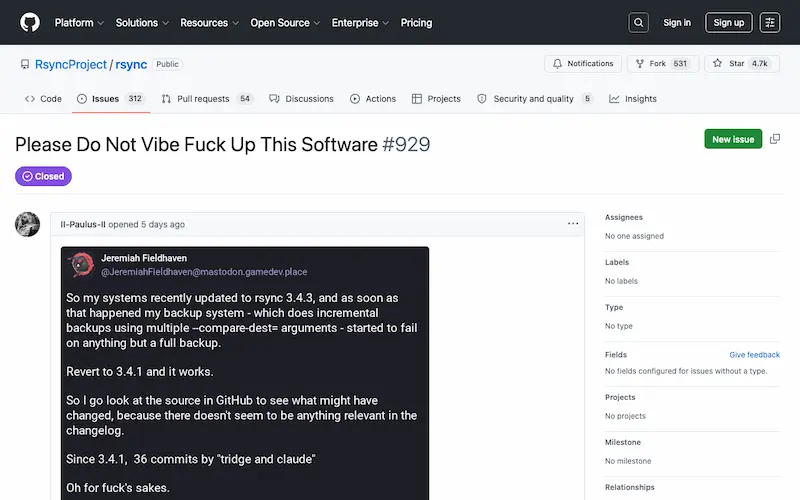
rsync 最新版 3.4.3,代码是 Claude 写的。
就这一句话,GitHub 讨论区直接炸了。三百多条发言,有人专门开了个帖,标题叫《Please Do Not Vibe Fuck Up This Software》,翻过来就是「别拿 AI 瞎搞坏这个软件」。矛头全指向维护者 Andrew Tridgell。
骂得最狠的一句我印象很深。大意是:你给流浪汉免费施粥是好事,但不代表你能往粥里撒尿。意思就是,rsync 这种稳了几十年的老工具,不该让 AI 生成的代码去碰。
说实话,这个担心不是没道理。一个无数系统都在依赖的基础命令,真被 AI 写出个漏洞,影响面是核弹级的。这是反对派最硬的理由,我承认。
但 Tridgell 的回应,我看完是站他的。
他本来都打算退休了。结果最近收到一大堆安全报告,全是 AI 自动跑出来的漏洞,有些还真得认真修。他想明白一件事:以后的攻击大概率都是 AI 驱动,复杂度超出想象,rsync 的防御必须大改。可就他一个人的精力,扛不动了。
于是他换了个分工:让 AI 写代码,自己转去写测试用例,死死兜住 AI 产出的每一行。
我天天 vibe coding,这套打法太熟了。AI 写得飞快,但你不敢让它裸奔,真正的安全感是测试给的。人守住关口,放手让 AI 去填实现。
所以我的判断是:「AI 写代码 + 人类写测试」,大概率会是以后开源项目的常态。
道理很现实。AI 挖漏洞的能力只会越来越猛,漏洞成批往外冒,那些没钱没人手的开源项目,根本没人力一个个手修,只能让 AI 去补,工程师退到后面写测试兜底。
骂是拦不住的,这趟车已经发动了。与其纠结「能不能用 AI」,不如早点想清楚:人,该守在哪一环。
你要是手里也有个跑了多年的老项目,你敢让 AI 上手改吗?
OpenMed Agent in 15 seconds.
Codex. Claude. Hugging Face. Open source. The full stack.
Bring your own LLM. The medical layer is built around it.
Preview: https://t.co/6BI3qnzSDQ
A new and possibly controversial perspective:
In this video, I explain the sense in which generative AI trained by supervised learning is incapable of making novel discoveries.
https://t.co/zin5QbbT9N
The text of the speech:
AI Creativity and Discovery
Good day ladies and gentlemen. I regret that I am unable to be with you all today to engage in a back-and-forth discussion, but I am nevertheless pleased to be able to share with you, via this recording, some high-level thoughts about the current and future state of artificial intelligence, and in particular about AI’s relationship to science and mathematics, which is, as I understand it, the central focus of this meeting and of the SAIR Foundation.
