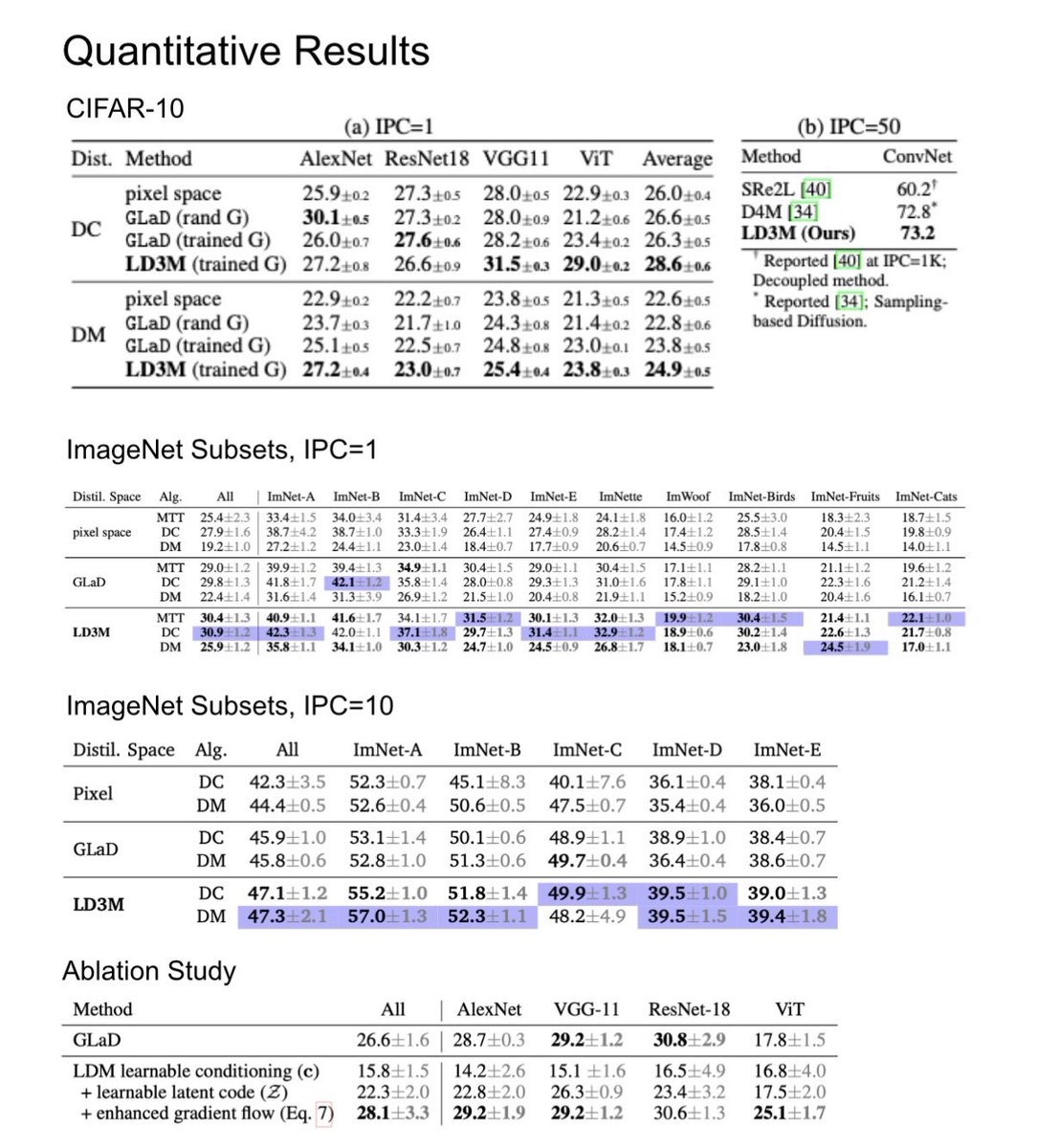
🎉 Our paper “Unlocking Dataset Distillation with Diffusion Models” has been accepted at #NeurIPS 25!
