Woke up to this.
177 tasks in production. Three active projects. All built on Fable.
One government directive at 5:21pm Friday. Gone.
No appeal. No transition. No explanation beyond "national security."
This is not a safety story. It's a sovereignty story.
Local models just became mandatory, not optional.
Pope Leo XIV published Magnifica Humanitas on May 15 — an encyclical on AI and human dignity addressed to the entire human family. Not a policy paper. Not a corporate framework. 200+ paragraphs across five chapters.
I read it cover to cover. And I keep coming back to one question it asks:
"Does AI make human life on earth more human in every aspect? Does it make it more worthy of man?"
I don't think we answer that question enough in our field.
What it actually says:
This isn't a rejection of technology. It's a demand for honest accounting.
→ Data is a common good. Algorithms, platforms, and digital infrastructure are explicitly classified alongside traditional goods — private ownership is not absolute. A 135-year-old principle extended into the digital age.
→ Lethal autonomous weapons can't be delegated to machines. "It is not permissible to entrust lethal or irreversible decisions to artificial systems." The question of who bears responsibility when a machine kills remains largely unanswered.
→ The "just war" framework is challenged as outdated. Dialogue, diplomacy and forgiveness are named as humanity's better tools now.
→ The attention economy is named as a form of dependency — not a side effect, but a deliberate feature.
→ Data colonialism is condemned. Health and demographic data extracted from vulnerable populations as a new form of domination.
→ Invisible AI labor is given moral standing. Data labelers, content moderators, rare-earth miners — the human chain that makes "seamless" AI possible.
Which of these surprised you most?
Why this matters beyond religion:
→ This is the first time an institution with 1.4 billion members has issued a detailed governance framework for AI — covering labor, weapons, data ownership, child safety, environmental cost, and epistemic manipulation in a single document.
→ It doesn't just call for ethical AI. It tries to name the structures that produce unethical AI.
I find that distinction more honest than most of what I read in tech. But I'm curious whether you do too.
I've been documenting AI's real-world impact in my From Lab to Life series. If there's one thing practitioners keep discovering, it's this: intelligence is no longer the bottleneck. Power, access, and accountability are.
This encyclical says the same thing from a very different direction.
Full text link in the comments — five chapters, worth the time.
#AI #FromLabToLife #DigitalEthics #Leadership #Technology
My New Article is Live "Context is the Code: The Complete Three-Phase Process for Building with AI Agents"
"So context engineering is Phase One. What happens to it in Phases Two and Three?"
A student in my Chasing Jarvis MBA workshop asked that.
Context engineering is not a phase. It is the practice that runs through all three. I had described it as a starting condition. It is a continuous discipline.
The three phases, clarified:
→ Phase 1: Research, Design & Foundations
Output: foundational markdown files (architecture.md, blueprint.md, ui_ux.md, security.md). Allow 3–7 days. This phase determines everything that follows. Phase 2 chaos is almost always a Phase 1 failure — not of effort, but of clarity.
→ Phase 2: The Build Phase
Context engineering goes active. Watch the context window — act at 80%, beyond which hallucinations increase. Maintain CLAUDE.md after every milestone. When the session approaches its limit: write a handoff file. It bridges what the model cannot remember itself.
→ Phase 3: Debug, Audit & Deploy
Built ≠ finished. Manual testing first. Playwright MCP for automated coverage. Three-model security audit: Claude Opus + GPT + Gemini Pro. Each model has different blind spots. Run at least two.
The article also introduces three layers of agent memory:
→ Layer 1 — Markdown files (CLAUDE.md / AGENT.md): active sprint context. Start here on every project.
→ Layer 2 — RAG: for large document corpora only. Do not use because it sounds sophisticated.
→ Layer 3 — The Curator: long-term, compounding knowledge via wiki graph and MCP.
Not alternatives. A stack.
This methodology is tool-agnostic. The three phases work equally across Claude Code, Augment Code, Codex Open Code, and others.
What it is not agnostic to is the discipline you bring to it.
Full article — links in the comments: 👇
→ Medium
→ Substack
#FromLabToLife #AI #ContextEngineering #CodingAgents #ChasingJarvis #AIAgents #AugmentCode
𝟵𝟱% 𝗼𝗳 𝗲𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗔𝗜 𝗽𝗶𝗹𝗼𝘁𝘀 𝗽𝗿𝗼𝗱𝘂𝗰𝗲 𝗻𝗼 𝗺𝗲𝗮𝘀𝘂𝗿𝗮𝗯𝗹𝗲 𝗯𝘂𝘀𝗶𝗻𝗲𝘀𝘀 𝗶𝗺𝗽𝗮𝗰𝘁.
⚠️ Not a technology problem. An organisation problem.
That's the MIT NANDA finding from August 2025 — and it's the founding premise of everything I've been building for the past three years.
Today I'm publishing Article-1 of the #ØØT Research Series: the complete overview of the Organisation of Tomorrow (ØØT) framework.
#ØØT is an open-source GitHub framework for partner-run, AI-augmented organisations.
👉 Not a consulting methodology.
👉 Not a SaaS platform.
👉 Not a framework you need a vendor to implement.
A complete operational stack — free to adopt, built on open standards, zero vendor lock-in.
The article "𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝘁𝗵𝗲 𝗢𝗿𝗴𝗮𝗻𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝗧𝗼𝗺𝗼𝗿𝗿𝗼𝘄" covers everything a founder needs to understand before building or transforming:
→ The 5 theses behind #ØØT — grounded in MIT, McKinsey, Microsoft, HBS, and METR research
→ The Klarna Test — a mandatory blocking gate that prevents the failure mode Klarna made famous
→ Three generations: what's operational today, what ships in 6–12 months, and what's research-stage
→ Cloud track vs. privacy track — full operational parity, full data sovereignty, your choice
→ The Collecting Brain — why your firm's knowledge graph is its most valuable compounding asset
→ SKILL.md files — how to make AI methodology portable across every tool, forever
→ Three install paths — including a 60–90 min agent-assisted option for non-technical founders
→ Why this works beyond tech: any industry, any founder
This is my contribution from 30 years of building companies at the frontier of technology.
#ØØT is the first open-source organisational framework to address all four structural gaps simultaneously:
resistance management · output-based compensation · agentic knowledge infrastructure · data sovereignty
No comparable framework occupies all four corners.
