The White House’s review of OpenAI’s latest model amounts to a government-run licensing system that threatens the American people’s First Amendment rights.
The federal government is now claiming authority to review each new AI model — on a “voluntary” basis — before it’s released, and even to decide who gets to use it. These decisions are being made behind closed doors. The potential for politically motivated censorship and retaliation is obvious.
The Trump administration’s latest action comes after the federal government already imposed export controls on Anthropic’s Fable 5 and Mythos 5 frontier models last week, citing vague national security concerns.
We’re quickly barreling toward a future where the few control an extraordinarily powerful expressive technology without democratic transparency and accountability. This power grab should concern all of us, no matter your opinion of AI.
Your local TV stations are at risk. Not from advertisers or ratings, but from Washington.
The FCC is singling out ABC-owned stations for early license reviews, raising serious First Amendment concerns about government pressure on broadcasters.
And now, we need your help.
I, like most Americans, think that the average family and young person deserves a better shot at a decent life. I also think that socialism doesn’t work in real life, that America is good and filled with good people, and that it’s okay to work with people who don’t agree with me.
@htmx_org Very much this… when you realize that the number of developers is growing exponentially and what that does to the aggregate experience of the industry it is depressing.
Four hours.
That's all the time it took for our GNC (Guidance, Navigation, and Control) team to calculate our T-0 liftoff time from the moment we received the Notice To Launch for VICTUS HAZE from @USSpaceForce@USSF_SSC. Incredible work by our engineers on this new company record!
Don’t choose a technology because of popularity, or because it’s going to be popular, to appeal to popularity as a logical fallacy.
Rather, make technical decisions on the basis of quality.
As an industry, we can do better at this. Not to follow popularity. But to lead quality.
If you’re wondering why I’m so worried about identity and age verification in the UK and EU, start here.
These governments already have a known disregard for free speech. We have no reason to trust them with new tools to identify who is saying what online.
The Space Force called, and we launched. From call up to lift-off in just 16 hours 42 minutes 🎯 Rocket Lab has made history - the fastest response time ever for a @USSF_SSC Tactically Responsive Space mission.
Writing deterministic physics be like ...
You need to keep your maths tight. There's no need to go full fixed floats or integers. We managed to quantize just impulses, since in HLSL atomic operations needs to be performed on ints.
The result is what you see on the movie. This enables us to do multiplayer simulation since all the players will see exactly the same thing.
It's a shame the Steam Machine has to launch at a time when components are so expensive. I hope they stick with it until hardware prices renormalize, because this is a device I want to see become mainstream.
You can just run experiments now. Constantly. I was curious if unnecessary Rust derives had any measurable build-time cost. So I had Codex build a tool to identify and remove them, then cut >1500 derives from uv, measured the before and after. All in the background.
new sidequest: wrote HNSW from scratch in @ziglang
SIFT-1M, ef_search=100:
- 0.984 recall@10
- ~20K QPS single-threaded on M4
- 52µs p50 / 71µs p99
the fun part wasn’t just “implement the paper” — it was turning graph search into a memory path (heaps, epochs, SIMD, SQ4 traversal + float rescore, hot/cold layout)
https://t.co/Rf6J3s0KXF
For years, I raised alarms about dangerous gain-of-function research being farmed out to foreign countries, and I was told it was a conspiracy theory. Now, declassified documents show that the U.S. funded over 120 biolabs across more than 30 countries. Some of this research was conducted overseas precisely because scientists knew it would face scrutiny on American soil.
I'm calling for a presidential commission of scientists to review all gain-of-function research going forward. We're going lab by lab and pathogen by pathogen until the American people know the full truth.
https://t.co/gtv6sZ7viR
I once had a meeting with several folks at the Department of Education during the Obama administration. I was talking about campus due process, and I made what I thought was a perfectly reasonable point: sexual assault allegations should require due process, but people found guilty of rape should go to jail.
The response?
“Nobody should go to jail.”
I pushed a little further, trying to figure out what the hell they were talking about. I clarified that I think too many people are punished for bullshit offenses, but that murderers and rapists should go to jail.
No response.
That is a luxury belief. It’s not noble. It’s extraordinarily selfish.
Yay for FILES! IMO this is really about ASCII more than file systems. Today's observations from computing history…
The original "binary" files—that is non-human readable, extensions of data structures—are rooted in constraints of limited storage up until the 1980s.
If you peruse Knuth volume 3 you will find a ton of wild algorithms that are hard to place—such as sorting with two tapes as shown below. That's because efficiently writing to permanent storage was an entirely different problem from efficiently reading (and rewriting or outputting) from it. The limits of RAM, disk/tape, and cache required data to be read/written basically when you had it. These algorithms were insanely complex and designed to avoid randomly accessing data.
