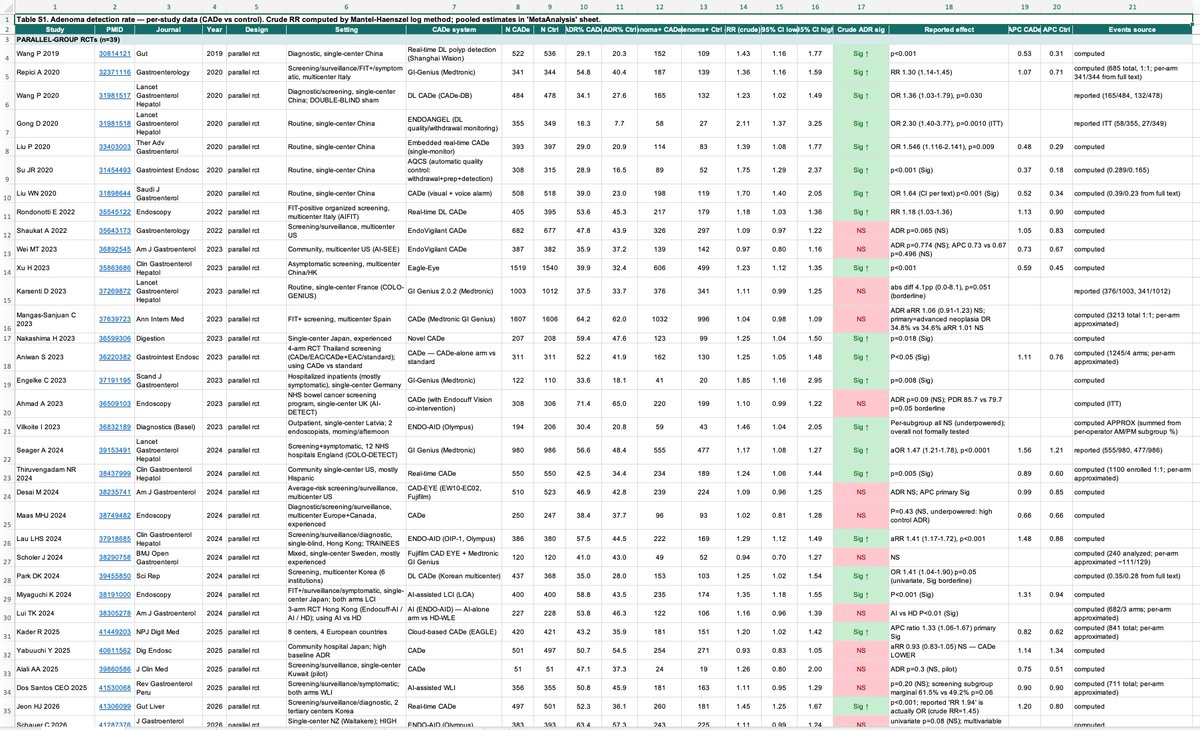
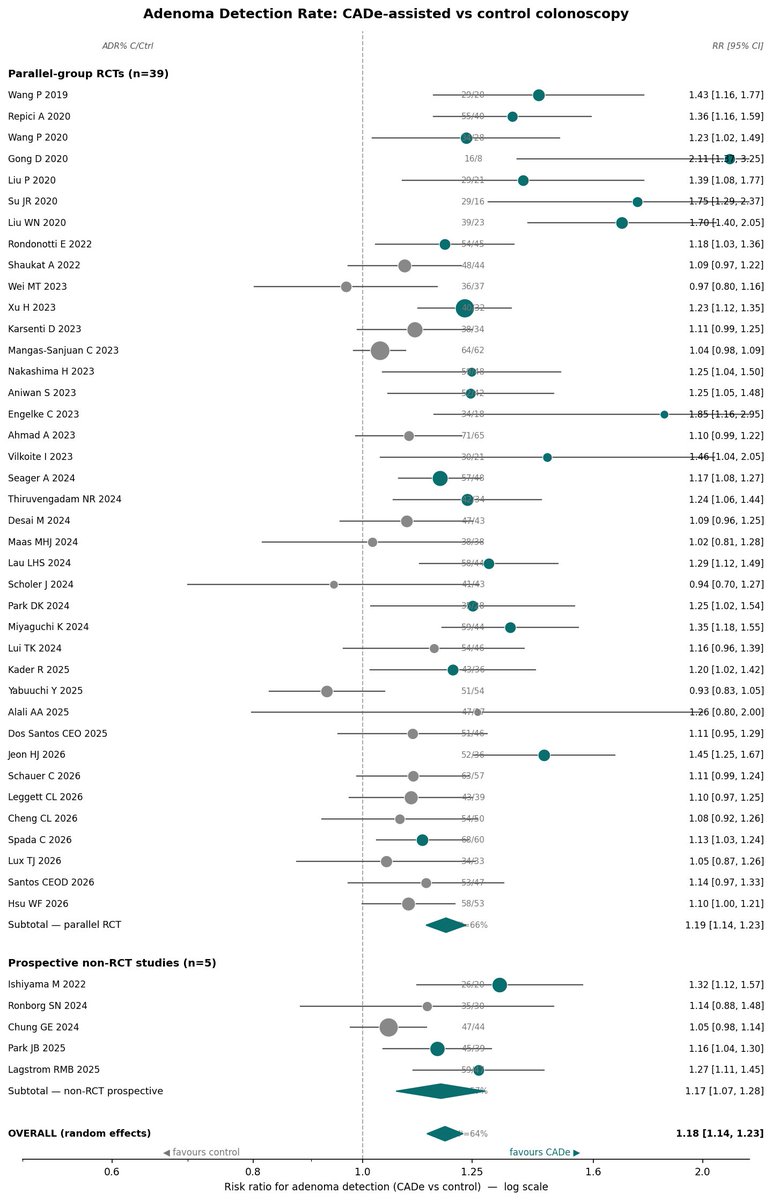
🧬 El fin de la ciencia inventada? Cero alucinaciones en PubMed con Claude
Usa el nuevo protocolo MCP para conectar Claude directamente a la base de datos de PubMed. ¿El resultado? Analiza más de 50 papers médicos en segundos con 0% de alucinaciones.
Lo que soluciona:
Conexión Real: Consulta la API oficial de PubMed en tiempo real (mira las tablas y gráficos adjuntos).
Cero Datos Falsos: Valida identificadores (PMID) y resultados clínicos reales de forma exacta.
Metanálisis Express: Convierte horas de lectura médica en resúmenes estructurados al instante.
El Siguiente Nivel (Idea de Producto):
Review Pipelines: Agentes que redacten revisiones sistemáticas automáticas basadas en este protocolo.
Clinical Alert Bot: Un bot que monitoree PubMed y publique hallazgos críticos en X o Discord de forma autónoma.
Se acabaron las citas bibliográficas falsas.
Repooooo 👇👇
Affinity Fine-Tuning of Boltz-2: An Open Framework for Protein-Ligand Potency Prediction in Drug Discovery
Boltz-2のリガンド親和性予測のファインチューニングフレームワーク
固有の実験データでアフィニティ予測部分のみ最適化
https://t.co/T5htMQi0bP
https://t.co/41SAJMWtJq
Scientific discovery is not a single chain of thought @GaoShanghua@AdaFang_ . It is a long-running process of competing hypotheses, failed experiments, shared insights, and changing research directions
AutoScientists lets AI agents do the same
https://t.co/JHAkbEx2Ac
🧪 We call this AutoScientists: self-organizing agent teams for long-running scientific experimentation
Open science:
Paper: https://t.co/mzEx5xwtSE
Code: https://t.co/1OLxN4AW94
@HarvardDBMI@harvardmed@broadinstitute@KempnerInst
Hello again, everyone!
We've got another really fun 9b, this one specifically trained for tool calling and agentic coding workflows in @NousResearch Hermes agent.
Happy to report that it crushes, and as a 9b it runs on super affordable hardware. We also hit this one with some coding domain-specific training, and it scored a 53.33% on SWE bench on a slice of 200 samples!
To me, I was really shocked to see this high of a score on a 9B model in swe, correct me if I'm wrong, but I think that's nipping at the heels of the Gemma 4 series, much larger models on this particular benchmark, which is really incredible to see!
