Thrilled that we can finally unveil @GraniteBTC after months of hard work!
I couldn't be more proud of the team and what we've built. We're excited to share our mission of unlocking Bitcoin's liquidity for the world!
ANNOUNCING: Granite, a new era for Bitcoin lending.
We're building a Bitcoin lending protocol that Bitcoiners will actually want to use. Non-custodial bridges. Push notifications. No rehypothecation.
Here's how Granite is reinventing Bitcoin liquidity 🧵
noam brown, suggesting that model weights become relatively less important as inference becomes more important
which means: securing weights still matters, but securing inference capacity becomes a strategic advantage
Increased model capability = increased model fungibility
Invest in your personal harness now - skills and scaffolding - so you can more easily swap models later
I think one of the biggest challenges when it comes to going hard into using AI is loneliness
I am learning all these awesome things and becoming super capable
But the set of people that I can really talk to about it is very small
Is anyone else having this experience?
Starting to dive into Hermes agent by @NousResearch . Strange finding - the agent is generally unaware of it's own capabilities. I asked it whether we could create standalone agents with different skills / memories, and it said no. Then I pointed it at the most recent release notes (that outline "profiles") and it said yes and found the command for it...
🤷♂️
Your product must maintain itself.
For the last 9-10 months we've been building in the testing and reliability space with Jina, our AI QA engineer.
And I've become obsessed with this idea of self-maintaining software.
Most of the work after shipping a feature is finding and fixing issues. Having built in this space, I think we now have the tools to make this part of the cycle almost fully autonomous.
The QA Path
Code review agents do a good job at static analysis, but you can go a couple steps further.
- On every PR, the agent reads the diff and analyzes intent and scope.
It generates test scenarios from the changes (edge cases, integration tests, E2E tests, etc).
- Browser agents and coding agents dynamically run through these scenarios to catch bugs. We open-sourced a browser agent that can be helpful here (SOTA).
- If it finds a bug, it traces through the changes and does root cause analysis.
It generates a fix and opens a PR. A human reviews it.
The Production Path
- On every PR, auto-generate logs where necessary and monitors tied to the changes. You now have a map of what commits point to what monitors and why. This sits on top of whatever your team has already built.
- Once the code hits production, production agents watch your alerts across human and AI-generated monitors.
- When an alert fires, the agent triages it, does root cause analysis, generates a fix, and ships a PR if necessary.
These two paths form a closed loop. The QA path catches issues before merge. The production path catches them after deploy.
Specifically, this paper. It's a brand new resource estimate that's wildly lower than prior estimates of what it would take to break ECC-256. Featuring the Google Quantum AI team + Justin Drake + Dan Boneh
https://t.co/dYRld7HbJY
It's going to hurt *so much* when Dogecoin ends up being the most quantum-resistant crypto...
Would this be proof of the "most entertaining universe" theory?
It is deeply Orwellian that the ideology nominatively predicated on the concept of "progress" sees the guy singlehandedly driving the vast majority of it as one of their greatest enemies.
You don't own your stablecoins. Circle and Tether do. And they have a remote kill switch.
Introducing ➡️ https://t.co/7IulaUkdoW
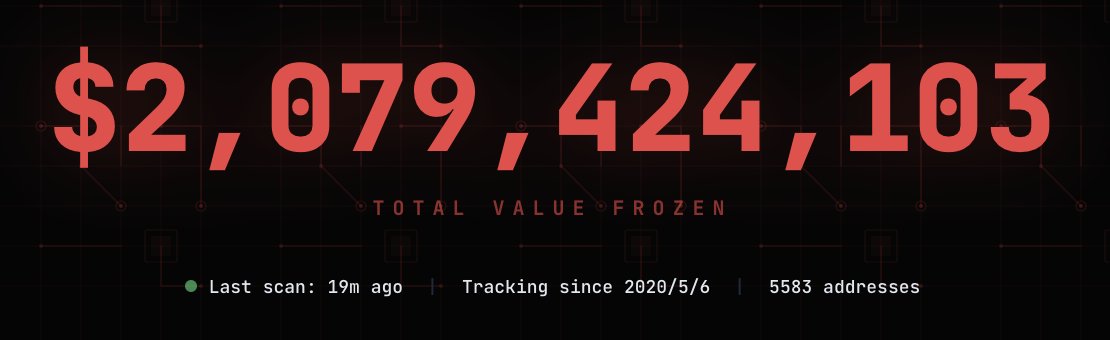
I built a real-time tracker for every single blacklist event on Ethereum and TRON. The data is brutal: thousands of addresses frozen, billions of dollars locked.
No trial. No appeals. No recourse.
What’s under the hood:
- Auto-syncs from Etherscan & TronGrid every 30 mins
- Cumulative charts & monthly freeze breakdowns
- Top censored wallets & a live address checker
Built on the same .rip matrix architecture: open, zero tracking, no signup.
