I've been coding for 40 years. Here are the top 5 things I wish I knew when I started.
1. 90% of the job is debugging and fixing, not creating new code. Which is still fun if you're good at it.
I used to think programming was mostly writing fresh, clever stuff. In reality, most of your time is spent in other people's (or your own past self's) messy code, chasing down why something that "should" work doesn't. Get really good at debugging early. Learn assembly reading, call stacks, and kernel debuggers. It pays off hugely. The best engineers I saw were absolute magicians at this.
2. Manage complexity from day one (ie: don't write slop and "fix it later" if it goes somewhere).
Very early on, I'd hammer out code and refactor afterward. Big mistake. Now I start with clean, skeletal structure (minimalism first) and flesh it out carefully, with AI or not.
Messy code compounds and becomes unfixable. Upfront discipline on architecture, naming, and simplicity saves enormous pain later, especially in large systems like Windows.
3. Tools and processes matter more than you think
We suffered with basic diff/manual deltas instead of modern source control like Git. Branching, testing, and good tooling would have made porting and collaboration way smoother. Invest in your environment, automation, and reproducible builds early. Good tools amplify your output; bad ones (or none) drag everything down.
4. Understand the problem and existing code deeply before writing
Don't jump straight to coding. Map out the problem, study what's already there (you'll inherit a lot), and plan. Low-level knowledge (hardware quirks, alignment issues on different architectures like MIPS/Alpha) was crucial. Also: assert early and often. It forces clarity.
5. People, politics, and "the right tool for the job" beat pure tech arguments.
Brilliant engineers still argue endlessly. Sometimes it's about ego, not merit. Learn to spot the difference and "steer" the conversation rather than "winning" it.
Bonus from experience: Side projects like Task Manager (started at home because I wanted the tool) can become your biggest hits. Ship small, useful things often. If you're just starting, focus on fundamentals, patterns over syntax, and building resilience for the long haul. It's going to be a wild ride, but the fundamentals still matter.
Five bowlers in 18 years. That’s how many pass the scrutiny of a statistical test for elite death bowling.
Elite bowlers don't bowl more yorkers. They just miss fewer. The yorker: economy 5.4. The full toss: 12.4. Six inches, a world apart.
Read more:
https://t.co/9TsanPShvV
📝 Blogged: "On Idempotency Keys"
Discussing several options for ensuring exactly-once processing in distributed systems using idempotency keys, from UUIDs to monotonically increasing sequences.
👉 https://t.co/1S3PUTuKqP
It is impossible to call yourself an experienced infrastructure/distributed systems engineer if you have consistently switched jobs every two years.
You become a rockstar engineer by building complex infrastructure, operating them at scale, migrating users, fixing issues and rolling out v2/v3 of the system. You learn a lot going through this cycle and learn important life lessons.
It typically requires persistence and continuous grind for years to build reliable and scalable systems. My advice is to commit and persist for four years or more at a place to become a solid distributed systems engineer.
Sounds old school but this is how it works. Ai is not going to speed this cycle anytime soon for building deep distributed systems.
If you want to know more about how Google Flights works, airline tickets, and why it is super complicated to deal with all the constraints and the combinatorial combinations, I highly recommend this set of slides by Carl de Marcken, one of the co-founders of ITA software, which Google acquired and became one of the underpinnings of Google Flights.
(Sorry for the http rather than https Link: Carl's domain doesn't appear to support https)
https://t.co/iQgSXyP6D0
In May 2023, a live streaming world record was set with 32 million concurrent viewers watching the finale of the IPL cricket game. How was this system built?
@theprogrammerin was the architect behind this system, and he walks us through how live streaming at scale works, how the system was built and tested, and other interesting learnings.
Watch or listen:
• YouTube: https://t.co/DfOjSyxJjt
• Spotify: https://t.co/jpgfwF8X02
• Apple: https://t.co/gl1MZyQMve
---
Brought to you by our wonderful sponsors:
• @WorkOS — The modern identity platform for B2B SaaS https://t.co/aiAee0pcUP
• @coderabbitai — Cut code review time and bugs in half https://t.co/ks7A2R8GAE (use the code PRAGMATIC to get one month free)
• @augmentcode — AI coding assistant that pro engineering teams love https://t.co/KVGTfMbJF2
---
Three of my biggest takeaways:
1. The architecture behind live streaming systems is surprisingly logical.
In the episode, Ashutosh explains how the live streaming system works, starting from the physical cameras on-site, through the production control room (PCR), streams being sliced-and-diced, and the HLS protocol (HTTP Live Streaming) used.
2. There are a LOT of tradeoffs you can play with when live streaming!
The tradeoffs between server load, latency, server resources vs client caching are hard decisions to make. Want to reduce the server load? Serve longer chunks to clients, resulting in fewer requests per minute, per client… at the expense of clients potentially lagging more behind. This is just one of many possible decisions to make.
3. “Game day” is such a neat load testing concept.