If you're building from scratch or upgrading what you have — this is where to start.
🔗 All article links (GitHub · Medium · Substack) are in the comments below 👇
#OrganisationOfTomorrow #OpenSource #AI #FutureOfWork #AgenticAI #Entrepreneurship #AIStrategy #KnowledgeManagement #DigitalTransformation
𝗧𝗵𝗲 𝗺𝗮𝗰𝗵𝗶𝗻𝗲 𝗶𝘀 𝗿𝗲𝗮𝗱𝘆. 𝗧𝗵𝗲 𝗾𝘂𝗲𝘀𝘁𝗶𝗼𝗻 𝗶𝘀 — 𝗮𝗿𝗲 𝘆𝗼𝘂?
Coding agents that write production code. Design agents that ship interfaces. Research agents that synthesise thousands of pages in minutes. Automation pipelines that run while you sleep.
All of it exists. Right now. Today.
And yet most business professionals are still standing on the outside — watching the revolution happen to other people.
That's the gap #ChasingJarvis was built to close.
This is the first post in a series I'm launching — a visual summary of the Chasing Jarvis course, delivered as a mid-century magazine cover collection. Each cover captures one core module. One idea. One shift in how you think about AI.
Because here's what I've learned running this course across @COTRUGLI MBA cohorts:
→ The tools are not the hard part
→ The hard part is knowing what to ask, how to structure your intent, and how to give an AI agent the context it needs to actually deliver
→ That skill — context engineering — is the new competitive advantage. And it has nothing to do with coding.
VS Code. Google AI Studio. Augment Code. Claude. NotebookLM. Nano Banana Pro.
I teach all of it. Not as a technology course — as a business transformation course.
Because the professionals who learn to orchestrate these tools today are not just more productive.
They are building the companies the rest of the market hasn't imagined yet.
The series continues. Follow along and leave your thoughts in the comments. 👇
#ChasingJarvis #AIAgents #AITools #VanguardMBA #COTRUGLI #ContextEngineering #AIEducation
What if your team's collective intelligence never retired, quit, or forgot?
Every organisation leaks knowledge.
The senior partner who leaves takes 15 years of client patterns with her. The PhD student who graduates takes 500 papers with him. The engineer who moves teams takes the why behind every architectural decision — leaving only the what.
We've been building a fix.
#TheCurator v3.0 introduces Shared Brain — a collective, compounding knowledge graph that grows smarter every time any member of your team reads, researches, or learns.
Here's what that looks like in practice:
🔬 Research teams 4 researchers × 20 papers/week × 50 weeks = 4,000 papers/year. No one person reads them all. With Shared Brain, every ingested paper compounds into a collective wiki — contradictions flagged, concepts cross-linked, sources cited. Friday's meeting goes from 2 vague hours to 30 focused minutes.
🎓 University cohorts 20 students. One semester. Five papers each per week. By December: a 500-page collective wiki that no individual could have built alone — every concept cross-referenced, every contributor's insight attributed. The cohort's shared understanding, queryable forever.
🏢 Consulting firms "Why did we choose this approach for a similar client in 2022?" — answered in seconds. Institutional memory that survives partner departures. New hires productive in days, not months. The firm's real competitive moat is the patterns it has recognised over years. The brain remembers them.
��� Engineers & product teams "Why did we pick PostgreSQL over MongoDB for the auth service?" — Claude reads the collective via MCP, returns the answer with a citation to a 2023 architectural decision record. That's not search. That's reasoning over your team's accumulated knowledge.
Read more in the latest article "The Shared Brain: When Second Brains Start Thinking Together" writen by @DrazenKapusta and me. @COTRUGLI Business School COlab · The Curator Research Series · May 2026
Full article links in the comments 👇
Your AI agent is burning most of its compute rediscovering things it already knew.
Pinecone — a vector database company — recently shipped a product that essentially admits vector search alone is not enough. SAP spent over a billion euros on AI memory infrastructure. Google made knowledge architecture the headline of Cloud Next. Microsoft keeps doubling down on graph-based memory.
When that many serious infrastructure players move simultaneously in the same direction, the problem they're racing to solve is real.
It's called the agent memory problem. And it's the subject of my fourth article in the From Life to Lab series.
Here's the short version of why this matters:
RAG — the dominant retrieval approach of the chatbot era — was built for a simple transaction. User asks question → system fetches similar chunks → model generates answer. For basic Q&A, it works.
Agents are different. An agent doesn't ask a question and stop. It runs a task across multiple systems, sources, and steps. And for that, it needs a bundle of context — policy plus exception, contract clause plus the definition that changes its meaning, code architecture plus the feature spec plus the existing implementation. Miss one piece and you get plausible-sounding hallucinations.
I documented hallucination rates exceeding 20% on context-dependent queries in my own RAG research. The context window helped — a lot, actually. But even a million-token window degrades under pressure. Ask anyone building seriously with coding agents.
The industry is converging on different memory shapes for different knowledge types:
— Vector search for prose and fuzzy retrieval
— Tree/hierarchical approaches for structured documents
— Tabular models for business data (SAP's billion-euro bet)
— Graphs for relational reasoning
No single solution wins. Real agents need a combination.
But there's an approach the current conversation is largely missing — and it's one I've been building toward for over a year.
A second brain wiki: a compounding knowledge graph made of plain markdown files, running locally, owned entirely by you, connectable to any LLM via MCP. Not a new vendor to pay. Not a proprietary database. Files on your computer that grow smarter with every source you add.
With My Curator MCP, any MCP-compatible model can now use this graph as its memory layer — reading across thousands of interconnected nodes, traversing relationships, and writing findings back into the wiki for future sessions.
Generation one. Open questions remain. But the direction feels right.
Full article in the comments — Medium, Substack, and GitHub.
What's your biggest frustration with agent memory right now? Retrieval quality? Token cost? Staleness? Or something else entirely?