It also crushes the HermesAgent-20 benchmark, scoring an 85 vs the base model's 71!
Make sure to run it hot, --temp around 1, that seems to be the sweet spot for running these particular fine tunes in harnesses. If you have trouble, you can work your way down, but it does a much better job departing from base models, overthinking when you run it, high temp ~1.
Please spin it up in Hermes and let us know your thoughts! Looking forward to hearing your feedback as always!
Also, those of you waiting for Qwopus 3.6 27B, I have put together a preliminary evaluation for you in my HF repo, go check it out; we will be releasing the full model very soon! I will put the preliminary repo in the comments!
https://t.co/vP2s9iP6wL
What if we could design ligands that not only bind a target, but functionally direct it toward activation or inhibition? In our #ICML2026 Spotlight, we present TD3B, a discrete diffusion framework for directional allosteric binder generation! 🦉
📜: https://t.co/EI8AOWChqY
🤗: https://t.co/kNC0ywflgQ
Confidence Is the Key: How Conformal Prediction Enhances the Generative Design of Permeable Peptides
1. The paper argues that RL-guided generative design can be misled by predictive models when generation drifts outside the model’s applicability domain, producing “high reward, high uncertainty” peptides—especially problematic for understudied cyclic peptides.
2. They integrate conformal prediction (CP) directly into the reinforcement learning (RL) scoring loop (PepINVENT-style peptide completion), so the agent is rewarded not just for predicted permeability, but for permeability predictions made with calibrated confidence at a user-chosen confidence level (here, 80%).
3. Core technical setup: a permeability classifier (XGBoost on ECFP features) is trained on CycPeptMPDB PAMPA data (6876 cyclic peptides; threshold LogPexp ≥ -6 as permeable). On top of this, they build an aggregated Mondrian inductive conformal predictor (ACP with 10 ICPs) outputting two p-values: P1 (permeable) and P0 (non-permeable).
4. Key conceptual point: CP’s two p-values encode “evidence for each class,” enabling four outcomes (Class 0, Class 1, Both, None). In RL, the target is not merely “high P(permeable)” but conformal efficiency: confidently permeable designs where P1 > 0.2 and P0 < 0.2 (at significance 0.2).
5. Baseline finding: optimizing raw model probability (standard practice) increases average predicted permeability (raw score rises ~0.51→0.87 over 350 epochs), but many “permeable” designs are not conformally confident—highlighting a mismatch between probability-based rewards and calibrated reliability.
6. They test multiple CP-based reward designs: maximize P1, maximize (1−P0), maximize (P1−P0), plus two discrete schemes: “harsh” (reward 1 only if both thresholds met) and “soft” (reward 1 if both met, 0.5 if one met, else 0).
7. Main methodological takeaway: single p-value optimization (P1 alone or 1−P0 alone) is learnable but does not reliably increase the number of confidently permeable peptides, because maximizing P1 does not ensure low P0 (and vice versa). The joint decision structure of Mondrian ICP matters.
8. Best-performing strategy: the CP “soft” scoring function converges fastest to the desired region (defined as reaching ~50% conformally efficient permeable predictions among valid molecules) and yields more reliable hits than raw-probability scoring when “hits” are defined as confident + within-domain.
9. Practical insight on generation dynamics: the soft reward reduces brittleness from sparse rewards (compared to harsh) and improves efficiency—fewer unique valid molecules may be generated overall, but a higher fraction meet the calibrated confidence criterion, meaning less wasted exploration in uncertain space.
10. Robustness check: performance depends on peptide length and training-data coverage. The CP-soft approach works well for lengths well represented in training (6, 7, 8, 10), but deteriorates for 9, 11, 12, effectively flagging when the predictor’s applicability domain is being exceeded—useful as a “stop relying on this objective” signal.
📜Paper: https://t.co/9o1GQpcjZs
#ConformalPrediction #ReinforcementLearning #GenerativeModels #PeptideDesign #CyclicPeptides #UncertaintyQuantification #Cheminformatics #ComputationalBiology #DrugDiscovery #MachineLearning