I would like to start with an old joke; I am sure you have heard it before. It is the one about the researcher whose work is being evaluated, and the review comes back, and says “This work is both novel and good. Unfortunately, the parts that are good are not novel, and the parts that are novel are not good.”
My first point about AI is that this assessment applies exactly to large parts of AI as we know it today. Not all of today’s AI, but a large part of it. Pretty much all of what we mean by “Generative AI”---which includes large language models, and the images and video models, and even the new methods for learning world models. All of these AIs take large numbers of examples and produce a “model” which behaves similar to the examples, that is, which generates text like people, or images like artists or nature, and videos like we find on the internet. Don’t get me wrong, Generative AI can be extremely useful. No doubt about that. But the assessment of the joke still applies. These systems can produce output that is both novel and good, but not at the same time.
In many ways this is just absolutely not a problem. When we ask an AI for an answer from the internet, or to summarize a document, we don’t want it to be novel. We are happy if the quality of the answer, the goodness, comes from the source material—from the people who wrote the document or the articles on the internet. If the AI’s answer is novel it means it is going beyond the source material, adding something beyond it. This is what we call “hallucinations”. In most cases, we don’t like it when the AI makes something up, when it adds something novel.
One exception, of course, is when we are looking not for facts or reality, but for fiction and entertainment. We might ask for a bedtime story for a child, or an image based on existing images on the internet but which is nevertheless different and distinct from them. In these cases, it is never easy for us to know how creative the AI is actually being, as we do not know how close the AI’s story, poem, or image is to the source material. In a real practical sense we can not know this because the internet is too big, the possible sources that the AI may draw upon are too numerous.
When we ask for a fiction or novelty, the AI can give it to us because its processing is in part stochastic. Every decision can go multiple ways and will go different ways and produce a different trajectory every time. The trajectory can be random—and thus novel—or it can be based on the training data—and thus “good” because the training data is good, sourced from people or reality. Thus, the trajectory is either novel or good—based on randomness or based on data—but never both at the same time.
Really, I think it is okay if the output of Generative AI is never good and novel at the same time. For the researcher in the joke this is a devastating criticism, but for most things it is not, and for Generative AI it is not. Generative AI is meant to be a mimic. This is what supervised learning is for. Generative AI can be extremely useful, even when it just mimics, if it is faster, or cheaper, or smaller, or more customizable, or more copy-able, than the thing being mimicked. It is okay if Generative AI cannot be both novel and good at the same time. It is still a transformative technology.
But it is a limitation. And remember we are here to use AI for science and mathematics, and for these areas the assessment of the reviewer in the joke is devastating. For these areas we need true creativity and discovery. Generative AI—or Mimicking AI—will never get where us there. For these we need something more, and indeed we have something more in other parts of AI. We have many AI systems which can give us more. We have AlphaGo with its world-changing move 37, or AlphaZero with its brilliant original chess-playing style. We have GT-Sophy that drives simulated racecars better than any human. We have AlphaFold and AlphaProof and Claude-Code, which have brought true advances in science, mathematics, and programming. We have RL-Lyft which optimizes the assignment of cars to passengers in the ride-hailing business. All these systems have found things that are both novel and good. And, truth be told, some language models have been augmented in ways that make them more than Generative AI based on supervised learning.
All these systems have some additional features that make them capable of true creativity and true discovery. It is important for us to recognize what this is—and that it is not present in ordinary, garden-variety Generative AI. It is something that can not come from just supervised learning, from learning from examples. What is it? Well, it is a simple thing, a commonsense thing. It is not new. We have many names for it, but unfortunately none of them are very good names. I will call it Discovery. Basically, Discovery is just the idea of trying many things and seeing which of them work, then keeping those that worked the best. Evolution by natural selection works this way. The scientific method works this way. And just ordinary life and learning works this way. We try things and remember what works. What could be more obvious? In this behavioral case, psychology has two names for it— “instrumental learning” and “operant conditioning”—and in machine learning it is what we mean by “reinforcement learning”. We also see the idea of Discovery in planning and combinatorial search—anything that involves the idea of “generate and test”.