The team at Jio would simulate “game day” load months before the event. They did tell teams when the load test will start: but did not share anything else! Preparing for a “Game day” test is a lot of work, but it can pay off to find parts of the system that shutter under extreme load.
See more takeaways and a summary here: https://t.co/fJOYQSOCbn
Thanks Ashutosh for all these behind-the-scene details!
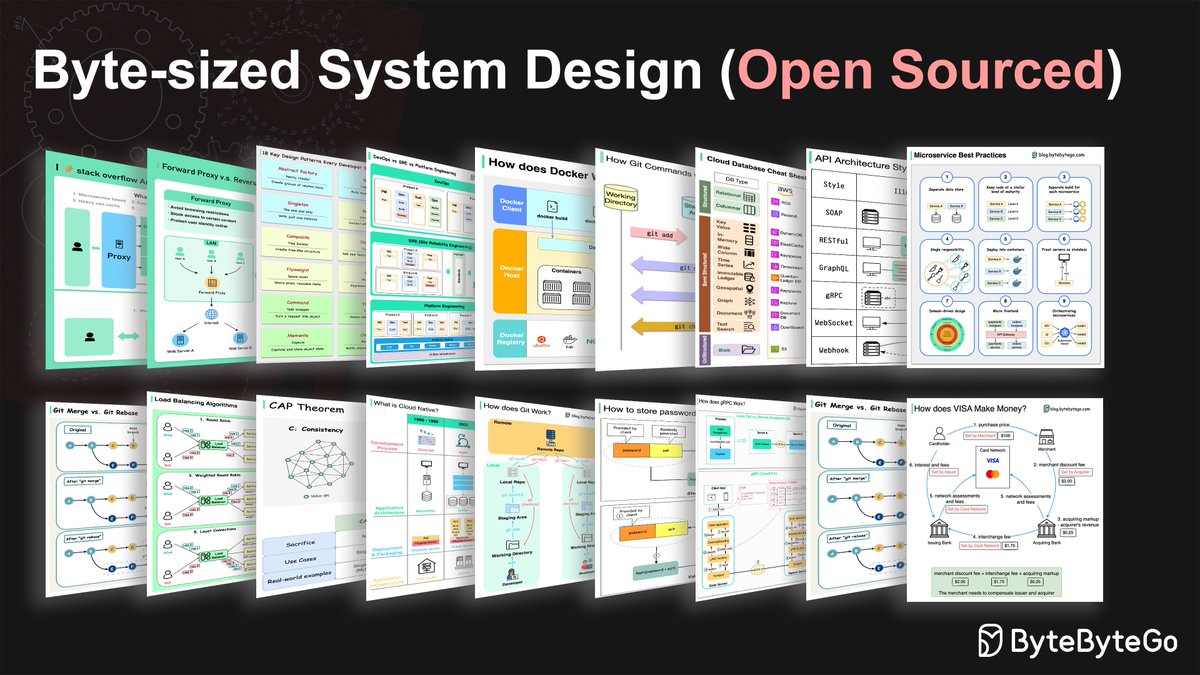
Open-sourcing over 100 byte-sized system design concepts with high-resolution diagrams.
Goals:
- Become a better engineer by understanding how systems work.
- Prepare for system design interviews.
What's included in the GitHub repository:
- 100 byte-sized system concepts with visuals.
- Real-world case studies.
- Tips on how to prepare for system design interviews.
Topics included (and many many more):
- SOAP vs. REST vs. GraphQL vs. RPC
- HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC)
- CI/CD Pipeline Explained in Simple Terms
- 8 Data Structures That Power Your Databases
- Top caching strategies
- What does a typical microservice architecture look like?
Start exploring the repository here: https://t.co/keZF9CNuye
If you find it useful, please RETWEET to spread the word. Thank you.
it IS a document store, but...
1. actually for a lot of problems, a document store is sufficient. while RDBs are great for heavily relational data, actually most of the web is fine with making what is effectively a single field lookup. Particularly with web MVC/MVVM Frameworks that prefer to fetch small batches of data at a time and progressively
2. it's a document store with nested document indexing, sparse indexes, and indexing array members. for data that has a strictly hierarchical structure, and therefore can be stored as nested documents, mongodb lets you index nested keys, resulting in being able to fetch deeply nested documents using a single b-tree index lookup faster than the same operation using multiple joins in an RDB. So for data that can be structured this way, it's fine, and just with (1) a lot of data can be modelled this way
for example let's say you store blog articles in mongodb. comments on blog articles belong to the article, and so you can store them as an array inside a single document that represents the article. something that I think gives RDB people some sort of anxiety. Now, let's say you want to query every blog post a given user has commented on. This is actually a single index operation since you can index the author property inside the comments array of the blog collection
I'm not saying that's going to tip the scales in favour of mongodb every time, but I think certain ways that you can slice a problem, it's pretty convenient, and not without its own merits
New blog post: Things DBs don't do - But should! https://t.co/ClDhNogMtz
It is based on my keynote at #ddtx23 - lots of people asked about it and there were no recordings. So I put my thoughts on writing.