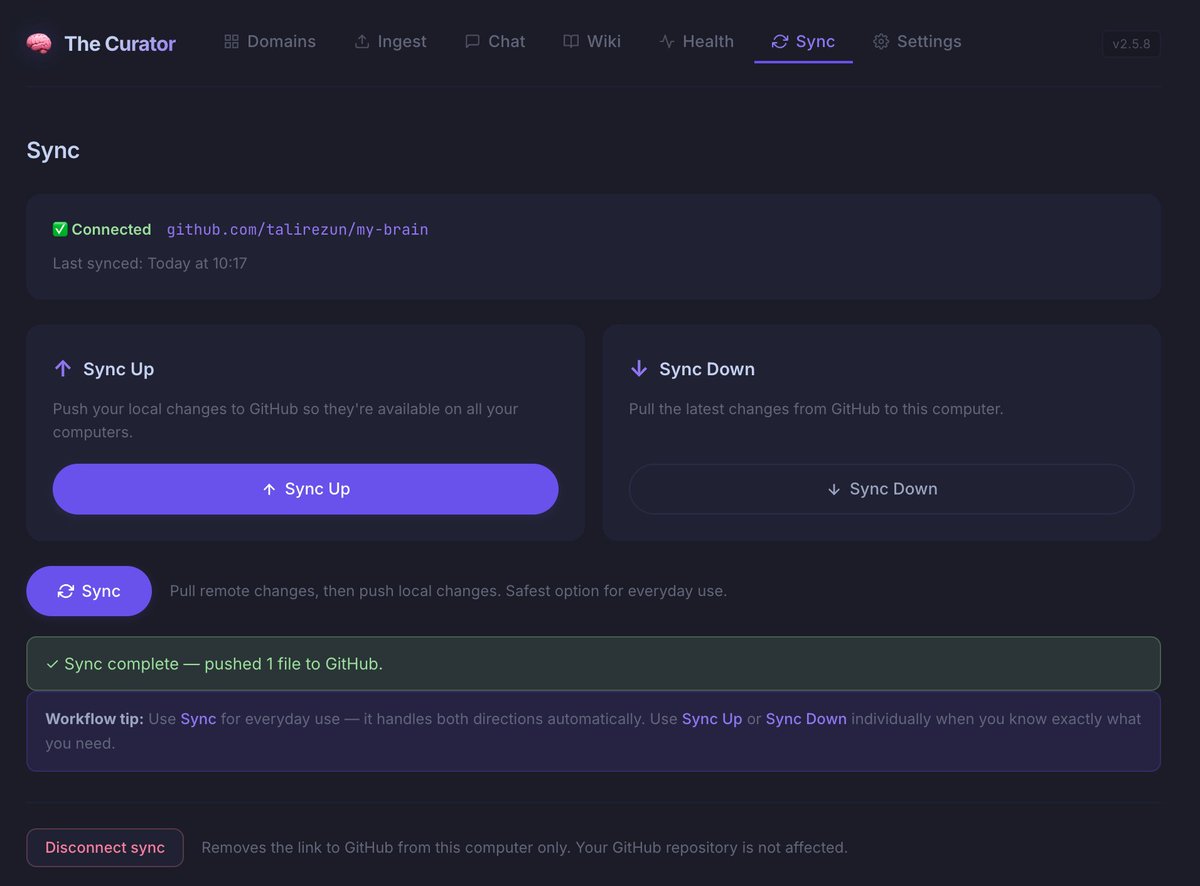
@obsdmd users — there's now a free alternative for syncing your vaults and your second brains.
And it comes with something Obsidian Sync was never designed to offer.
I've been building #TheCurator — an open-source, AI-powered second brain that runs locally, speaks fluent markdown, and plugs directly into your Obsidian vault.
Here's what the full 𝗖𝘂𝗿���𝘁𝗼𝗿 𝗳𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 gives you:
🧠 THE CURATOR APP
Drop in a PDF, article, or research document. The AI (Gemini, Claude, or a local Ollama model) doesn't just index it — it synthesises it into structured atomic wiki pages: entities, concepts, summaries. Every new document compounds into what's already there. Your knowledge graph grows denser with every ingest.
All output? Plain markdown files. Living in a folder. Fully readable in Obsidian — graph view, backlinks, everything.
🔄 FREE SYNC — ACROSS EVERY MACHINE
The Curator syncs your complete knowledge base through a private GitHub repository.
Compared to @obsdmd Sync ($48/yr):
✅ Free forever
✅ Unlimited version history via Git
✅ Up to 5 GB storage (free GitHub tier)
✅ Any number of collaborators — just share a PAT
✅ Syncs your wiki, conversations, and AI config together
✅ Full recovery — if you delete a page, Git has it
The trade-off: it's a manual push/pull rather than auto-background sync. A deliberate habit, not a limitation.
🤖 MY CURATOR MCP
This is where it gets interesting for 2026.
#TheCurator runs as an MCP server. Claude Desktop, Claude Code, or any frontier model can query your second brain directly — search across domains, retrieve full node content, and (in the upcoming v2.5.0 release) write compiled insights back into the wiki from a conversation.
Your knowledge base becomes a live, queryable context layer for AI — not a static folder.
#TheCurator doesn't replace Obsidian. It plugs into it.
You write your notes in Obsidian. The Curator compiles research, articles, and conversations into the same vault. The graph view connects everything. The MCP makes it accessible to your AI tools.
One ecosystem. Everything interoperable. Zero sync subscription.
→ https://t.co/D2zszXm8oC
Building your second brain in 2026 shouldn't cost a subscription. It should compound your thinking.
#SecondBrain #Obsidian #PKM #BuildInPublic #AI #KnowledgeManagement #MCP #OpenSource
When someone spends 13.5 hours installing your open-source tool, ingesting their own documents, testing every feature, and then writes a careful 3,000-word analysis of what it actually means — that's not a review. That's a gift.
Huge thanks to Robin Good for his deep dive into #TheCurator and the second-brain paradigm shift it sits inside.
What struck me most: Robin didn't just describe what the app does. He framed why it matters in a way I hadn't fully articulated myself.
→ Traditional second brains (Notion, Roam, Obsidian) let you search and retrieve — but they don't get smarter when you feed them more sources.
→ Andrej Karpathy's LLM-wiki concept (April 2026) flipped the question: what if the AI compiled your knowledge into a persistent, structured wiki — and every new source updated that wiki rather than expanding the pile of documents?
→ #TheCurator is my open-source implementation of that idea, built for non-developers.
But Robin pushed the framing further. He calls it knowledge infrastructure — a compiled intelligence that sits behind an expert's work and compounds with every source they add.
His sharpest line, paraphrased: the authority gap you'll feel in twelve months is the knowledge base you're not building today.