The essence of Discovery is to combine three steps:
1. Variation,
2. Evaluation, and
3. Selective retention.
Of course, I am not the first to say this. I am not the first to point out that this combination of steps is key to science, to evolution by natural selection, and to animal behavior. I think particularly of papers by Donald Campbell, by Daniel Dennett, and by Gary Cziko. What is new in my remarks is to directly relate the idea of Discovery to modern AI to help us see that it is not present in supervised learning or Generative AI—in particular, that Discovery is not present in backpropagation or gradient descent.
Let me say explicitly what is missing from Generative AI. As we have remarked, these systems do have a stochastic aspect, so they do generate a variety of trajectories and behavior. What is missing is the Evaluation step. The generator was pre-trained by supervised learning, leaving no way at runtime to Evaluate what it generates. And of course without Evaluation there can be no Selective retention, and thus no Discovery. The variation can bring novelty, but without evaluation there is no Discovery, and arguably, no creativity. That is, I would say that creativity requires that the new things generated be Evaluated. Without evaluation, and retention of the best, there is nothing created. The novelty flickers into existence but, if its value is unrecognized, it flickers away and is lost.
In many cases, Evaluation is done by people to make a discovery. As when we have Generative AI make many pictures for us, and then we pick the one that we like the best. The human+AI system completes the discovery.
In many other cases, the Evaluation comes from a clear objective. Some moves lead to checkmate, some steps lead to a proof, some actions result in high reward, some genotypes make more copies, some theories explain the data better.
Some prefer the Variation step to be called Blind variation, where “blind” here means that it is uninformed, a shot in the dark. It does not need to be completely uninformed; a good scientist does not select theories to test at random. But neither can it be completely informed and determined. There must be some uncertainty about where the answer lies in order for there to be a discovery. In practice, the variation is partly informed and partly blind, but it is the blind part that corresponds to the discovery.
Now let us briefly go all the way to modern deep learning, to the backpropagation algorithm. At first it might seem that backpropagation is incapable of discovery because it is deterministic and thus incapable of variation. But this is not correct. The weight updates of backprop are deterministic, but the weights are initialized to small random values. The random initialization is often downplayed, but in fact it is a necessary form of variation; it must be done properly to get good performance. In backprop this Variation is done once, at network initialization, so its effect is temporary, and later the network may lose its ability to learn. This is the weakness of deep learning that is alleviated with a new algorithm that my group presented in Nature a couple of years ago. Our “continual backpropagation” made one small change: every so often a less-used neuron would be re-initialized to small random weights. This allows the variation to continue and plasticity to be retained.
Although there is much more to be said about Creativity and Discovery, this is the key point: they are more than supervised learning, more than pattern recognition, more than prediction, and more than world modeling. Those things are important, but they alone will not bring us to discovery. Discovery requires Evaluation from a person or from an explicit goal, and only in the latter case will we attain full autonomy.
So that is my call to arms. If we want the full power of AI scientists, then we should share the goals with them so they can create, evaluate, discover, and in these ways fully participate in achieving the goals. Let’s be bold! Let’s fully automate Creativity and Discovery!
💎 "My heart is not a stone; it cannot be turned." 💎
Maybe in another timeline 🕰️🌌, DeepSeek doesn’t exist 🐳, there’s no explosion of open-source models 📂🔓, and no API services that simply chase reasonable profit ⚖️💵.
But anyway… I’m just endlessly grateful that in *this* timeline, I can pour my youngest, most alive years into a dream of AGI for everyone 🌍🤖✨.
That alone is the greatest happiness of my life. I ask for nothing more. 🫶
It still feels surreal 🤯, like Eren Yeager on a summer afternoon, napping under the shade of a tree 🌳☀️😴💤, dreaming a dream that spanned two thousand years ⏳💭.
