this is how i wish i learned GPU fundamentals
not a lengthy textbook. not a static image. every concept is an interactive visualization.
covering the SM architecture, memory coalescing, synchronization, and more.
what concepts do you want to see next?
https://t.co/D7lq9xwXyk
I'm on vacation in Hong Kong and just shipped BrrrViz Chapter 11: Tiling from my hotel room. It's 6 interactive visuals that will help you grasp the concept. It's 1:43am. I'm tired. Hope it helps and go check it out :)
https://t.co/D7lq9xxvnS
Four interactive slides walk through the optimizations:
1. shared memory
2. warp packing
3. minimize bank conflicts
4. thread coarsening
Free at https://t.co/D7lq9xxvnS ⚡
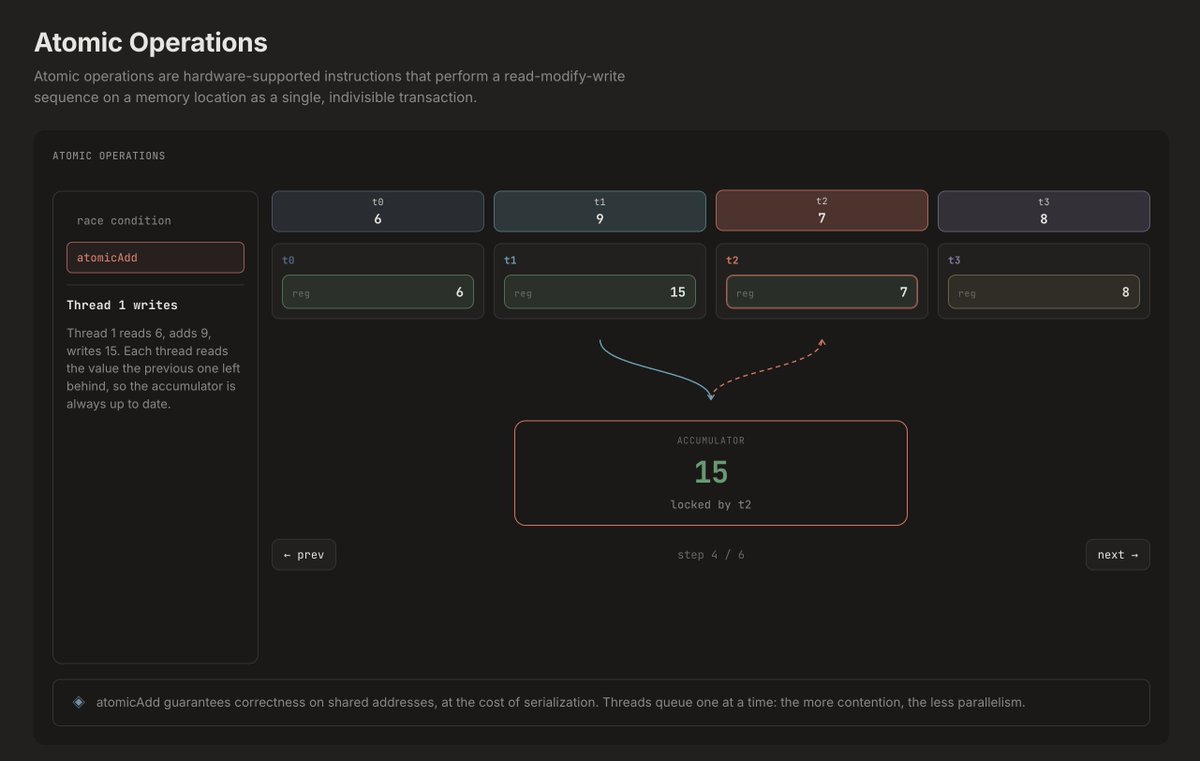
You launch a million threads and have them queue up to write to one address one at a time.
That's atomicAdd. It's correct. It's also a for-loop on a parallel computer.
Switch to a reduction tree and you fix the bottleneck, but introduce a new one: all but one thread is idle.
this is how i wish i learned GPU fundamentals
not a lengthy textbook. not a static image. every concept is an interactive visualization.
covering the SM architecture, memory coalescing, synchronization, and more.
what concepts do you want to see next?
https://t.co/D7lq9xwXyk
Most GPU bugs don't crash your program. They just give you the wrong answer. Silently.
When thousands of threads try to update the same memory address simultaneously, each one does three things:
📖 read the current value
⚡ execute their computation
✍ write back the result
The cost: serialization. Threads queue at the address one at a time. The more threads contend for the same location, the more your parallelism collapses into a bottleneck. This is why real GPU kernels accumulate locally in registers first, then do a single atomicAdd at the end.
Formez vous à l'inference/kernel engineering. Savoir bien optimiser les GPU kernels dans les workloads d'inference vaut de l'or. Maitriser CUDA ou Triton, vLLM, SGLang, TensorRT-LLM est un vrai plus si vous voulez vous démarquer pour 2026-2027 en que AI/ML Engineer.