We show how to unlock end-to-end dataset distillation through diffusion models by tackling the vanishing gradient problem!
📄 : https://t.co/fRh4MCqL0I
#DiffusionModels
We will be presenting our CVPR paper When Pretty Isn’t Useful in the afternoon today.
We benchmark modern t2i models and find that newer models make progressively worse synthetic training data and we investigate why!
Come visit us at poster #46.
https://t.co/ejmU6zf9rq
Adamkiewicz et al., "When Pretty Isn't Useful: Investigating Why Modern Text-to-Image Models Fail as Reliable Training Data Generators"
Interesting that while we have "better" image generators, their usefulness as synthetic data generators is declining. Do we need a pivot?
Simple vision pretraining by predicting next step embedding. The embedding itself is trained along with this while stop grad is applied when it is used as a target.
#Meta just released SAM Audio: Segment Anything, but for sound. It’s actually so cool: isolate a voice/instrument/noise with a prompt. Now imagine Meta Ray-Ban (probably a feature already in the making): choose the person you want to listen to… and hear only them. #AI
🔉 Introducing SAM Audio, the first unified model that isolates any sound from complex audio mixtures using text, visual, or span prompts.
We’re sharing SAM Audio with the community, along with a perception encoder model, benchmarks and research papers, to empower others to explore new forms of expression and build applications that were previously out of reach.
🔗 Learn more: https://t.co/FPnfv66UCP
We did some extended research against robot this time!!! Please check it out!
SensHRPS: Sensing Comfortable Human-Robot Proxemics and Personal Space With Eye-Tracking
https://t.co/vEbAJEtEqk
What a transformative experience at #NeurIPS. Lessons learned:
- History rhymes: RL and Meta-Learning are back on the menu.
- Things move fast and going to move faster. As a scientist, plan your next years carefully! I will definitely.
- Networking is king.
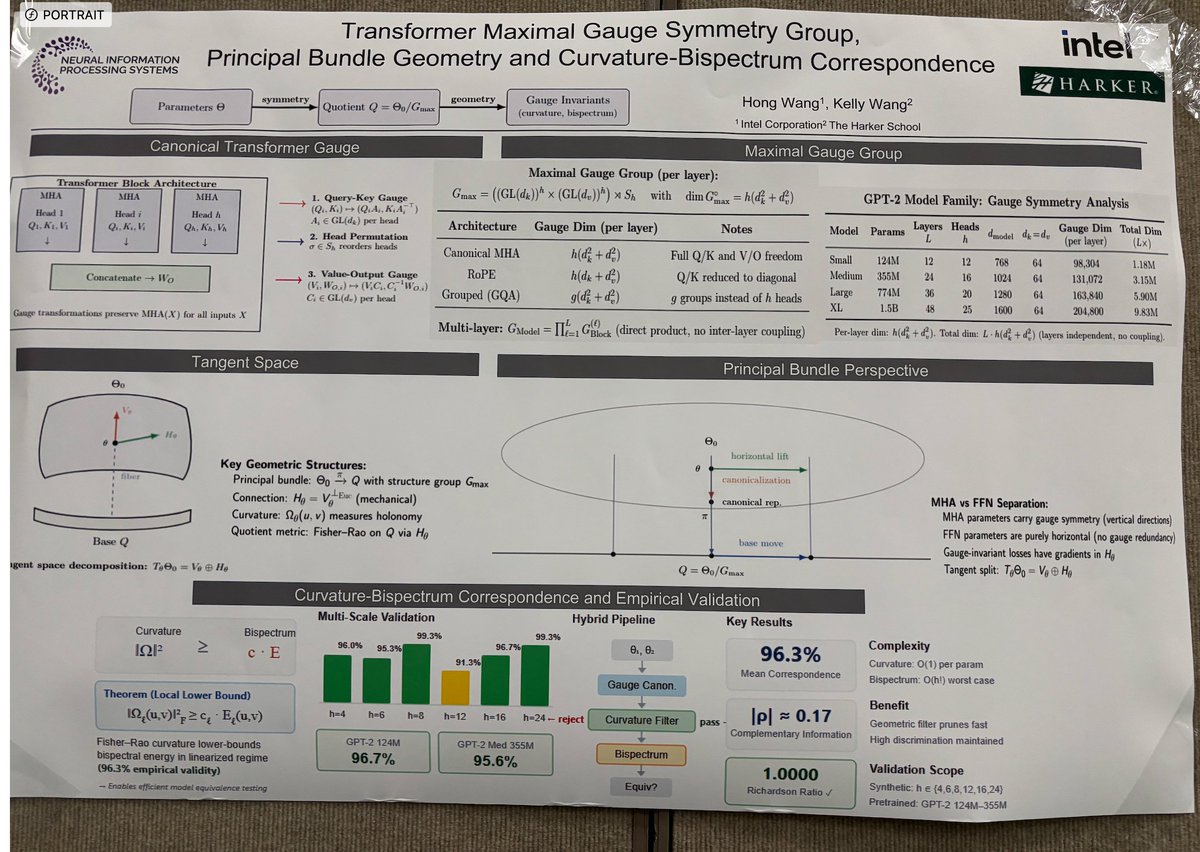
@alfcnz Sorry again for the inconvenience! Some problems with the printing service caused the right side of the poster becoming increasingly smearing although we provided a PDF…
The associated paper: https://t.co/fRh4MCqdba
I am an AC for ICLR 2026. One of the papers in my batch was just withdrawn. The authors wrote a brief response, explaining why the reviewers failed at their job. I agree with most of their comments. The authors gave up. They are fed up. Just like many of us. I understand. We pretend the emperor has clothes, but he is naked.
