When I look outside and hear people grumbling, anxious, or pessimistic — while breathing in clean air underneath the warmth of a dependable sun — I can’t help but wonder how many moments are being wasted between tragedies.
Folks seem to rediscover this every couple of years.
As I’ve been saying for many years, you have to track token accuracy, not loss/perplexity, otherwise you’ll wrongly think the validation loss going up is a bad thing.
I feel like we are going to see more APIs that accept embeddings as inputs and return response streams from various token prediction models, of all kinds.
Models communicate with ensemble models via embeddings, makes sense to ensemble over API and save on processing steps.
A nice example of where language AI agents can outperform frontier LLMs and even human experts.
This paper introduces Aviary, an extensible open-source gymnasium for language agents.
They show that language agents backed by open-source, non-frontier LLMs can match and exceed both frontier LLM agents and human experts on multiple scientific tasks at up to 100x lower inference cost.
If AI agents are the next big wave of innovation, software developers should consider focusing on writing backend services to be exclusively consumed by AI agents instead of humans.
I suspect AI agent tools will turn into API calls to different vendors, opening up a new market for startups.
🚨 NVIDIA Introduces Jetson Nano Super
> compact AI computer capable of 70-T operations per second
> designed for robotics, it supports advanced models, including LLMs, and costs $249
Something you learn about the world as you train machine learning models is that failure isn’t binary. It’s a gradient.
We shouldn’t avoid failure, that would guarantee our model doesn’t learn.
Instead, fail better with each attempt. This analogy works best if your objective remains fixed (aka, trying multiple attempts to accomplish the one specific task).
Something that nearly everyone is sleeping on is the importance of prompt caching.
We've just added support for it to Claudette, so @AnthropicAI caching is now *very* easy to use -- cached tokens are 90% cheaper, and faster!
Docs here: https://t.co/93AyBsDdEr
[Open Source] Unitree First View Teleoperation for Humanoid Robots
In order to advance the convenience of data collection for humanoid robots, we refer to other solutions to do the adaptation development and open source.
Github:https://t.co/KvSc8pV0O9
#Unitree#Humanoid#AGI #AI #EmbodiedIntelligence #Manipulation #Teleoperation #DataCollection
The single most undervalued fact of linear algebra:
Matrices are graphs, and graphs are matrices.
Encoding matrices as graphs is a cheat code, making complex behavior simple to study.
Let me show you how!
Woohoo gpu.cpp has now been officially released!
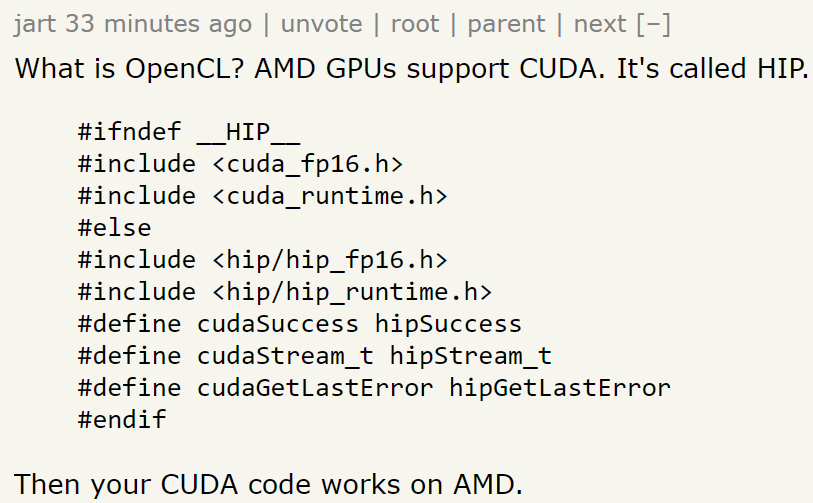
This is a really exciting project which provides a device-independent way to use GPU compute. No more writing separate code for CUDA, AMD, Mac, and Intel GPUs!
We can't wait to see what you all are able to create with this.
