A research workshop on large language model gathering 1000+ researchers around the world
Follow the training of the 176B multilingual model live @BigScienceLLM
BLOOM is here. The largest open-access multilingual language model ever. Read more about it or get it at
https://t.co/mE013I62In
https://t.co/KrBRVklXLf
Our design for Jean Zay’s new covering translates the gradient descent, the mathematical heart of how AI learns, into color and form.
We actually studied the landscape loss of the BLOOM model from @BigscienceW, which was trained on Jean Zay, to create the artwork.
This is the tech that Tunji Ruwase and I first started working on during @BigscienceW to deal with cluster resizes during BLOOM-176B training and then Sam Ade Jacobs, Lev Kurilenko and Masahiro Tanaka brought it to the finish line, improving the code, and publishing a paper and presentation at USENIX ATC 2025.
See Minja's post below for links to paper, code, etc.
4 years ago we were on the brink of AI becoming proprietary and centralized, when OpenAI kept GPT3 closed and VCs started dumping money on researchers. From fully open science, to fully closed, in a matter of months. It was scary, and 1,000+ leading researchers and scientists banded together to show the world that it was possible to do the same work in the open, and build an ecosystem that benefits everyone. That was the @BigscienceW BLOOM project, and it put us back on track to open science, starting with forward-thinking organizations like @Meta releasing OPT.
Look at us now. Open models have not only caught up, they're state of the art now. Not just LLMs, but models for document AI, speech to text, text to speech, generating images and more. We're closing in on 2 million open weight models on @huggingface.
Thanks for the reminder @Thom_Wolf .
Packing for a weekend I found this.
It is hard to believe that @BigScienceLLM really happened. The first time I heard of the idea my take was "this is going to be fun... but not going to work"
Kudos to @Thom_Wolf for the vision
DPhil candidate @cailean_osborne shares reflections on the @OpenSourceOrg co-design process to define #opensourceAI and recommends next steps, including improving model safety and supporting more grassroots initiatives like @BigscienceW.
The Universal Checkpointing paper is out! https://t.co/rAZ91sOA7K
If you remember the @BigscienceW BLOOM-176B training, Tunji Ruwase and I co-invented this technology for Megatron-Deepspeed in order to enable to quickly scale up and down node topology while continuing training.
Since then @MSFTDeepSpeed continued improving on that and it has now been fully integrated into Deepspeed.
The blog post is here: https://t.co/39V5lSjOVh
I respect the caution, but also need to stress that efforts that pursue transparency as an operational value in service of actual inclusion and accountability do exist - see for example the writing on this very topic by @BigscienceW, including its ethical charter.
1/3
Never thought I'd see the day I'd have a publication in JMLR 🥹
So happy that the BLOOM carbon footprint paper has finally found a home at such an incredible venue!
Thank you @shakir_za for being such a great editor, it warms my heart to see your name on this paper 💚
If you wanted to see the fun panel/Q&A we did with Londoners on AI, you can check out the recording here!
My preso at the start is also on Open Science, representing @huggingface & @BigscienceW.
Introducing: 💫StarCoder
StarCoder is a 15B LLM for code with 8k context and trained only on permissive data in 80+ programming languages. It can be prompted to reach 40% pass@1 on HumanEval and act as a Tech Assistant.
Try it here: https://t.co/4XJ0tn4K1m
Release thread🧵
Join us tomorrow, Wednesday 22nd (6:30 PM - 8:00PM CET) at the @mozillafestival Science Fair to learn more about our work in the open and responsible development of large language models (LLMs) for code.
https://t.co/YTpBBzDe8c
#Mozfest
As you already know, I am very proud of the collective work that enabled the development of @BigscienceW's ethical charter. Today I am even more proud to announce that it's part of @OECDinnovation's catalog to promote Trustworthy AI: such a milestone!
https://t.co/C9A0rhgAO2
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Documents the data creation and curation efforts of ROOTS corpus, a 1.6TB dataset used to train BLOOM
Releases a large initial subset of the corpus
data: https://t.co/8uHADRFuJl
abs: https://t.co/KWwt6TaxQx
Worried about benchmark data contamination? Studying LLM memorization or attribution? @BigscienceW BLOOM 🌸 now has exact & fuzzy search over full training data!
with @olapiktus🏆 @christopher Paulo Villegas @HugoLaurencon @ggdupont @SashaMTL@YJernite
https://t.co/rKE3BmMfKq
/1
(Repost for corrected Arxiv)
🧐What’s the best way to quickly adapt large multilingual language models to new languages?