Here is the final part of their withdrawal notice. I took the liberty to make it public, to highlight that what we are doing with AI conference reviews these last few years is, basically, madness.
---
Comment: We thank the reviewers for their time.
However, upon reading the reviews for our paper, it became immediately apparent that the four "reject" ratings are not based on good-faith academic disagreement, but on a critical failure to read the submitted paper.
The reviews are rife with demonstrably false claims that are directly contradicted by the text. The core justifications for rejection rely on asserting that key components are "missing" when they are explicitly detailed in the manuscript. Some specific examples are (and many are even fake claims).
Claim: Harder tasks like GSM8K are missing.
Fact: GSM8K results are in many tables, like Table 2 (Section 4.2) and Appendix G.
Claim: The method does not use per-layer ranks.
Fact: This is the entire point of our method. The reviewer clearly mistook our method for the baselines. (Section 2, Table 1).
Claim: The GP kernel is not specified.
Fact: It is specified in Appendix E (Table 6).
Claim: There is no ablation of the method's three stages.
Fact: Section 4.4 ("Ablation Study") and Appendix J are dedicated to this.
Reviewers have a fundamental responsibility to read and evaluate the work they are assigned. The nature of these errors is so fundamental, so systemic in overlooking explicit content, that it goes far beyond what "limited time" or "oversight" can explain. This work has gone through several rounds of revision over the last year. In earlier submissions, the paper usually received borderline or weak-accept scores.
Numerous signs strongly suggest that some reviewers are relying entirely on AI tools to automatically generate peer reviews, rather than fulfilling their fundamental responsibility of personally reading and evaluating manuscripts.
We strongly protest this.
This is a gross disrespect to the authors. It is a flagrant desecration of the reviewer's sacred duty. It fundamentally undermines the integrity of the entire peer-review process.
Given that the reviews are not based on the actual content of our paper, we have decided to withdraw the submission.
We leave this comment so that future readers of the OpenReview page are aware that the items described as "missing" are already present in the submitted manuscript. These negative reviews for this submission are factually unsound and do not reflect the content of the paper. We cannot and will not accept an assessment that is not based on the work we actually submitted.