Microsoft just banned its own engineers from using AI.
The tool was literally costing MORE than the humans it was supposed to replace.
They lied to you about AI adoption and now the whole narrative is blowing up:
Microsoft gave thousands of engineers access to Claude Code six months ago and encouraged them to use it.
Engineers loved it and adoption exploded. But then the invoices arrived.
Token-based pricing means every query, every code review, every debugging session costs money. At scale across 100,000 engineers, the numbers became so large that Microsoft issued an internal order to cancel nearly all Claude Code licenses by end of June and force everyone onto their own cheaper tool instead.
The company that invested $5 billion in Anthropic just told its own people to stop using Anthropic's product because it costs too much.
Uber's story is even worse...
Their CTO Praveen Neppalli Naga told The Information that the budget he planned for the full year was "blown away already" by April.
Uber had rolled out Claude Code in December 2025. By March, 84% of their 5,000 engineers were using it with 70% of all committed code coming from AI systems.
Heavy users were burning $500 to $2,000 per month each. Naga himself spent $1,200 in a single two-hour demo session.
The company had even built internal leaderboards ranking engineers by how much AI they used. They literally gamified the spending and then ran out of money.
Now look at what Nvidia's own VP of applied deep learning Bryan Catanzaro said to Axios last month. Direct quote:
"For my team, the cost of compute is far beyond the costs of the employees."
This is a VP at the company that SELLS the chips saying that using AI is more expensive than paying humans.
Think about what this means for the entire AI narrative.
Every CEO on every earnings call for the past two years has said the same thing:
AI will make us more efficient, reduce headcount, and cut costs.
The stock market rewarded every company that said it.
Fired workers, stock goes up. Announced AI adoption, stock goes up.
But the actual companies deploying AI at scale are discovering the math doesn't work. The MORE employees use AI, the HIGHER the bill.
