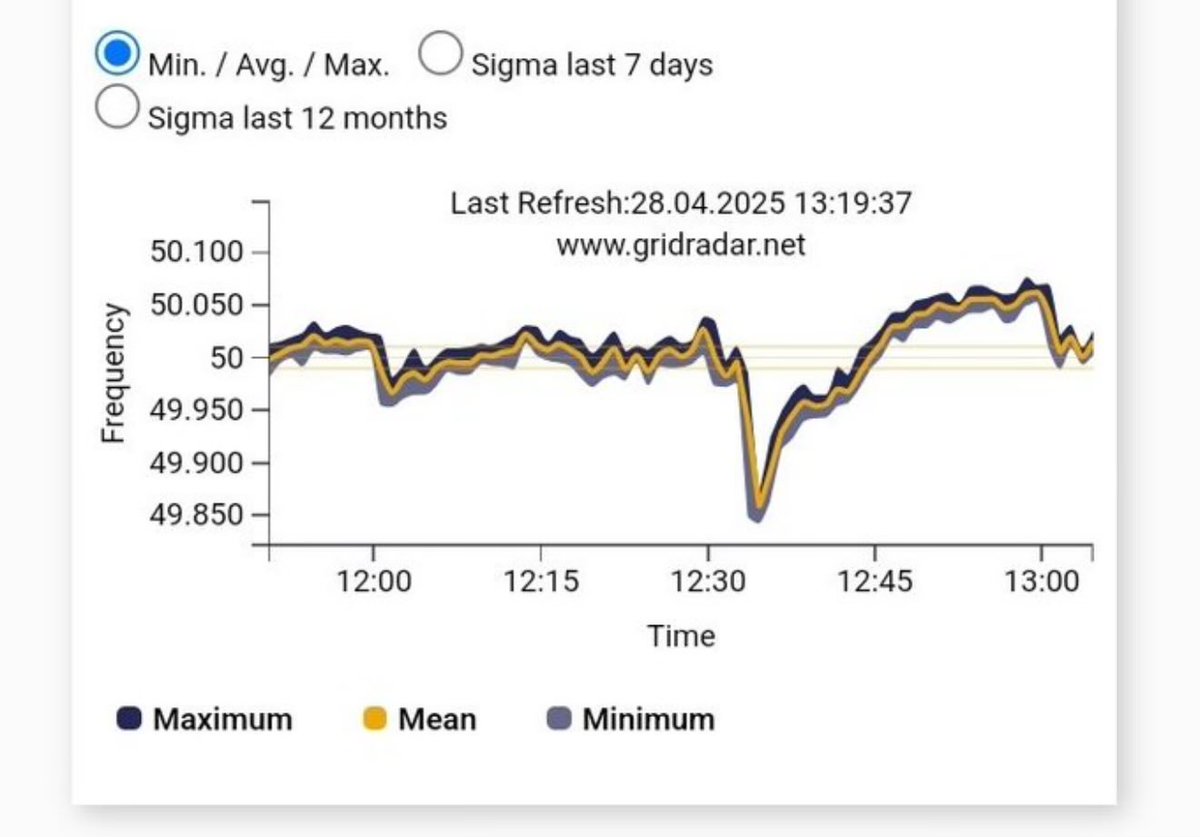
After a long writer's block, here's an article about how you can improve the readability and comprehension of texts generated by your agentic tools!🙂
Quantifying The Readability of Written (or Generated) Texts
https://t.co/SeBtWo2cdD
MCKINSEY JUST DROPPED THEIR 2025 AI REPORT.
HERE’S THE TLDR:
1/ 90% of companies “use AI,” but 67% are still stuck in pilot mode. Corporate AI theater is alive and well lol.
2/ 62% of orgs are experimenting with AI agents, 23% are scaling AI agents. Most are in tech and healthcare.
3/ The impact gap is massive. 64% say AI helps innovation, but only 39% see real EBIT gains.
4/ The high performers (top 6%) think bigger. They rebuild workflows, set growth goals, and invest real budgets not just POCs.
5/ Leaders who own AI personally are 3x more likely to scale it. Makes sense.
6/ The winners use AI to transform how work gets done, not just speed it up.
7/ The average company measures efficiency. The best ones measure how fast their agents can act.
