I sat on this story for weeks. Felt exploitative.
What changed: I don't want you saying "If I could turn back time, I'd force them to quit."
Check on anyone covering multiple roles.
Source: https://t.co/MVOO5NSZA7
We celebrate people who pick up everyone's slack. Then we bury them.
Gao Guanghui was 32. Programmer, just promoted to manager. Covering work of 6-7 people. 995.5 schedule: 9am-9pm Mon-Fri, half-day Saturday.
One Saturday he woke up feeling off.
This is the promotion trap: work hard, get promoted, drown under more responsibility with fewer resources. 53% of managers report burnout?higher than ICs.
At EvenUp, I caught myself coding in a hospital waiting room. That's when I knew something broke.
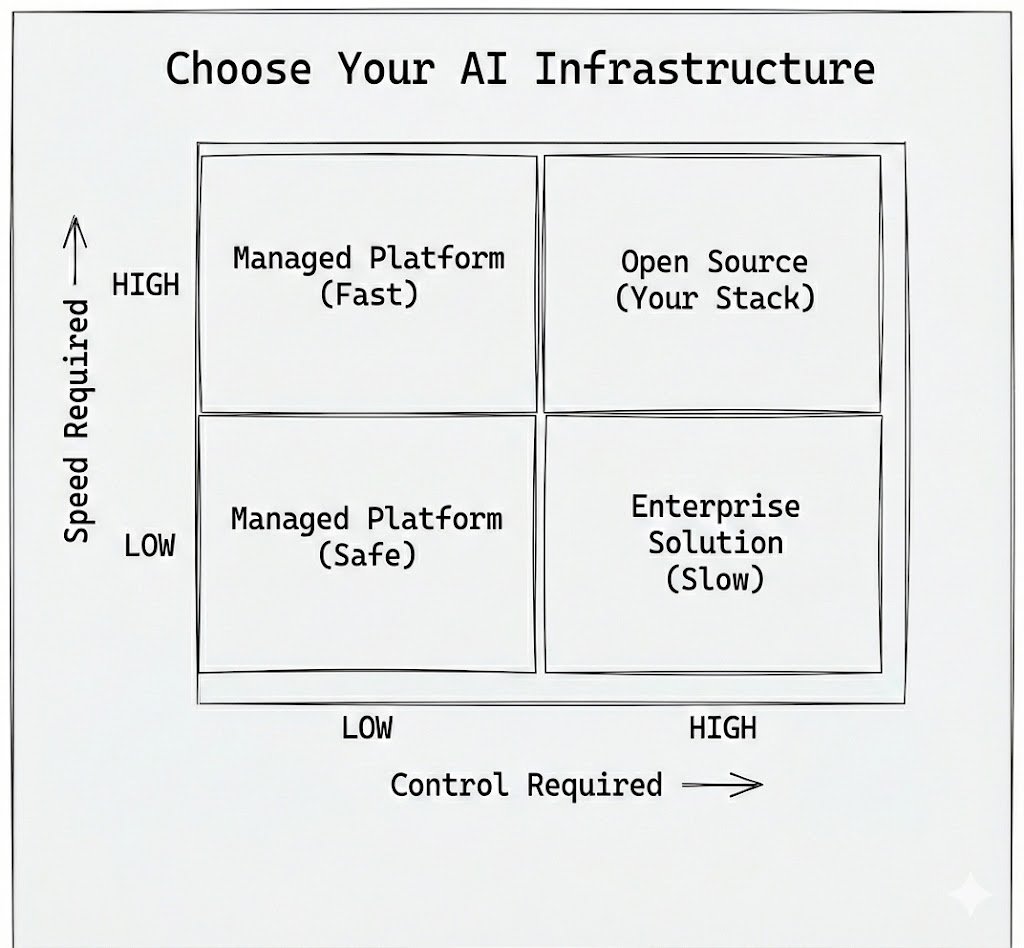
We run on boring open source:
- LangChain/LangGraph
- OpenSearch
- Langfuse
Nothing vendor-locked. Everything swappable. No sales calls. No contracts.
Open source wins because it's boring.
Would you trade speed for support, or are you chasing something else?
We spend $100k+/mo on AI infrastructure. OpenAI launched Frontier for enterprise. Not interested.
Their pitch: "Managed environment. Built-in governance."
Reality: When you find a better model, you're calling your account rep. Waiting for approval.
Speed dies in bureaucracy.
Last Tuesday: Our ML engineer drops in Slack "New Cohere model is 20% better on our queries."
Switched that afternoon.
Week before: OpenAI endpoint timed out at 11am. Error rate hit 40%.
Rerouted to Anthropic in 8 minutes.
LangChain + LangGraph = just update config and ship.
We spend hours debating GPU vendors and cloud lock-in.
Meanwhile, the actual bottleneck? Zero alternatives.
How deep do you trace your technical dependencies?
RT if this surprised you
Your AI stack has a 100% monopoly at its base. It's not NVIDIA.
I mapped our entire dependency chain and found ASML at the bottom?100% monopoly on EUV lithography. Every AI chip requires their machines.
One machine: $400M. Intel bought their entire 2024 production. 30-year moat, 5,000 suppliers, zero competitors.
Any challenger needs 20+ years to replicate the IP.
The first real evidence that the days of LLM Scaling laws are over.
Introducing SCOPE: the world's most efficient Neural Planner. 🔍📊
We tested SCOPE vs Frontier LLMs for planning tasks on TextCraft (text version of Minecraft) and here are the results: ⤵️
- SCOPE Runs 55x faster than GPT 3.5 (3 seconds vs 164 seconds)
- SCOPE is 160,000 smaller than GPT 4o (11M parameters vs 1.8T parameters)
- SCOPE is more accurate on Planning tasks (56%) than frontier LLM models
The age of efficient AI models starts now.
🔗📌 Read the full write up here: https://t.co/n3DDSqshRm
@The_AI_Investor Too fast and furious!
Hardware cycles are outrunning deployment. Most teams will still be optimizing Blackwell software by the time Rubin actually hits the racks.
@jenzhuscott Sensible though!
Cool demos raise capital and help with marketing but utility builds companies.
Hardware is cheap now, but reliability in unstructured work is still the real bottleneck.
@jaynitx This is the best filter for the big pivots, but a trap for daily shipping.
You can't treat every minor bug like a life-defining moment or you'll never move fast enough.
@newstart_2024 True! tenacity is the only moat that matters.
Incumbents have more capital, but they can't buy the will to keep going when the odds are zero.
@tokumin yep, when code is a commodity, the only moat is the data and user context. If a tool does not know me better than the next one, there is nothing stop me from switching.