What does it really mean for two videos to be similar?
At #NeurIPS2025, we’ll present ConViS-Bench: Estimating Video Similarity Through Semantic Concepts.
Stop by our poster for a chat!
📍Exhibit Hall C,D,E — Poster N.4618
🕒 Thu, Dec 4, 2025 • 11:00 AM – 2:00 PM PST
🙏 CVPR is a wrap for the MHUG lab! A huge thank you to everyone who stopped by our posters, asked questions, and shared ideas. It’s been an incredible few days. See you next year! 👋 #CVPR2026
More pics from our posters 👇
Come see our poster tomorrow afternoon at #ICRA2026 to talk about 3D representation alignment of diffusion models for LiDAR generation.
📍196, Hall C
🗓️ Wednesday, 3:00-4:30 PM
Our recent research will be presented at #CVPR2026@CVPR!
We’ll present nine papers in the main conference & one in the Findings track.
We’ll be speaking in two workshops & one tutorial
Here is a quick overview on the works we’ll be presenting in Denver:
https://t.co/nFZ8wvkuRr
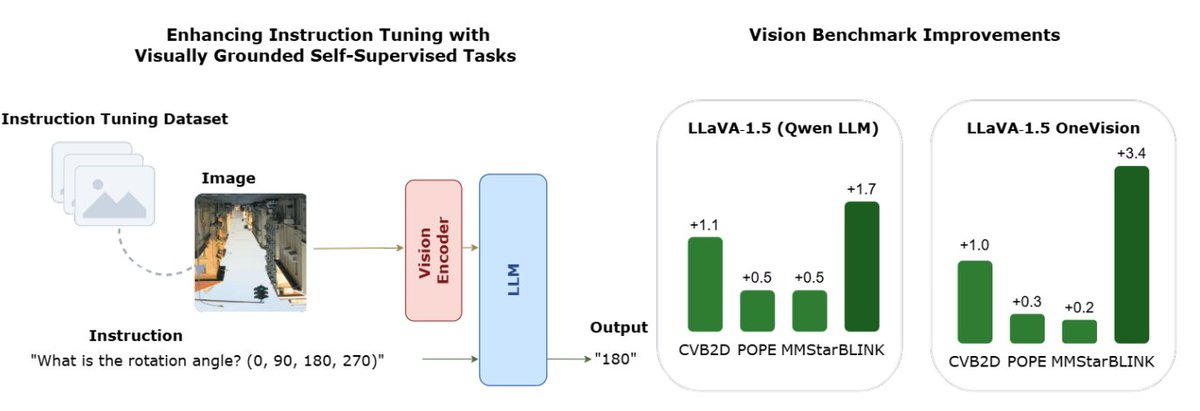
1/n New paper - V-GIFT 🎁
Self-supervised tasks like rotation prediction or colorization were big in 2018.
Do they still matter?
Yes.
We turn them into visual instruction tuning data for MLLMs.
Result: models rely more on the image and perform better on vision tasks 👀
Huge congrats to our colleague and friend @lucazanella95 on his graduation! 🎓
Brilliant researcher, great teammate, and a wonderful person, we’re proud to celebrate this milestone with you, Luca! Looking forward to what comes next 💪
🚨 Are we underestimating Large Multimodal Models for classification?
We challenged the status quo in our new paper from @mhug_unitn, "Large Multimodal Models as General In-Context Classifiers", accepted at #CVPR2026 Findings 🔥
A quick thread on our discoveries 🧵👇1/7
Can MLLMs ask for help? 🤔
When facing an unanswerable visual query, models typically hallucinate or abstain. We argue there's a better option: being proactive and requesting a simple user intervention.
Introducing ProactiveBench! 🧵
Just in case you miss us! DEMO is now in #3DV2026 poster session 3, N.20!
We propose a new task: Dense Motion Captioning, together with the dataset: CompMo (60k, ~40s duration) and the model: DEMO for the task
🕺🏽project page: https://t.co/ikL1gShbiY
come and say hi (virtually!)
working on human motion and in #3DV206 ?
then don’t miss this interesting work!
in “Dense Motion Captioning”, the authors propose a new task, dataset, and the model for dense 3D human motion captioning
🎉 Big news! 🎉
We’re excited to announce that the 9th edition of the Multimodal Learning and Application Workshop (MULA) will be held at CVPR 2026 in Denver as a full-day workshop!
#CVPR2026
What does it really mean for two videos to be similar?
At #NeurIPS2025, we’ll present ConViS-Bench: Estimating Video Similarity Through Semantic Concepts.
Stop by our poster for a chat!
📍Exhibit Hall C,D,E — Poster N.4618
🕒 Thu, Dec 4, 2025 • 11:00 AM – 2:00 PM PST