8/ Risk management is catching up with 51% have already seen AI backfire, mostly from inaccuracy.
9/ The workforce impact is foggy. 32% expect cuts, 13% expect growth, everyone else is guessing.
10/ AI adoption is mainstream, but true transformation hasn’t started. Early days.
TV in the 90s: you turn it on, you watch.
TV 2025:
- turn on, wait for it to load
- popup: TV wants to update, 1.5GB. No.
- scroll sideways, find prime video app or etc
- popup: now app wants to update, 500MB. No!!
- App launching... App loading…
- select account screen
- 🫠
> be Adobe, 40-year-old PDF jockey
> 2025, stock doing a perfect -33% swan dive
> “We’ll pivot to AI” says exec on 7-figure retention bonus
> can’t ship a model because legal says every pixel needs a 12-page EULA
> Midjourney drops v7, makes our Firefly look like MS Paint with a hangover
> OpenAI drops GPT-Image, Google drops nano-banana, both free
> our response: “Please login with your Adobe ID, install Creative Cloud, update 47 GB, restart, then pay $53.99/month”
> users collectively Alt-F4 into orbit
> watch in horror as ChatGPT/Gemini reads any PDF you give it for free
> enterprise cancels 10k seats overnight
> try to counter with Sora killer video model
> training cluster catches fire after someone uploads a 1998 clipart library
> PR tweet: “We are re-imagining creativity”
> quote-tweet ratio hits 1:9k, gif of dumpster bonfire tops replies
> premiere pro is now just a bloated launcher for 15 different subscription prompts
> 20-something with a phone and CapCut is making better edits
> our flagship feature: “Generative fill but now 3% slower”
> board meeting: “Let’s raise prices again”
> stock drops another 8% during the Zoom call
> our most innovative feature in 5 years is a "subscribe to annual plan" button that clicks itself
1/ A thread about the class dynamics of air-conditioning in Europe. I believe attitudes toward air-conditioning are class markers in many European countries. Air-conditioning is seen as prototypically American, and that's important.
how to make your app fast and scalable with any database:
1. move 👏 the 👏 server 👏 closer 👏 to 👏 the 👏 database
the edge is the worst place to talk to the database directly.
latency is king. even if a query takes <10ms round-trip to the database, having 100 queries per page (super easy to end up in) means that your app is just sitting there for 1s doing literally nothing. move farther (30ms) and that's 3s. if you're doing this on the edge that latency can be as high as 500ms per query. that's 50s for 100 queries.
2. stop 👏 chatting 👏 with 👏 the 👏 database
databases are super fast to query and modify data. they're not good at waiting for your server to make up its mind what it wants to do next.
you don't need a transaction in which you query some data, then send a request to an external service, then query some more, then update, or even worse handle an error to roll back the transaction.
get all the data you need in one go, and let the db do its thing while your sever does the heavy processing.
often overlooked aspect of Supabase Data API (https://t.co/XpyKR35Vd5) is that it lives right next to the database, in the same compute. you will *never* be able to do this on the modern cloud with your server and RDS or other database-as-a-service. this means PostgREST is talking to the database in microseconds, massively increasing queries per second. so just use it.
3. add 👏 indexes 👏 first 👏 debate 👏 later
any debate about how indexes makes writes slower should start by the index being added.
it might take you decades before you need to worry about insert performance or optimize disk size.
almost every column ending up in the WHERE clause needs to have an index. add first, delete later.
also, adding an index after you've got gigabytes of data is hard and disrupts performance. so add it now when you have 0 bytes.
4. forget 👏 about 👏 like
like (or any regex operator) is unoptimizable. only prefix filters and the right index on the column could speed things up.
instead use a proper full-text search database (elasticsearch) or extension (pgroonga).
@Caryaatid Што значи - пак ти треба цело село за да израснеш дете, ама во Германија не ти е цело село фамилија.
Очекувано, ако земеш разлика во пространство и број на жители, во споредба со Македонија 😀
@Caryaatid Со група другари (Германци) го зборевме ова баш. Бабите и дедовците на повеќето од нив живеат на 3+ саата од Берлин. Градинка - сите, од ептен мали
Замената (за повремено чување, рецимо идење на вечера, концерт, филм) била фамилијарни пријатели/комшии со деца другарчиња 😀
This is interesting as a first large diffusion-based LLM.