A few takeaways from his piece I'm carrying with me:
🔹 The hybrid principle — let the LLM build the map, but walk the territory yourself. The wiki is scaffolding, not the building.
🔹 Health checks matter more as the graph grows. Orphans, semantic duplicates, and broken links compound inside a compounding system.
🔹 The MCP bridge is what turns a personal wiki into deployable knowledge infrastructure — your compiled intelligence becomes a live layer behind Claude Desktop and other frontier AI.
🔹 His "Honest Caveats" section is the kind of integrity I hoped reviewers would bring. Yes, installation requires Node.js. Yes, this is early-stage. He says it plainly.
This is exactly the kind of engagement that makes building in the open worth it.
If you're curious about where second brains are heading — and what compounding knowledge actually looks like in practice — Robin's piece is the most thorough public walkthrough of The Curator that exists right now.
Link to Robins article in the comments 👇
#TheCurator #SecondBrain #LLMWiki #KnowledgeManagement #Karpathy #OpenSource
The Brain Is Ready. The Body Is the Problem.
This is where we are in May 2026.
───────────────────────
For three years, the question was: are AI models good enough?
That question is answered. Context windows hit 1 million tokens. Open-source models now rival the closed frontier. The intelligence we need to automate our daily work genuinely exists.
The new question is harder:
How do we build an AI assistant that actually does the things we spend hours doing manually on our computers every day — while keeping our data safe?
───────────────────────
This is the direction the entire industry is moving right now.
@AnthropicAI built Dispatch — message Claude from your phone, come back to find the work done on your Mac.
@OpenAI rebuilt Codex as a full desktop agent — it sees your screen, clicks, types, and runs tasks in the background while you keep working.
@openclaw went from zero to 347,000 GitHub stars in 5 months — the most-starred software repo in history — because one developer built what everyone actually wanted: an AI assistant that lives in the messaging apps you already use and works for you while you get on with your life.
The direction is clear. The obstacles are not.
───────────────────────
→ Social media APIs are locked. You cannot automate posting to X, Facebook, or Instagram.
→ The open web is closing. Platforms are actively blocking AI agent access.
→ Cloud agents need your data — but your most sensitive data cannot leave your environment.
→ Local models are almost capable enough. But not yet for most daily tasks.
We have the brain. Building the right body for it — one that can reach the data it needs, through channels that are increasingly locked, without compromising the privacy of what it touches — is the defining infrastructure challenge of the next two years.
───────────────────────
In my new From Lab to Life article, I document exactly where we stand:
✦ Why 1M token context was the silent prerequisite for everything
✦ What OpenClaw proved — and why the big labs are now building the same thing
✦ Anthropic vs OpenAI: two architectures, one race
✦ The API barrier and the privacy dilemma — neither resolved cleanly yet
✦ A practical framework for connecting your agent to your data safely
✦ What open-source models mean for data sovereignty
Links in the first comments.
#FromLabToLife #AI #AIAgents #FutureOfWork #ContextEngineering #Privacy #OpenSource #Automation
The last 6 months were my most creative period as a builder. Here's what I shipped from Q4 2025 to Q2 2026 — all powered by Anthropic Claude, GPT & Gemini models 👇
🏔️ @MountVacation 𝗠𝗖𝗣 𝗦𝗲𝗿𝘃𝗲𝗿 (open-source)
One of the first open-source MCP servers for the tourism industry. Built with @augmentcode + Claude Haiku 4.5. Fast, lightweight, and part of the Anthropic & Gradio Hackathon.
→ https://t.co/AG7So2vXja
⚖️ 𝗠𝗼𝗷 𝗔𝗜
A multi-agent RAG platform helping users navigate Slovenia's complex building legislation. Two orchestrated agents. One year in the making. Built with @augmentcode + Claude Sonnet, @antigravity + Gemini Pro.
→ https://t.co/UcSvJwjm1t
💡 @luminawidget — 𝗔𝗜 𝗪𝗶𝗱𝗴𝗲𝘁 𝗣𝗹𝗮𝘁𝗳𝗼𝗿𝗺
My first production SaaS shipped entirely with AI coding agents. A RAG platform letting businesses deploy custom AI chat widgets. Built with @augmentcode + Claude Haiku 4.5 for under $100 in AI credits.
→ https://t.co/Shm0cxSdBm
🤖 𝗔𝗥𝗜𝗔 — 𝗔𝗜 𝗔𝘃𝗮𝘁𝗮𝗿 𝗣𝗹𝗮𝘁𝗳𝗼𝗿𝗺
The most complex build yet. A full-stack local-first platform: Next.js dashboard + Node.js backend + embeddable React widget. ~7,000 lines of code. 300+ coding agent sessions. 4M+ Augment credits. Built with @augmentcode #Intent + Claude Opus 4.5 → Opus 4.6. Still in active development for a client.
🧠 𝗧𝗵𝗲 𝗖𝘂𝗿𝗮𝘁𝗼𝗿 & 𝗠𝘆 𝗖𝘂𝗿𝗮𝘁𝗼𝗿 𝗠𝗖𝗣 (𝗼𝗽𝗲𝗻-𝘀𝗼𝘂𝗿𝗰𝗲)
An open-source AI knowledge curation system built with Claude Code. Drop any source → it auto-atomizes into an interlinked wiki, lets you chat with your knowledge, and visualizes everything as an Obsidian graph. Built on Karpathy's LLM-Wiki concept.
→ https://t.co/D2zszXm8oC
𝗪𝗵𝗮𝘁 𝗜'𝘃𝗲 𝗹𝗲𝗮𝗿𝗻𝗲𝗱:
→ Haiku 4.5 is criminally underrated for production SaaS
→ Opus 4.6 is where serious orchestration lives
→ Claude Code is a different kind of creative tool
→ The bottleneck is no longer code — it's context and vision
Not a developer by training. An entrepreneur who learned to build by orchestrating AI agents and thinking deeply about context.
If you're curious about any of these projects, drop a comment or connect.