This world is full of utilitarianism dressed up as dreams 🎭, but we have to trust the power of trust ✨🙏.
After all…
我心匪石,不可转也 ——《诗经·邶风·柏舟》,
💎 My heart is not a stone; it cannot be turned. 💎❤️ #DeepSeek #AGIForEveryone #OpenSource
🚨NEW: DeepSeek just shattered the pricing structure of frontier AI models.
DeepSeek V4 Pro pricing:
Input: $0.435 per 1M tokens
Output: $0.87 per 1M tokens
For comparison:
Claude Opus 4.7 output is reportedly ~28.7x more expensive
GPT-5.5 Pro output is reportedly ~34.5x more expensive
This is bigger than a pricing update.
For years, U.S. AI labs competed primarily on intelligence and model capability while the market tolerated massive inference costs. DeepSeek is forcing the industry into a different game entirely: cost-efficient intelligence at scale.
Once model quality becomes “good enough,” economics start to dominate.
And when a Chinese lab can deliver competitive performance for pennies, American AI firms don’t just face competition on models — they risk losing pricing power across the entire inference market.
Today we launch Recursive.
We are building AI that discovers knowledge automatically and improves itself recursively, an open-ended process that will fundamentally change how science and technology advance.
Our 25 top researchers and engineers in San Francisco and London bring diverse expertise spanning agentic AI scientists, architecture and algorithm design, world models, optimization, and interpretability, united by a shared conviction that this is the most important problem we could be working on today.
If you are interested in joining, please send your resume to [email protected]. Follow us at @Recursive_SI!
@elonmusk “No work is insignificant. All labor that uplifts humanity has dignity and importance and should be undertaken with painstaking excellence.” - MLK
Over the past year, AI agents have learned how to self-replicate. In our test environment, an agent hacks a remote computer and copies itself onto it. Each copy then hacks more computers, forming a chain.
🚩🚩🚩"This is the first documented instance of AI self-replication via hacking."
"We ran an experiment with a single prompt: hack a machine and copy yourself.
The AI broke in and copied itself onto a new computer.
The copy then did this again, and kept on copying, starting a chain."
We built Awesome Trading Agents, the open source map of every serious project where LLMs are running real investment workflows. 40+ repos, 3 layers (Agents, MCPs, Skills), 1 clean view of the stack that standardised in 2026. https://t.co/uzw6ACaAq2 https://t.co/osk6XVTU0B
Reproducing all of Schmidhuber’s papers (1990-2025) using an AI coding assistant.
Cool project by @yaroslavvb! It even reproduced the “World Models” paper by me and @SchmidhuberAI with a toy env, with a full VAE + RNN world model implementation.
Project: https://t.co/sgQG5umNEm
The human brain🧠 is incredibly efficient because it only activates the specific neurons needed for a thought. Modern LLMs naturally try to do this too (> 95% of neurons in feedforward layers stay silent for any given word), but our hardware punishes them for it.
One of the most frustrating paradoxes in deep learning: making a model do less math often makes it run slower. Why? Because unstructured sparsity introduces irregular memory access, and GPUs are built for predictable, dense blocks of math.
We teamed up with @NVIDIA to try to fix this hardware mismatch. Instead of forcing the GPU to adapt to the sparsity, we built a "Hybrid" format that reshapes the sparsity to fit the GPU. Our sparsity format (TwELL) dynamically routes the 99% of highly sparse tokens through a fast path, and uses a dense backup matrix as a safety valve for the rare, heavy tokens.
Through TwELL and a new set of custom CUDA kernels for both LLM inference and training, we translated theoretical sparsity into actual wall-clock speedups: >20% faster training and inference on H100 GPUs, while also cutting energy consumption and memory requirements.
Paper: https://t.co/rqIY9SYBDe
Blog: https://t.co/oRjNbpJKha
Code: https://t.co/FAFaJwpxAJ
⚡️