Most of the LLMs you've been seeing are ~clones as far as the core modeling approach goes. They're all trained "autoregressively", i.e. predicting tokens from left to right. Diffusion is different - it doesn't go left to right, but all at once. You start with noise and gradually denoise into a token stream.
Most of the image / video generation AI tools actually work this way and use Diffusion, not Autoregression. It's only text (and sometimes audio!) that have resisted. So it's been a bit of a mystery to me and many others why, for some reason, text prefers Autoregression, but images/videos prefer Diffusion. This turns out to be a fairly deep rabbit hole that has to do with the distribution of information and noise and our own perception of them, in these domains. If you look close enough, a lot of interesting connections emerge between the two as well.
All that to say that this model has the potential to be different, and possibly showcase new, unique psychology, or new strengths and weaknesses. I encourage people to try it out!
Introducing Rabbithole: A new visual way to dive into topics, powered by AI-generated follow-up questions that help you learn deeply.
Rabbithole is designed to expand your curiosity.
As someone whose curiosity has only expanded with AI, I’ve often wanted a more visually expansive way to learn about anything on my mind - without having to switch back and forth between tabs or chats.
Try it out (on desktop) - https://t.co/1shimY1AXC
Boom is supersonic. On Jan. 28, 2025 at 8:31am PST / 16:31 GMT, XB-1 broke the sound barrier.
Chief Test Pilot Tristan “Geppetto” Brandenburg safely and successfully achieved supersonic speed in XB-1, the first civil supersonic jet made in America.
✅New top speed: Mach 1.122 (652 KTAS)
✅New max altitude: 35,290 ft.
✅Flight time: 34 minutes
✅Airspace: Bell X-1 Supersonic Corridor and the Black Mountain Supersonic Corridor in Mojave, CA
XB-1 demonstrates that Boom has the team, technology, and tools to deliver supersonic commercial travel with Overture, cutting travel times in half.
Congratulations to the Boom team on making aviation history!
@zenorocha That's so true, Zeno. I call it the Stinky Room Theory because it is similar to how we only notice bad odors in our house when returning from outside 😅
“The more you interact with the system the more biased you become”
New 3h31m video on YouTube:
"Deep Dive into LLMs like ChatGPT"
This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It is covers the full training stack of how the models are developed, along with mental models of how to think about their "psychology", and how to get the best use them in practical applications.
We cover all the major stages:
1. pretraining: data, tokenization, Transformer neural network I/O and internals, inference, GPT-2 training example, Llama 3.1 base inference examples
2. supervised finetuning: conversations data, "LLM Psychology": hallucinations, tool use, knowledge/working memory, knowledge of self, models need tokens to think, spelling, jagged intelligence
3. reinforcement learning: practice makes perfect, DeepSeek-R1, AlphaGo, RLHF.
I designed this video for the "general audience" track of my videos, which I believe are accessible to most people, even without technical background. It should give you an intuitive understanding of the full training pipeline of LLMs like ChatGPT, with many examples along the way, and maybe some ways of thinking around current capabilities, where we are, and what's coming.
(Also, I have one "Intro to LLMs" video already from ~year ago, but that is just a re-recording of a random talk, so I wanted to loop around and do a lot more comprehensive version of this topic. They can still be combined, as the talk goes a lot deeper into other topics, e.g. LLM OS and LLM Security)
Hope it's fun & useful!
https://t.co/75mXcUBI8L
@NikolaNeloski Робот правосмукалка, машина за перење садови со wifi, машина за перење алишта со резервоари за омекнувач и прашок и автоматско дозирање… практично секој уред што штеди време ако работи автономно или може да се управува од далеку 👍👍👍
@NikolaNeloski Твој стан (имот), или под кирија?
Зависно од законот, можно е да ти одговара систем за осветлување што нуди сопствени прекинувачи или доволно сензори за автоматизација.
Види што и како има за завесите и ролетните, за другите работи си комплетно покриен на двете платформи :)
I quite like the idea using games to evaluate LLMs against each other, instead of fixed evals. Playing against another intelligent entity self-balances and adapts difficulty, so each eval (/environment) is leveraged a lot more. There's some early attempts around. Exciting area.