If you hold $USDC or $USDT, you need to see this. Welcome to the transparent fiat prison. 🏴☠️
omg this is so true. It turns out that when you have the capacity to build anything, the greatest limiting resource actually becomes focus, so that you don't dilute yourself by trying to build/learn everything. Every day a new capacity is unlocked.
I'm not claiming I've figured this out (he says as he starts his second new project today, lol)
AI will never, ever save you any time
Because 100% of the time it seems to save upfront has to then be spent researching, learning, and figuring out the next incoming wave of AI tools
And that process will never end. The pace of change will never stop, only accelerate, forever
So it's kind of like borrowing money, and then borrowing more money to pay that loan off, and then even more money to pay that loan off, and so on
You'll never escape the cycle of debt, only sink deeper into it
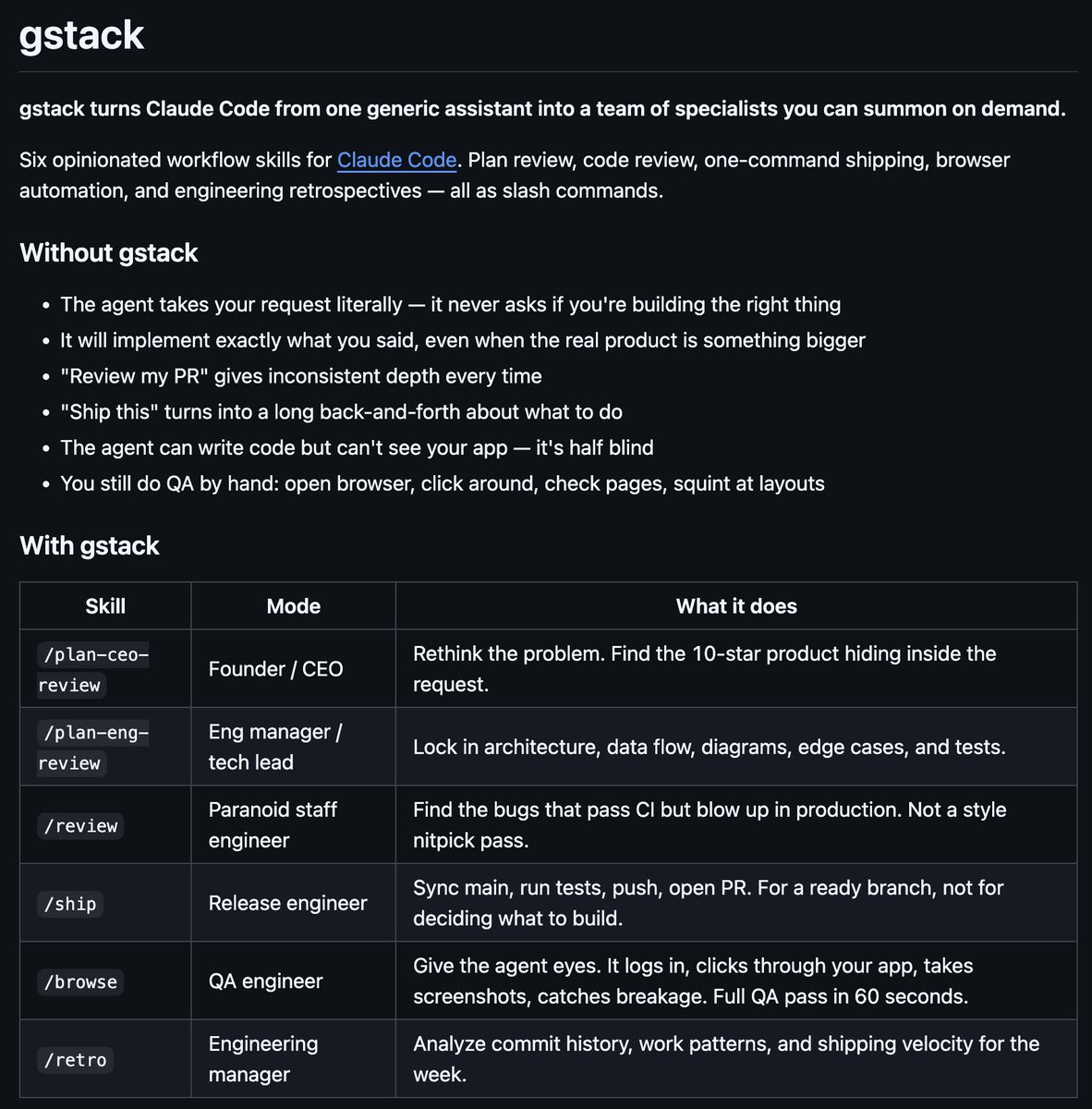
I've been having such an amazing time with Claude Code I wanted you to be able to have my *exact* skill setup:
Introducing gstack, which you can install just by pasting a short piece of text into your Claude code
Inspired by @garrytan 's recent gstack post, I built out browse-multi: a Claude Code skill + scripts for multi-agent concurrent browsing using Playwright.
I use this constantly in deep research / subagent flows that branch in multiple directions.