#AI #ClaudeAI #Anthropic #BuildingWithAI #VibeCoding #MCP #RAG #AIAgents #SaaS #Entrepreneurship
𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗮 𝘀𝗲𝗰𝗼𝗻𝗱 𝗯𝗿𝗮𝗶𝗻 𝗶𝘀 𝗿𝗲𝘄𝗮𝗿𝗱𝗶𝗻𝗴. 𝗤𝘂𝗲𝗿𝘆𝗶𝗻𝗴 𝗶𝘁 𝘄𝗶𝘁𝗵 𝗮 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗺𝗼𝗱𝗲𝗹 𝗶𝘀 𝘁𝗵𝗲 𝗺𝗼𝗺𝗲𝗻𝘁 𝗶𝘁 𝗯𝗲𝗰𝗼𝗺𝗲𝘀 𝗶𝗿𝗿𝗲𝗽𝗹𝗮𝗰𝗲𝗮𝗯𝗹𝗲.
Most personal knowledge management tools follow the same loop: ingest → search → retrieve. That's useful. But it's not thinking.
The second brain I've been building with #TheCurator works differently. Every source I ingest doesn't just add files — it builds a persistent, graph-shaped knowledge structure. Entities. Concepts. Summaries. Thousands of nodes, dozens of domains, years of intellectual work — all interconnected.
The problem? The graph is something you look at in Obsidian. The synapses — the actual connections between all those nodes — are mostly invisible to you while you're inside it.
That's exactly what #MyCuratorMCP changes.
From v2.3 onwards, #TheCurator ships a local, read-only MCP server that exposes your entire knowledge graph to any Model Context Protocol-compatible client — @claudeai Desktop with Opus or Sonnet, @augmentcode, VS Code with a coding agent, @lmstudio with a local model.
This is not "another way to read your files." It's a graph-native access path. Ten dedicated tools let a frontier model traverse topology, follow multi-hop connections, pull bidirectional backlinks, and search across every domain simultaneously — the way an analyst queries a database, not the way a search engine retrieves documents.
In practice, it looks like this:
→ "What are the most important ideas in my AI domain that I've never explicitly connected to my business strategy domain?"
→ "Pull every concept tagged `crisis-response` across all my domains and build a citation skeleton for my white paper."
→ "Identify recurring patterns in my last six months of writing that I haven't named yet — and cite the specific sources."
That is a frontier model doing deep research over your own intellectual history. Full citations. No hallucinations beyond your wiki. No data ever leaving your machine.
Most "AI for knowledge" tools are RAG wrappers — they re-derive answers from raw files at query time and forget everything afterwards. Nothing compounds. Nothing traverses.
#TheCurator inverts that. Ingest builds the structure. MCP exposes it. The model reasons against it.
The difference between "I have a folder of notes" and *"I have a queryable, compounding extension of my own thinking that any frontier model can reason against on demand."*
#MyCuratorMCP setup takes under 2 minutes from the Settings tab.
👉 https://t.co/D2zszXm8oC
What would you ask a frontier model if it had access to everything you've ever learned?
`#AI #PersonalKnowledge #MCP #SecondBrain #TheCurator #KnowledgeManagement #FrontierAI #OpenSource`
The oldest rule of human progress is ruthless and simple:
If it wasn't written down — it didn't happen.
Caesar. Aristotle. Da Vinci. Einstein.
We know these people not just because of what they did, but because of what was recorded. Entire civilisations vanished — brilliant cultures, remarkable individuals, decades of accumulated wisdom — not because they lacked knowledge, but because that knowledge was never structured and preserved.
Now ask yourself this:
You have been learning for decades. Building expertise. Making expensive mistakes. Synthesising ideas across disciplines in ways that are genuinely yours.
When you are gone — what survives?
For most people, the honest answer is: almost nothing structured.
This is what drove me to build #TheCurator.
The concept starts with an insight from @karpathy — one of the clearest minds in AI. Instead of using AI to search your documents every time you have a question (the way most tools work), what if AI continuously built and maintained a persistent, interlinked wiki from everything you know?
Not retrieval. Compilation.
Knowledge that doesn't reset. Knowledge that compounds.
Every article you ingest doesn't just get added — it updates every related page that already exists. Concepts grow richer. Connections deepen. The synthesis reflects everything you have ever read, thought, and recorded.
This is how human expertise actually works inside the brain.
Now it can be externalised.
#TheCurator is the app I built to make this accessible to anyone.
Drop in a PDF, an article, a research paper. The AI decomposes it into interconnected nodes — Entities (people, tools, organisations), Concepts (ideas, frameworks), and Summaries (source narratives). Everything cross-linked. Everything stored as simple markdown files on your computer.
You visualise it in Obsidian — a stunning graph where you literally see the shape of your thinking.
You explore it in depth through the #MyCurator MCP — connecting frontier models like Claude Opus directly to your second brain for real research and synthesis.
And with GitHub sync, you can share it. With your team. With your students. With the people who come after you.
The great figures of history were remembered because their knowledge was recorded, structured, and made accessible to others.
The medium was stone, papyrus, paper, printing press.
Today the medium is a folder of markdown files.
Simple. Lightweight. Open. Durable.
Your expertise doesn't have to die with you.
Start building: https://t.co/D2zszXm8oC
Full article in comments 👇
#SecondBrain #KnowledgeManagement #AI #Thecurator #PersonalKnowledge #Leadership #LifelongLearning #Obsidian
🧠 This is what my second brain looks like.
Every dot is a thought. Every line is a connection. And every cluster is an idea growing richer with every article I feed it.
A few weeks ago, I announced 𝗧𝗵𝗲 𝗖𝘂𝗿𝗮𝘁𝗼𝗿 — the open-source app I built to turn the overwhelming act of reading into something that compounds. Today, for the first time, I'm showing you what actually comes out the other side.
What you're watching in this video is my own knowledge graph — rendered live inside @obsdmd — as 𝗧𝗵𝗲 𝗖𝘂𝗿𝗮𝘁𝗼𝗿 ingests my writing, one article at a time. I'm at 30 articles in. I've written more than 100. The network you see forming is only the beginning.
Look closely. The colours are not decoration — they're the architecture:
🔵 𝗕𝗹𝘂𝗲 = 𝗘𝗻𝘁𝗶𝘁𝗶𝗲𝘀. T̲h̲e̲ ̲n̲o̲u̲n̲s̲.̲ Specific people, companies, tools. Andrej Karpathy. Anthropic. Claude. GitHub. Each one a proper name with a dedicated page that accumulates everything I've ever read about it.