Fast forward to the first word processors (and spreadsheets) and they were quite limited by RAM and disk space (and speed.) One of the cool innovations by Charles Simonyi at Xerox PARC was a memory/storage structure that essentially added a virtual memory subsystem tuned to the needs to maintaining runs of like-formatted text ("piece table".) This structure (and Charles) made its way into the original PC Word and then Mac and WinWord as the famous .DOC format.
This innovation enabled word processors of the day to "easily" work on files that could not fit in RAM, which was an obvious requirement. BTW, those who used the original 256K MacWrite quickly became familiar with what happened when exceeding the page limit (not pages per se but combination of formatting, text, and runs) and the sudden "eating" of your work late on Friday night. This led to a massive amount of engineering around seemingly trivial tasks such as how quickly could you page down in a document while reading the .DOC from disk and then rending on screen. A common "torture test" for a word processor was opening a large 100 page document and immediately CTL+END to see how quickly that could function, or CTL+HOME and then page down and seeing if display kept up with the scroll bars and the like.
Spreadsheets (XLS) were quite constrained to physical memory until DOS added "EMM" and later Windows virtual memory. The nature of recalc required the whole sheet to be resident. This limitation was frustrating for people using 1-2-3 as a spreadsheet. The original spreadsheets had *theoretical limits" of 256 columns (the origin of column "IV" in Excel) and 2048 rows—one single sheet, no tabs too. But if you had a lot of text like in a database you'd run out of memory long before that. Also the data structures were not particularly sparse until Microsoft spreadsheets came along. This was part of the reason the data structures were essentially the memory map of the spreadsheet.
These formats morphed into what some believed was an unfair competitive advantage for Word and Excel. Ironically (or more correctly free of malice), it was precisely because these were essentially in-memory representations of the applications that simply "converting" was not an option. Any conversion required a 1:1 mapping of not only the feature but the implementation of Word/Excel by the reader of files. That led to a sea of interchange formats such as RTF, BIFF (BIF) within XLS, and even for a while SGML.
The arrival of universal virtual memory as well as RAM that could hold the whole document led to an ability to simply read in the whole file and operate on it in memory. That in turn made it much less daunting to develop interchange formats based on ASCII and XML which could be used by default without sacrificing functionality. Still that led to challenges like where to store native images or embedded documents and so on, which only made these "files" more complex for people. In the end, this might have made it easier for machines but the hope of being human consumable was long lost.
BTW, everything above also applied to programs themselves. Prior to virtual memory the actual executable (for Word for example) was technically limited to available RAM (on a segmented 16 bit address space.) What I describe below was originally done for Fortran on IBM mainframes and the history of COMMON variables dates to this sort of memory/disk/code management.
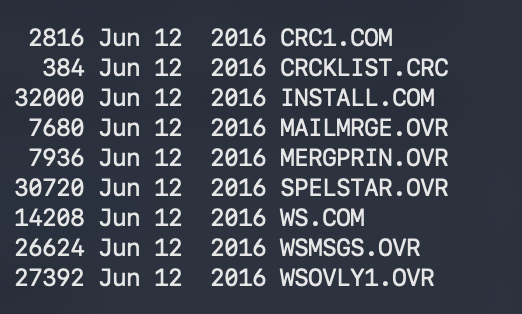
On 64K CP/M machines "overlays" became the tool used for most commercial software. An overlay is a *relocatable* chunk of code that could be read into memory as needed. So for example on WordStar on CP/M limited to 64K (but sold with as little as 16K) you can see https://t.co/q2J6DI9K0H under 16K and then assorted OVR or overlay files (OVL, OVR, or .00n files on disk). For example, when you invoked spell checking (no squiggles but a modal command) the overlay manager (code written by WordStar people) would read in SPELSTAR.OVR and load it with relocation into a part of RAM. After spelling it would get kicked out and maybe replaced with MAILMRGE for mail merge.) All of this was a manual effort in development and tons of work. The programmer had to basically keep track of what was where.
You could think of these overlays as a proprietary executable format not unlike .DOC, even if they were essentially yet-to-be-linked OBJ files.
As late as Office 4.x this process continued using proprietary tools and processes to work on the segmented 16bit architecture of Windows. This was viewed as a competitive advantage.
Even as late as Office 97 we had tools in development that would tune the code to provide better locality of code use so that we were not swapping out for basic tasks. A big reason for this was not only limited memory (there was something of virtual memory on 16 bit Windows) but the speed of using this swap file was low. As an example, using Word or Excel and invoking a rarely used command like mail merge or the complete Format Cell dialog you would often see a noticeable lag as that code was "paged" into memory. Picking the scenarios and sequences we swap tuned was a whole exercise for the team across development, testing, PM until we developed automated tools (a Microsoft Research project!)
So while it might be the age of files, particularly in ASCII, it is fun to look back and see why we did not have the age of files so much sooner. Of course Unix always had text files and virtual memory, but such was the luxury of expensive computing in commercial labs and academia :-)