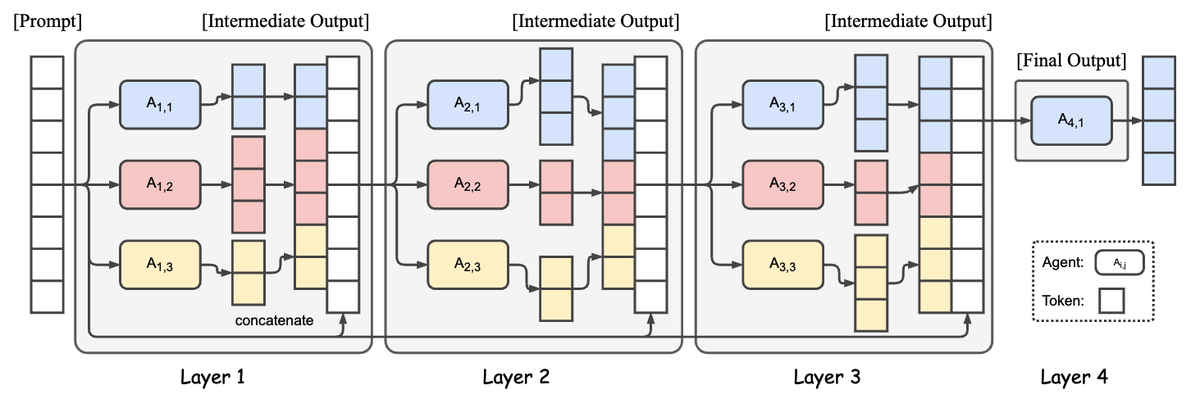
Mixture of Agents—a framework that leverages the collective strengths of multiple LLMs. Each layer contains multiple agents that refine responses using outputs from the preceding layer.
Together MoA achieves a score of 65.1% on AlpacaEval 2.0.
https://t.co/XCXY5ZZgbx
Introducing RAGApp 💫
A no-code interface to configure a RAG chatbot, as dead-simple as GPTs by @OpenAI.
It’s a docker container that’s easily deployable in any cloud infrastructure. Best of all, it’s fully open-source 🔥
1️⃣ Setup the LLM: Configure the model provider (OpenAI, Gemini)
2️⃣ Setup the data: Define the system prompt and upload your knowledge base.
3️⃣ Launch the chatbot both via the UI or API
4️⃣ If via the UI, stream intermediate events and also sources!
This is fantastic work by @MarcusSchiesser and is built upon the same DNA as our create-llama project.
Check out RAGApp today: https://t.co/6QXEF8D9Lx
10/ As the AI industry grapples with SB 1047's implications, stakeholders must closely examine the bill's provisions and consequences. The balance between responsible AI development and fostering innovation will be central to the ongoing discourse surrounding AI regulation.
9/ SB 1047's stringent regulations and potential impact on AI innovation may drive research and development to other states or countries with more favorable regulatory environments, such as Texas or the United Arab Emirates, threatening California's position as an AI hub.
8/ The bill sparks debate over whether responsibility should lie with AI developers creating general-purpose tools or with end-users misusing these tools for harmful purposes, drawing comparisons to other software like Photoshop.
7/ Developers face severe penalties under SB 1047, including injunctions, damages up to 30% of revenue, and model shutdowns. The bill also expands criminal perjury for knowingly lying in safety reports, creating significant legal risks for AI companies.
6/ SB 1047's broad definitions of "covered models" (those trained with >10^26 operations) and "hazardous capabilities" could hinder innovation, particularly for startups and smaller AI companies navigating vague regulations.
1/ California's SB 1047, the "Safe and Secure Innovation for Frontier Artificial Intelligence Models Act," passes Senate, raising concerns over innovation, competition, and free speech. The bill categorizes AI models, imposes requirements, and sets penalties...