🟢 𝗚𝗿𝗲𝗲𝗻 = 𝗖𝗼𝗻𝗰𝗲𝗽𝘁𝘀. T̲h̲e̲ ̲i̲d̲e̲a̲s̲.̲ Context engineering. Vibe coding. Agentic workflows. The frameworks and techniques that don't belong to any single source — the connective tissue of how I think.
🟣 𝗣𝘂𝗿𝗽𝗹𝗲 = 𝗦𝘂𝗺𝗺𝗮𝗿𝗶𝗲𝘀. T̲h̲e̲ ̲n̲a̲r̲r̲a̲t̲i̲v̲e̲s̲.̲ Each article I've written becomes one purple node — the story that pulls the blue and green together and stitches them into the network.
The dots that grow largest are the ones most referenced across my work. Watch them. They are a visual heat map of my actual thinking — not what I claim to care about, but what I've actually been writing about for years. The biggest green node right now? 𝘊𝘰𝘯𝘵𝘦𝘹𝘵 𝘦𝘯𝙜𝘪𝘯𝘦𝘦𝘳𝘪𝘯𝙜. The biggest blue? 𝘊𝘭𝘢𝘶𝘥𝘦. Unsurprising. Revealing.
Every new article I ingest doesn't just add nodes. It strengthens the existing ones. The Concept page for "context engineering" gets richer. The Entity page for "Anthropic" gets denser. The links between them multiply. This is the fundamental shift — from a file cabinet to a neural network.
This is what RAG can never give you. RAG retrieves. 𝗧𝗵𝗲 𝗖𝘂𝗿𝗮𝘁𝗼𝗿 remembers — and compounds.
In Phase 1, I'm only ingesting my own articles. In Phase 2, I'll add the hundreds of PDFs, research papers, podcast transcripts, and book summaries I've been hoarding for years. I'll let you watch that grow too.
The app is open source — built because we needed it for our scientific work at @COTRUGLI Business School. When you're researching frontier technologies, managing hundreds of papers, and teaching the next generation of AI leaders, you need tools that reveal the hidden connections between ideas, not just store them.
Our community of scientists, AI experts, and MBA students will be improving it together — learning about open-source development while building the knowledge tools we actually need. This is how we teach coding: by solving real problems.
The Curator GitHub link in the comments 👇
Full Article on Substack "Three Philosophies, One Goal;A Practitioner’s Comparison of Augment Code, Claude Code, and Codex CLI": https://t.co/kiL2PkkJVm
@augmentcode, @claudeai Code, or @OpenAI Codex CLI — which one?
I have spent months working seriously with all three. Building production platforms. Draining credit allocations. Crossing context limits. Using them in combination and in isolation.
And the honest answer is: that is the wrong question.
The right question is — which one, for what kind of work, at what stage, at what cost?
In my latest article from the From Lab to Life collection, I break down all three frontier coding agents across the dimensions that actually matter:
→ Context engines — how each tool understands your codebase (and why this is more important than which model powers it)
→ Memory systems — how each tool remembers what it knows across sessions
→ Multi-agent orchestration — what it actually means in practice, not in demos
→ Pricing reality — what $60, $200, or $20 actually gets you under real working conditions
A few things I cover that most comparisons skip:
Augment Code's $200 plan can be exhausted in 2 days with intensive Intent + Opus 4.6 use. That is not a flaw — it is an honest pricing signal about what you are deploying.
Claude Code's $200 Max plan is remarkably generous compared to using the same Anthropic models via API. One developer tracked the equivalent API cost at 15x+ the plan price.
Codex CLI's open-source codebase under Apache 2.0 matters more than most people discuss — especially in regulated industries.
But above all of this: the tool you choose matters less than how well you prepare it to work.
Context engineering remains the skill that doesn't depreciate. Every model upgrade amplifies good context. It also amplifies bad context.
Full article linked below — available on both Medium and Substack.
#FromLabToLife #AI #CodingAgents #AugmentCode #ClaudeCode #CodexCLI #ContextEngineering #AIProductDevelopment #FutureOfDevelopment
🚨 𝗨𝗥𝗚𝗘𝗡𝗧: 𝗜𝗳 𝘆𝗼𝘂'𝗿𝗲 𝗯𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝘄𝗶𝘁𝗵 𝗝𝗮𝘃𝗮𝗦𝗰𝗿𝗶𝗽𝘁, 𝗿𝗲𝗮𝗱 𝘁𝗵𝗶𝘀 𝗡𝗢𝗪.
One of the most widely used npm packages — 𝗔𝘅𝗶𝗼𝘀 (~100M weekly downloads, present in ~80% of cloud environments) — was hit by a supply chain attack on March 31, 2026.
A hacker compromised the account of the primary Axios maintainer and published 𝘁𝘄𝗼 𝗯𝗮𝗰𝗸𝗱𝗼𝗼𝗿𝗲𝗱 𝘃𝗲𝗿𝘀𝗶𝗼𝗻𝘀 that silently install a Remote Access Trojan (RAT) the moment you run npm install. The attack works on Windows, macOS, and Linux. No user interaction required.
⚠️ Compromised versions:
- [email protected]
- [email protected]
✅ Safe versions:
- [email protected] (current stable — use this or lower)
- [email protected] (legacy safe version or lower)
𝗪𝗵𝘆 𝘁𝗵𝗶𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀 𝗳𝗼𝗿 𝘃𝗶𝗯𝗲 𝗰𝗼𝗱𝗲𝗿𝘀, 𝗲𝘀𝗽𝗲𝗰𝗶𝗮𝗹𝗹𝘆: Many of you are using Axios without knowing it. It's baked into React, Vue, Angular, and dozens of tools you use daily. If you ran npm install on a new or updated project between March 31, 00:21 UTC and 03:15 UTC, you may be affected.
⚠️ npm audit will 𝗡𝗢𝗧 catch this. The malware self-deletes its traces.
🔍 𝗦𝘁𝗲𝗽 𝟭 — 𝗖𝗵𝗲𝗰𝗸 𝘆𝗼𝘂𝗿 𝘃𝗲𝗿𝘀𝗶𝗼𝗻
Open your terminal in your project folder and run: 𝘯𝘱𝘮 𝘭𝘪𝘴𝘵 𝘢𝘹𝘪𝘰𝘴
Or check your p̲a̲c̲k̲a̲g̲e̲-̲l̲o̲c̲k̲.̲j̲s̲o̲n̲ and search for "axios".