We present our new paper from @BigscienceW 🌸:
BLOOM+1: Adding Language Support to BLOOM for Zero-Shot Prompting.
📜 https://t.co/MLUSsdXt29
[1/9]
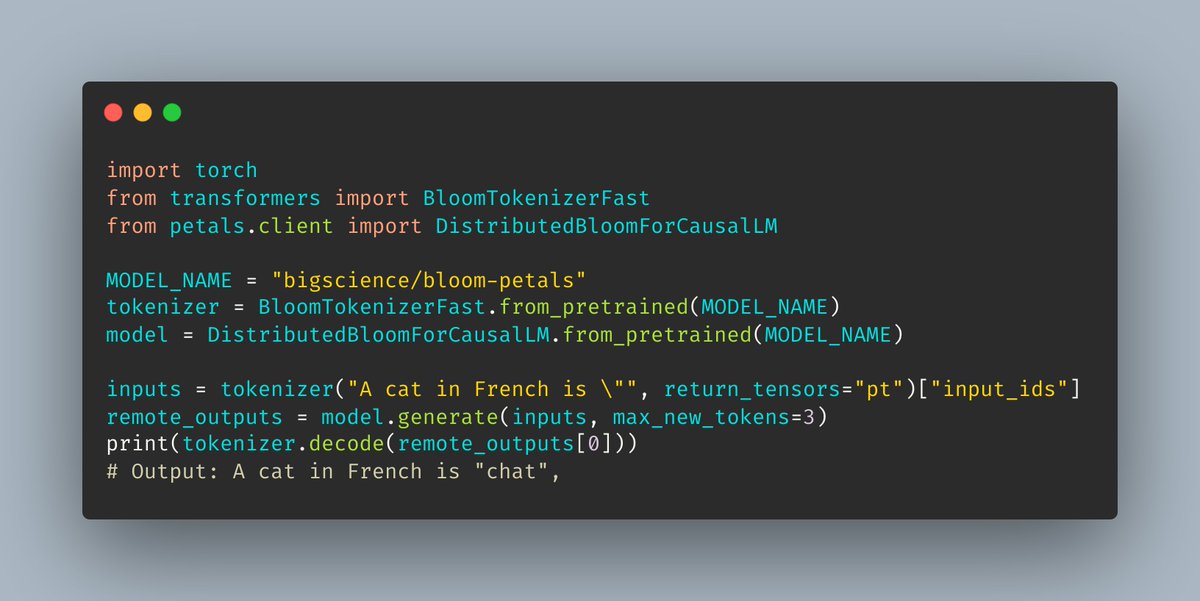
Petals, a system for easy decentralized inference and adaptation of 100B+ LLMs, is now online!
🌸Generate text with BLOOM-176B using Colab or a desktop GPU
🔌Fine-tune large models for your tasks
👥Help others by contributing your GPUs or host a new swarm
https://t.co/5AJ37q7DUX
The Bloom paper is out. Looks like it's doing worse than current GPT3 API in zero-shot generation tasks in English but better than other open-source LLMs & better than all in zs multi-lingual (which was the main goal). Proud of the work from the community! https://t.co/NMHIzi1F79





































![yong_zhengxin's tweet photo. (Repost for corrected Arxiv)
🧐What’s the best way to quickly adapt large multilingual language models to new languages?
We present our new paper from @BigscienceW 🌸:
BLOOM+1: Adding Language Support to BLOOM for Zero-Shot Prompting.
📜 https://t.co/MLUSsdXt29
[1/9] https://t.co/20blxo9ODL](https://pbs.twimg.com/media/Fka03d2WIAA0Iz4.jpg)