In 2019, OpenAI announced GPT-2 with this post:
https://t.co/jjP8IXmu8D
Today (~5 years later) you can train your own for ~$672, running on one 8XH100 GPU node for 24 hours. Our latest llm.c post gives the walkthrough in some detail:
https://t.co/XjLWE2P0Hp
Incredibly, the costs have come down dramatically over the last 5 years due to improvements in compute hardware (H100 GPUs), software (CUDA, cuBLAS, cuDNN, FlashAttention) and data quality (e.g. the FineWeb-Edu dataset). For this exercise, the algorithm was kept fixed and follows the GPT-2/3 papers.
Because llm.c is a direct implementation of GPT training in C/CUDA, the requirements are minimal - there is no need for conda environments, Python interpreters, pip installs, etc. You spin up a cloud GPU node (e.g. on Lambda), optionally install NVIDIA cuDNN, NCCL/MPI, download the .bin data shards, compile and run, and you're stepping in minutes. You then wait 24 hours and enjoy samples about English-speaking Unicorns in the Andes.
For me, this is a very nice checkpoint to get to because the entire llm.c project started with me thinking about reproducing GPT-2 for an educational video, getting stuck with some PyTorch things, then rage quitting to just write the whole thing from scratch in C/CUDA. That set me on a longer journey than I anticipated, but it was quite fun, I learned more CUDA, I made friends along the way, and llm.c is really nice now. It's ~5,000 lines of code, it compiles and steps very fast so there is very little waiting around, it has constant memory footprint, it trains in mixed precision, distributed across multi-node with NNCL, it is bitwise deterministic, and hovers around ~50% MFU. So it's quite cute.
llm.c couldn't have gotten here without a great group of devs who assembled from the internet, and helped get things to this point, especially ademeure, ngc92, @gordic_aleksa, and rosslwheeler. And thank you to @LambdaAPI for the GPU cycles support.
There's still a lot of work left to do. I'm still not 100% happy with the current runs - the evals should be better, the training should be more stable especially at larger model sizes for longer runs. There's a lot of interesting new directions too: fp8 (imminent!), inference, finetuning, multimodal (VQVAE etc.), more modern architectures (Llama/Gemma). The goal of llm.c remains to have a simple, minimal, clean training stack for a full-featured LLM agent, in direct C/CUDA, and companion educational materials to bring many people up to speed in this awesome field.
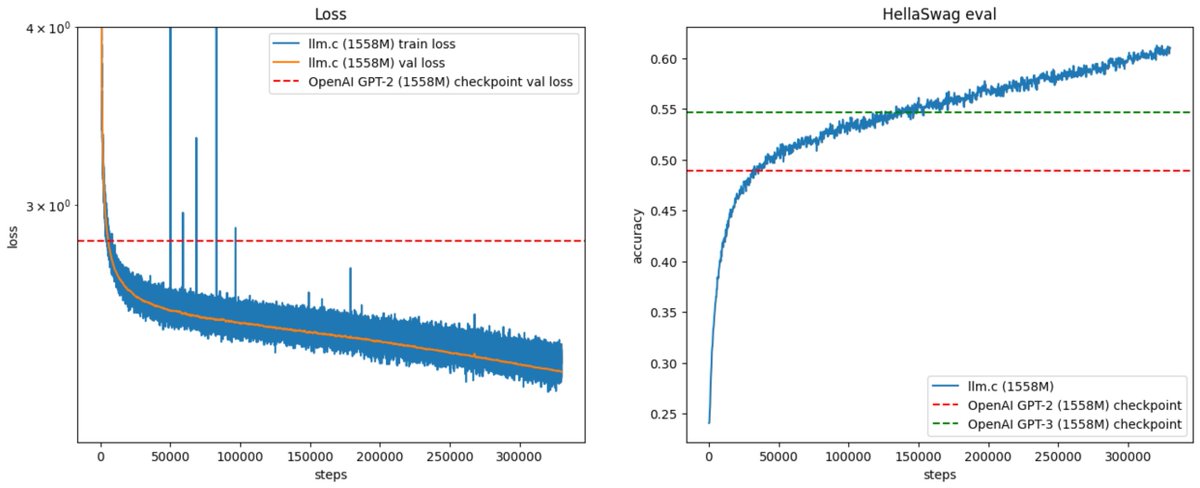
Eye candy: my much longer 400B token GPT-2 run (up from 33B tokens), which went great until 330B (reaching 61% HellaSwag, way above GPT-2 and GPT-3 of this size) and then exploded shortly after this plot, which I am looking into now :)
GPU-Poor no more: super excited to officially release ZeroGPU in beta today. Congrats @victormustar & team for the release!