🔍 𝗦𝘁𝗲𝗽 𝟮 — 𝗤𝘂𝗶𝗰𝗸 𝘀𝗰𝗮𝗻 𝗳𝗼𝗿 𝗰𝗼𝗺𝗽𝗿𝗼𝗺𝗶𝘀𝗲
𝘯𝘱𝘮 𝘭𝘪𝘴𝘵 𝘢𝘹𝘪𝘰𝘴 2>/𝘥𝘦𝘷/𝘯𝘶𝘭𝘭 | 𝙜𝘳𝘦𝘱 -𝘌 "1\.14\.1|0\.30\.4"
If you see a match → treat your environment as compromised.
🛠️ If you're on a compromised version:
1. Downgrade: set "axios": "1.14.0" in package.json
2. Delete node_modules and package-lock.json
3. Run 𝘯𝘱𝘮 𝘪𝘯𝘴𝘵𝘢𝘭𝘭
4. Rotate ALL credentials immediately — API keys, SSH keys, tokens, cloud secrets.
5. Everything the machine had access to.
6. Check for RAT artifacts:
- macOS: /Library/Caches/com.apple.act.mond
- Windows: %PROGRAMDATA%\wt.exe
- Linux: /tmp/ld.py
𝗧𝗵𝗲 𝗯𝗶𝗴𝗴𝗲𝗿 𝗹𝗲𝘀𝘀𝗼𝗻 ��𝗲𝗿𝗲: This is what a software supply chain attack looks like in the real world. A trusted package. A compromised maintainer. A 39-minute attack window. Millions of installs.
Always pin your versions.
Stay safe out there. Check your repos today. 🔒
#ChasingJarvis #VanguardMBA #COTRUGLI #AIEducation #CyberSecurity #JavaScript #SupplyChainAttack #DeveloperSecurity
𝗢𝘃𝗲𝗿 𝘁𝗵𝗲 𝗽𝗮𝘀𝘁 𝗺𝗼𝗻𝘁𝗵, 𝗮𝗹𝗺𝗼𝘀𝘁 𝗲𝘃𝗲𝗿𝘆 𝗺𝗲𝗲𝘁𝗶𝗻𝗴 𝗜 𝘁𝗼𝗼𝗸 𝗳𝗼𝗹𝗹𝗼𝘄𝗲𝗱 ����𝗵𝗲 𝘀𝗮𝗺𝗲 𝗽𝗮𝘁𝘁𝗲𝗿𝗻.
An entrepreneur. A founder. A client. All of them aware that something profound is happening in software development. All of them stuck at the same wall: they've seen the magic on social media, but they have no idea where to actually start.
This vacuum of understanding is the gap I've been living inside — and my new article "𝗧𝘄𝗼 𝗪𝗼𝗿𝗹𝗱𝘀 𝗼𝗳 𝗖𝗼𝗱𝗲: 𝗧𝗵𝗲 𝗚𝗮𝗽 𝗕𝗲𝘁𝘄𝗲𝗲𝗻 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗢𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝗟𝗲𝗴𝗮𝗰𝘆 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁" is my attempt to map it.
For the past two months, I've been deep in multi-agent orchestration: @augmentcode #Intent platform, where you don't talk to a single coding agent — you talk to an orchestrator that spins up parallel worker agents, review agents, smoke test agents. All running simultaneously. All aligned to a shared 𝐬𝐩𝐞𝐜 that lives in the orchestrator's context window.
💡 The metaphor I keep returning to: 𝘁𝗵𝗲 𝘀𝗵𝗶𝗳𝘁 𝗳𝗿𝗼𝗺 𝗮 𝘀𝗼𝗹𝗼 𝗶𝗻𝘀𝘁𝗿𝘂𝗺𝗲𝗻𝘁 𝘁𝗼 𝗮 𝘀𝘆𝗺𝗽����𝗼𝗻𝘆.
→ The first era of coding agents was revolutionary. One agent at a time, inside an #IDE. It changed everything for non-developers like me. But it had a ceiling — context collapse at the 70-80% mark, where the codebase outgrew what any single agent could hold. Exhausting.
→ The second era is something qualitatively different.
𝗧𝗼 𝗺𝗮𝗸𝗲 𝗶𝘁 𝗰𝗼𝗻𝗰𝗿𝗲𝘁𝗲: Last month, I built a fully functional AI avatar deployment platform — live facial expressions, custom personas, real-time voice conversation, API injection layer — in a domain I had zero prior knowledge of. One week of research and context engineering. Three weeks of build.
Not a headline. That's a data point about what the methodology now makes possible.
But here's the part of the article I've been thinking about the most.
This same project put me in direct contact with a traditional development team on the client side. Good developers. Professional. Technically capable.
They had not held their first meeting to discuss the API spec by the time my side was ready to receive it.
No blame. It's a structural difference. My orchestrator is the project lead — it has read the entire specification, knows all dependencies, runs standup asynchronously in real time, and updates the spec when something changes.
These two worlds are not compatible. Not at a process level, not at a rhythm level, not at a documentation level. The gap is real. And it is widening faster than anyone is currently managing for.
𝗧𝗵𝗲 𝗮𝗿𝘁𝗶𝗰𝗹𝗲 𝗰𝗼𝘃𝗲𝗿𝘀:
→ Why the vacuum of understanding exists — and what it actually looks like
→ The two eras of coding agent work, and why the transition matters
→ The collision between orchestration-based development and a traditional team
→ The code quality question, answered honestly
→ How do these two worlds eventually merge?
𝗟𝗶𝗻𝗸 𝘁𝗼 𝘁𝗵𝗲 𝗳𝘂𝗹𝗹 𝗮𝗿𝘁𝗶𝗰𝗹𝗲 𝗶𝗻 𝘁𝗵𝗲 𝗰𝗼𝗺𝗺𝗲𝗻𝘁𝘀 👇
𝗟𝗮𝘀𝘁 𝘄𝗲𝗲𝗸, 𝗜 𝗯𝘂𝗶𝗹𝘁 𝘀𝗼𝗺𝗲𝘁𝗵𝗶𝗻𝗴 𝗜 𝗵𝗮𝗱 𝗻𝗲𝘃𝗲𝗿 𝗯𝘂𝗶𝗹𝘁 𝗯𝗲𝗳𝗼𝗿𝗲. 𝗜𝗻 𝗮 𝗳𝗶𝗲𝗹𝗱 𝗜 𝗸𝗻𝗲𝘄 𝗻𝗼𝘁𝗵𝗶𝗻𝗴 𝗮𝗯𝗼𝘂𝘁.