Goldman Sachs forecasts a 24x increase in token consumption by 2030 as companies adopt AI agents. Gartner just published a report showing that even though individual token prices will drop 90% by 2030, total enterprise AI costs will go UP because agents consume exponentially more tokens per task than basic tools.
Meta built an internal dashboard called "Claudeonomics" to track which employees use the most AI. Amazon started pushing engineers to "tokenmaxx," their internal term for consuming as many AI tokens as possible.
Both companies are spending hundreds of billions on AI infrastructure this year alone.
And Microsoft, the company that bet its entire future on AI, just told 100,000 engineers to stop using the tool they liked best because the per-token bills got out of control.
The companies building AI are telling investors it saves money. The companies using AI are finding out it costs more than the humans it was supposed to replace. And even the company that makes the chips just admitted it through its own VP.
This is the gap nobody on Wall Street is pricing in.
$725 billion in AI infrastructure spending this year across Big Tech. And the first companies to actually deploy these tools at scale are already pulling back because the economics don't work.
What do you think?
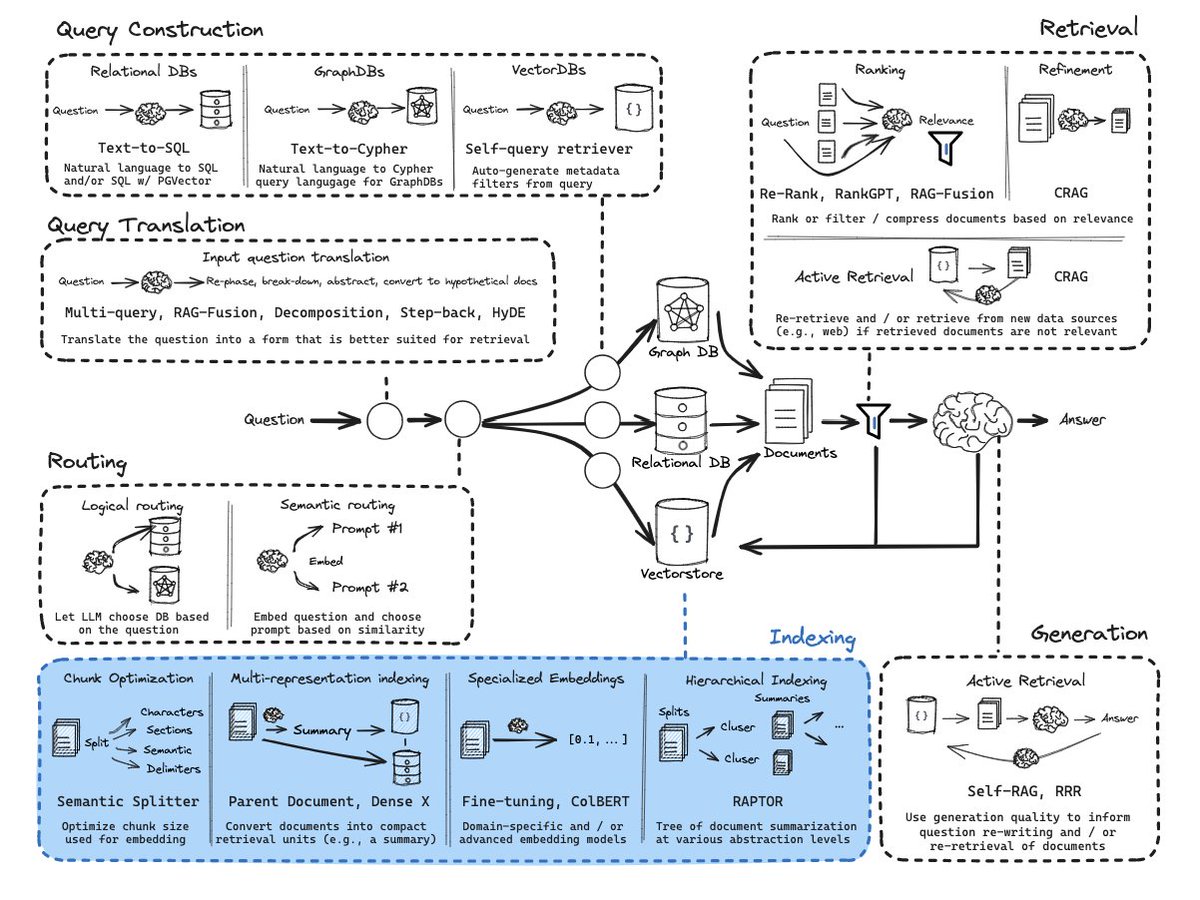
RAG From Scratch: Indexing w/ ColBERT
Our RAG From Scratch video series walks through impt RAG concepts in short / focused videos w/ code.
This is the 14th video in our series and focuses on indexing with ColBERT for fine-grained similarity search.
🔧 Problem: Embedding models compress text into fixed-length (vector) representations that capture the semantic content of the document. This compression is very useful for efficient search / retrieval, but puts a heavy burden on that single vector representation to capture all the semantic nuance / detail of the doc. In some cases, irrelevant (to a query) / redundant content can dilute the semantic usefulness of the embedding for retrieval.