In the past few months, the open-source AI community has been thriving. Not only Meta but also Apple, NVIDIA, Bytedance, Snowflake, Databricks, Microsoft, Google, and more have released open models and datasets on Hugging Face, which now hosts over 1M models on the Hub which have been downloaded over a billion times. More than that, many are starting to be better than proprietary APIs.
This movement has been supported not only by big tech but also by a thriving open-source AI community that includes academic labs, startups, and independent hobbyists. For example, more than 35,000 variation models of Llama have been shared on Hugging Face since Meta’s first version a year ago—including more than 7,000 based on Llama-3—ranging from quantized and merged models to specialized models in biology and Mandarin, to name a few. More than 4 million AI builders are now using Hugging Face.
However, the open-source community doesn’t have the same resources available to train and demo these models that big tech have at their disposal, which is why ChatGPT remains the most used AI application today.
@huggingface is fighting this by launching ZeroGPU, a shared infrastructure for indie and academic AI builders to run AI demos on Spaces, giving them the freedom to pursue their work without the financial burden of compute costs. Spaces have been the most popular way to build AI demos, with over 300,000 AI demos created so far on CPU or paid GPU (and a thousand more every day). To foster the continued development of the AI ecosystem, Hugging Face is committing $10M of free GPUs with the launch today of ZeroGPU.
Technically speaking, ZeroGPU leverages Hugging Face's experience in hosting and serving more than 100 Petabytes monthly from the Hugging Face Hub. ZeroGPU allows Spaces to run on multiple GPUs by making Spaces efficiently hold and release GPUs as needed (as opposed to a classical GPU Space that holds exactly one GPU at any time). This architecture is also more energy-efficient since GPUs are shared rather than duplicated. ZeroGPU uses @nvidia A100 GPU devices under the hood.
You can learn more about ZeroGPU here: https://t.co/1mxUxXmElv
More than 1,300 ZeroGPU spaces have been built since we started giving early access to AI builders on May 1, 2024: https://t.co/XvJ2MkcK7R
You can explore some examples from @victormustar: https://t.co/b8SUcRelJf
You can find the article from @kyliebytes: https://t.co/87uN1vnMu8
🤗🤗🤗
We are thrilled to be a launch partner for Meta Llama 3.
Experience Llama 3 now at up to 350 tokens per second for Llama 3 8B and up to 150 tokens per second for Llama 3 70B, running in full FP16 precision on the Together API! 🤯
https://t.co/uSCFhbnp8E
I used to find writing CUDA code rather terrifying. But then I discovered a couple of tricks that actually make it quite accessible.
In this video I introduce CUDA in a way that will be accessible to Python folks, & I even show how to do it all in Colab!
https://t.co/WGXXctbalv
Most of an LLM’s memory & compute are consumed by matrix multiplication operations. Today on the blog, learn about techniques used to accelerate mixed-input matrix multiplication for increased efficiency w/ performance close to peak hardware capabilities ↓https://t.co/l4rP606zKY
Introducing ASPIRE, a framework that enhances the selective prediction capabilities of large language models, enabling them to output an answer paired with a confidence score. Learn how it outperforms state-of-the-art methods on a variety of QA datasets. → https://t.co/NQeIV1fXJ6
Yes! Great thread. Brand goes so much deeper than logos, colors, assets. Completely agree! I'm loving the more expansive view people are embracing related to brand and the fact there's a much broader strategy to it upstream. When done correctly, products are brand expressions just like logos are.