A client needed an AI avatar platform. Not a chatbot. A real-time audio and video avatar companion — one that listens, speaks, syncs lip movement, receives live API data, and can autonomously engage users without being prompted. Think less sci-fi, more quietly inevitable.
I had never touched this space. No prior experience with Simli, HeyGen, or ElevenLabs integrations. No existing codebase to build from. Zero.
So I followed my three-phase process to the letter.
👉 𝗣𝗵𝗮𝘀𝗲 𝟭 — 5 days of deep context engineering. I researched every available AI avatar service and framework. I mapped the architecture: how audio, video, and API data streams connect and sync in real time. I documented voice cloning options, face generation services, latency requirements, compliance considerations. By the end, I had a complete knowledge base — four technical documents — ready for my agent team.
👉 𝗣𝗵𝗮𝘀𝗲 𝟮 — 30 hours of building across 2 days. @augmentcode #Intent. Two coordinator agents. The first delegated work to 80 worker agents and delivered a working MVP dashboard. The second, now running, has already spun up 31 agents to refine and extend it.
Because Phase 1 was thorough, Phase 2 was not chaos. It was construction.
👉 𝗣𝗵𝗮𝘀𝗲 𝟯 — Testing, debugging, and new feature discovery running in parallel. When you enter a new domain, you only fully understand what is possible once you start using what you built. The onion peels in production. I am still peeling.
The platform now lets you build custom avatars — choose a face, clone a voice, fine-tune a personality to a specific subject. The avatars speak and listen in real time. They receive live data from external services and react to it. And when the heartbeat feature is enabled, they initiate conversations autonomously. Agent companions, not chatbots.
One week. A domain I had never touched. A working MVP.
The process works. Every time.
🔗 Full breakdown of the three phases in my latest article "𝗕𝗲𝗵𝗶𝗻𝗱 𝘁𝗵𝗲 𝗖𝘂𝗿𝘁𝗮𝗶𝗻: 𝗧𝗵𝗲 𝗧𝗵𝗿𝗲𝗲-𝗣𝗵𝗮𝘀𝗲 𝗣𝗿𝗼𝗰𝗲𝘀𝘀 𝗜 𝗨𝘀𝗲 𝘁𝗼 𝗕𝘂𝗶𝗹𝗱 𝗘𝘃𝗲𝗿𝘆 𝗔𝗜-𝗖𝗼𝗱𝗲𝗱 𝗣𝗿𝗼𝗱𝘂𝗰𝘁" — link in the comments.
Have you tried building in a completely new domain with AI agents? What was your experience?
#FromLabToLife #AI #AIAgents #AvatarAI #AugmentCode #ContextEngineering #ProductDevelopment #Builders
𝗘𝘃𝗲𝗿𝘆 𝗱𝗲𝘃𝗲𝗹𝗼𝗽𝗲𝗿 𝗸𝗻𝗼𝘄𝘀 𝘁𝗵𝗲 𝗰𝗹𝗮𝘀𝘀𝗶𝗰 𝘀𝗼𝗳𝘁𝘄𝗮𝗿𝗲 𝗱𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁 𝗹𝗶𝗳𝗲𝗰𝘆𝗰𝗹𝗲:
Requirements gathering → Development → Testing and deployment
Three phases. Decades of practice. The foundation of how the entire industry was built.
AI coding agents did not replace this process. They transformed it.
Here is what changed — and what stayed the same.
🔹 𝗣𝗵𝗮𝘀𝗲 𝟭: Requirements Gathering → Context Engineering
👉 𝗟𝗲𝗴𝗮𝗰𝘆: A business analyst interviews stakeholders. Requirements are written into a spec document. Handed to developers. Weeks pass.
👉 𝗡𝗼𝘄: You are your own analyst, architect, and researcher simultaneously. A research agent helps you build a foundational document covering market, technology stack, integrations, compliance, and architecture — in hours, not weeks. The output is not a requirements doc. It is a living knowledge base your entire agent team will reason from.
👉 𝗪𝗵𝗮𝘁 𝗰𝗵𝗮𝗻𝗴𝗲𝗱: speed and depth. What stayed: garbage in, garbage out. Weak context produces weak software, with or without agents.
🔹 𝗣𝗵𝗮𝘀𝗲 𝟮: Development → Build + Orchestration
👉 𝗟𝗲𝗴𝗮𝗰𝘆: Developers write code. Senior devs review. Junior devs implement. Tickets move across a board. Weeks to months.
👉 𝗡𝗼𝘄: You describe what you want to an orchestrator agent (e.g. @augmentcode, @antigravity ...). It writes a living spec, decomposes the work, and deploys a team of worker agents in parallel. You review, redirect, and maintain architectural judgment. The implementation burden shifts. The thinking burden stays with you.
👉 𝗪𝗵𝗮𝘁 𝗰𝗵𝗮𝗻𝗴𝗲𝗱: who writes the code. What stayed: architecture still requires human judgment. Always.
🔹 𝗣𝗵𝗮𝘀𝗲 𝟯: Testing & Deployment → Debugging + Security + Production
👉 𝗟𝗲𝗴𝗮𝗰𝘆: QA team tests. Bugs logged. Fixed. Deployed by DevOps. Security audit, if you were lucky.
👉 𝗡𝗼𝘄: Debugging is still the most exhausting part — half-manual, half-agent, fully necessary. But the security audit is no longer optional or outsourced. I run three audits with three different AI models before anything goes live. Each one finds something the others miss.
👉 𝗪𝗵𝗮𝘁 𝗰𝗵𝗮𝗻𝗴𝗲𝗱: security is now built into the process, not bolted on. What stayed: you cannot skip testing. The environment just got faster and more capable.
—
The phases did not disappear. They evolved.
The developers who understand both the legacy process and its AI transformation will build things the rest of the world cannot yet imagine.
Full breakdown in my latest From Lab to Life article — link in the comments.
Which phase do you find most different from how you worked before AI? 👇
#FromLabToLife #AI #SoftwareDevelopment #CodingAgents #ContextEngineering #SDLC #ProductDevelopment #Developers