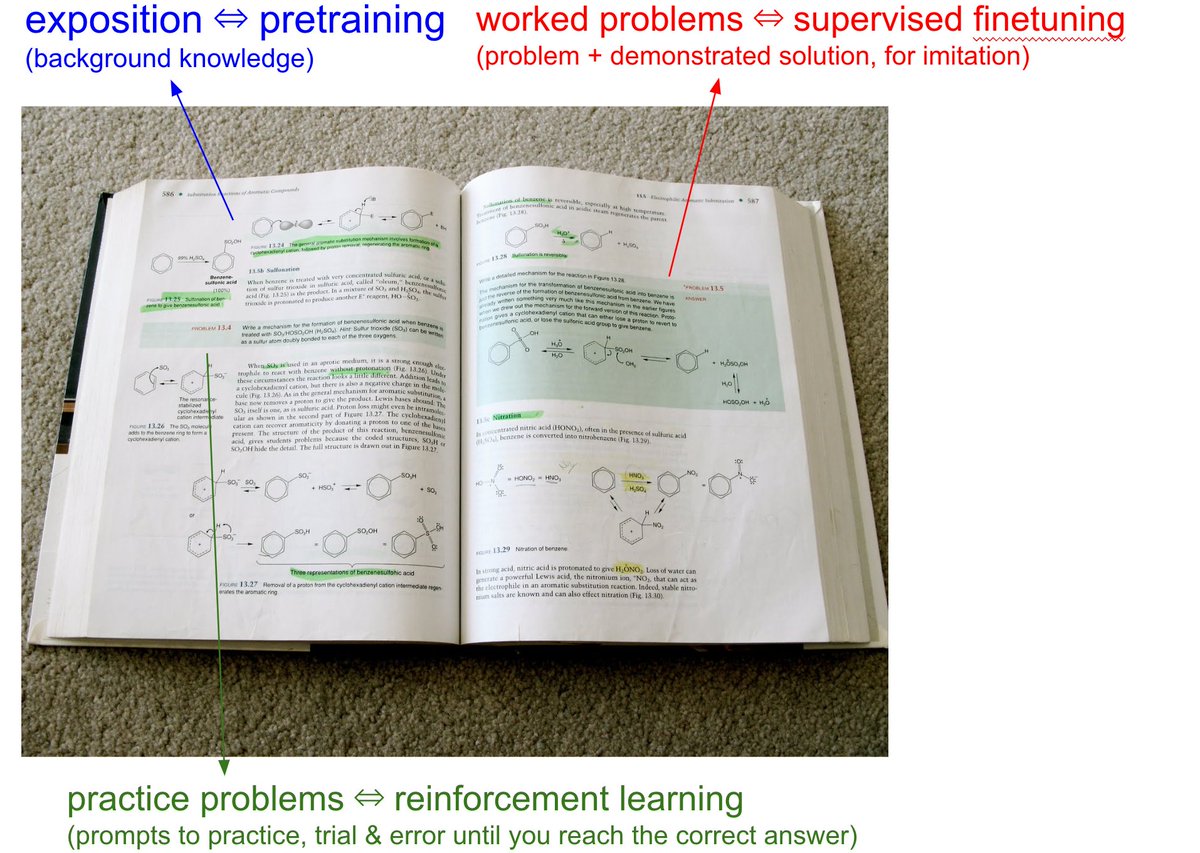
We have to take the LLMs to school.
When you open any textbook, you'll see three major types of information:
1. Background information / exposition. The meat of the textbook that explains concepts. As you attend over it, your brain is training on that data. This is equivalent to pretraining, where the model is reading the internet and accumulating background knowledge.
2. Worked problems with solutions. These are concrete examples of how an expert solves problems. They are demonstrations to be imitated. This is equivalent to supervised finetuning, where the model is finetuning on "ideal responses" for an Assistant, written by humans.
3. Practice problems. These are prompts to the student, usually without the solution, but always with the final answer. There are usually many, many of these at the end of each chapter. They are prompting the student to learn by trial & error - they have to try a bunch of stuff to get to the right answer. This is equivalent to reinforcement learning.
We've subjected LLMs to a ton of 1 and 2, but 3 is a nascent, emerging frontier. When we're creating datasets for LLMs, it's no different from writing textbooks for them, with these 3 types of data. They have to read, and they have to practice.