💡 Idea: ColBERT (@lateinteraction & @matei_zaharia) is a neat approach to address this with a higher granularity embedding approach: (1) produce a contextually influenced embedding for each token in the document and query. (2) score similarity between each query token and all document tokens. (3) take the max. (4) do this for all query tokens. (5) take the sum of the max scores (in step 3) for all query tokens to get a query-document similarity score. This granular token-wise similarity scoring between document and query has shown strong performance.
📽️ Video:
https://t.co/1Vp6Wzyscd
💻 Code:
https://t.co/RuO8Gn3Tmc
🧠 References:
1/ Paper:
https://t.co/AGkRq2FtBC
2/ Nice review from @DataStax:
https://t.co/M9EEVzSR0n
3/ Nice post from @simonw:
https://t.co/jjnJGP8P33
4/ColBERT repo:
https://t.co/wNUEn3QKMo
5/ RAGatouille to support RAG w/ ColBERT:
https://t.co/LSOp1weuFG
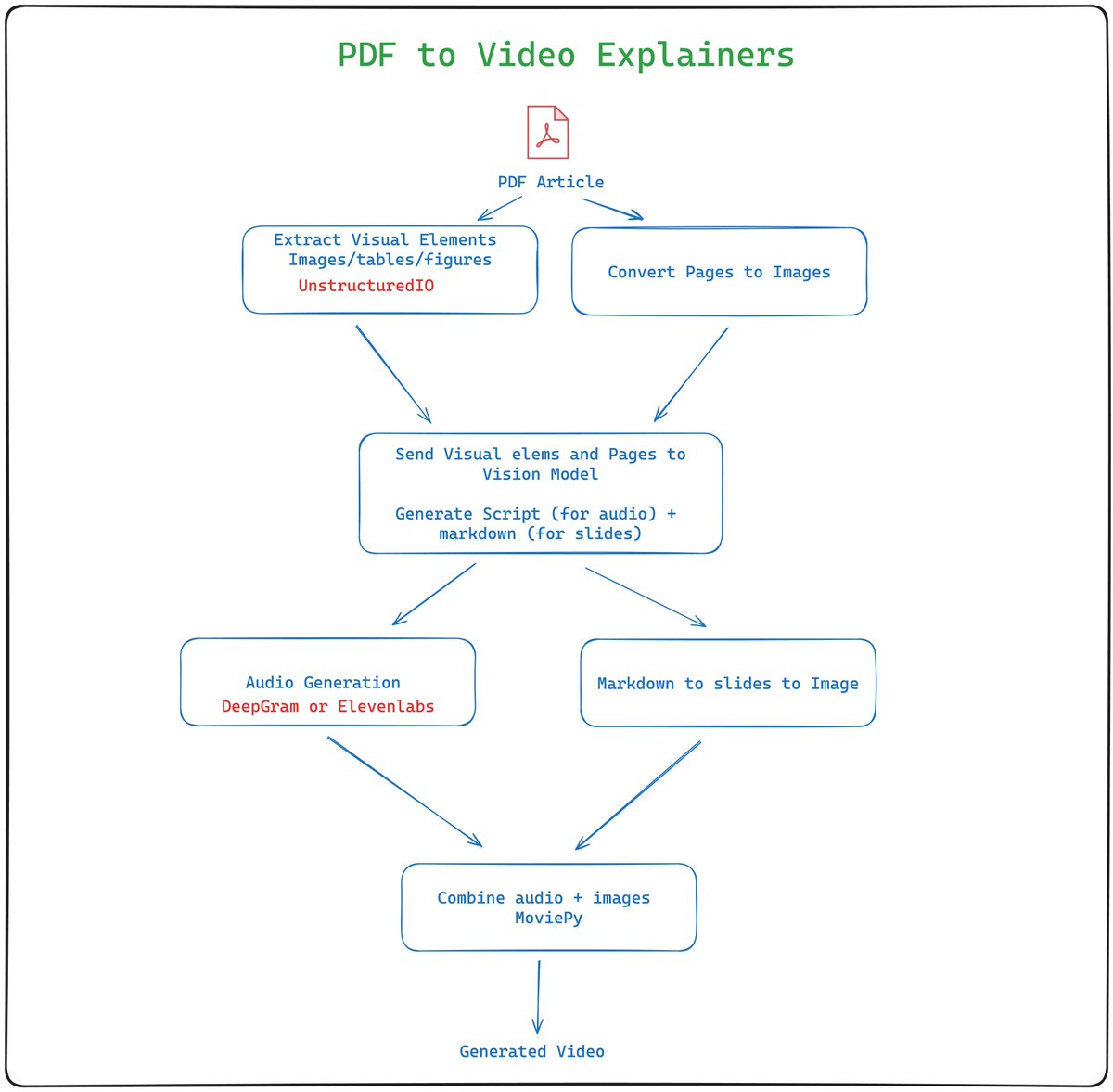
It takes a PDF and first extracts all the visual elements using @UnstructuredIO (they make it super easy). Additionally, each page of the PDF is saved as an image. Visuals and images are then sent to a vision model. Both GPT and Cluade were tested, and both performed well at it. Thanks to @langchain for making this swap/test easy.
A bit of prompting was required to ensure the markdown for slide conversion was accurate. The markdown version of @revealjs by @hakimel was used for this conversion.
The text script was sent to @DeepgramAI for TTS conversion.
Finally, everything was combined using MoviePy.
Prob: There are too many AI papers to read (and a bit difficult to understand)
Sol: A PDF2Video explainer. Drop a PDF and get a well-explained video incl. text, images, equations, figures, etc. Uses @langchain, @UnstructuredIO, @DeepgramAI
1/ Attention is all you need:🔈🔊
Introducing Claude 2! Our latest model has improved performance in coding, math and reasoning. It can produce longer responses, and is available in a new public-facing beta website at https://t.co/uLbS2JNczH in the US and UK.
More industries are turning to #IoT for real-time insights into their data. Discover how the now available #Azure#TimeSeriesInsights Gen2 provides updated solutions for analyzing large volumes of data: https://t.co/kBF8XLYjL4