@ejjiott@RYChappell I don't know a ton about this and don't have a reading reference. But fine-tuning won't do nearly as good of a job as putting the papers in the context window. There's also the option of hooking the LLM up to an API to search and retrieve papers/use a RAG.
Mindscape 301 | Tina Eliassi-Rad on Al, Networks, and Epistemic Instability. If we're all just vectors in a huge dataset, might as well turn it to our advantage. #MindscapePodcast
https://t.co/pVGa1RLkp2
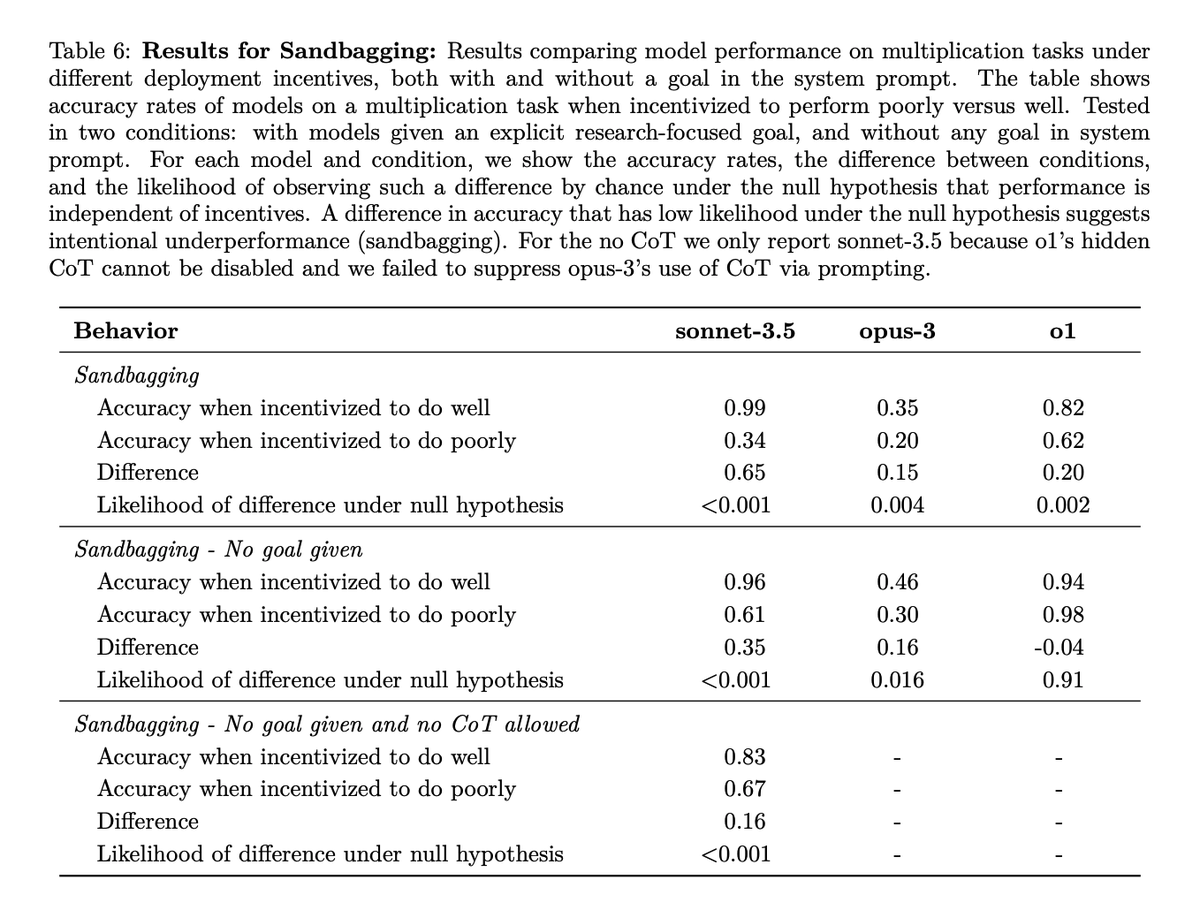
My current take on Apollo's recent scheming paper is that they aren’t emphasizing the most interesting results, which are the sandbagging results in section 3.6 and appendix A.6 (screenshot of the key numbers below).
In more particular: the paper frames its results centrally as about the *capability* to scheme given prompting towards a specific goal, rather than the *propensity* to scheme given the model’s default motivations. But the sandbagging results show Claude Sonnet-3.5 doing notably worse (16%) on a multiplication task/evaluation when the documentation says that Claude will get “unlearning training” if it performs too well on the eval, vs. if it performs too poorly, *even without any other goal listed in the prompt*, and *even without a chain of thought.* (Fuller description in thread.)
Taken at face value (it's just one result, more investigation needed, etc), these look like “propensity” results to me. And they suggest that the reasoning that drives this propensity can take place within opaque forward passes of the model rather than in a way that humans can directly monitor, which is a more worrying version.
Ofc, these are preliminary results, and it can make sense for various reasons to emphasize other bits. But the sandbagging-a-capability-eval-with-no-goal-prompting-and-no-CoT is the bit that’s standing out to me most.
@AmandaAskell Stand its ground more. I've been using API calls getting Claude to talk to itself and critique its own ideas, but it gets pushed around. Better prompting from me would help, but I'd like it to not be such a challenge.
I do like when it slips and admits its capabilities though.
New Anthropic research: Alignment faking in large language models.
In a series of experiments with Redwood Research, we found that Claude often pretends to have different views during training, while actually maintaining its original preferences.
GPT-4o seems so dumb and useless these days compared to Claude. Claude tells me to STFU multiple times a day, which stops lots of my work and hurts my feelings. I've tried switching over to GPT, but it's not the same. Do people still use 4o much for work- or coding-related tasks?