pgGraph v0.1.4 is here. (Full Open Source, Rust)
For anyone new here: pgGraph is a PostgreSQL extension for bringing graph capabilities directly into Postgres.
With v0.1.4, we focused on making pgGraph easier to install, package, validate, and prepare for wider source-based distribution through PGXN.
This release keeps the existing v0.1.3 SQL contract intact and introduces no breaking changes.
What changed:
> Added PGXN META.json distribution metadata at the repository root, plus a PGXN-compatible top-level Makefile that delegates into cargo pgrx.
That means pgGraph is now better aligned with the standard PostgreSQL extension distribution flow.
> Expanded the installation documentation across all the docs including clearer guidance for source installs, PG_CONFIG targeting, and missing PostgreSQL header troubleshooting.
And yes, something much bigger is coming very soon.
We have been working on a massive update that pushes pgGraph far beyond “Postgres extension with graph traversal.”
I cannot say too much yet, but if you care about Postgres, graph workloads, AI agents, or making existing databases more intelligent, you will want to watch this repo.
pgGraph v0.1.4 is out now. Link to repo & docs below.
llama.cpp now has an official website: https://t.co/vztdUpdBWL
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
Today we’re launching Polygres🧊
An all-in-one database that brings Tabular, Graph, and Semantics into pure, native Postgres.
We took the most battle-tested, rock-solid elephant on earth and gave it a warp drive. By fusing Postgres, pgVector, and our own pgGraph into a single engine, we’re here to kill the multi-billion dollar "Modern Data Stack" scam.
Right now, developers are paying a massive SaaS tax just to keep a bloated AI stack afloat:
💸 You pay a vector DB hundreds a month just to store arrays of decimals.
💸 You pay a graph DB to draw lines between nodes. 💸 You pay a legacy DB to do what it’s done since 1996.
You aren't building a product anymore. You're a full-time data janitor running a distributed nightmare of brittle sync scripts. That's gotta end.
Imagine asking your app to do this:
"Find Pro-Plan users who are connected to John, and who recently asked the AI about scaling infrastructure."
To answer that reliably at scale today, you need a relational DB for the subscription, a graph DB for the network, and a vector DB for the semantic search. Plus brittle API pipelines, and days of engineering time. Today, it’s one native SQL query.
Drop your dead weight. We're launching soon. The first 100 signups get $50 in credits. Link to signup below.
Graph queries in Postgres 19 are the start of a journey, not a destination.
Postgres takes a pragmatic, incremental approach to adding functionality. For instance, way back in 2012, Postgres added its first JSON support. @craigkerstiens declared "we cheated" because it was just a text field with JSON validation layered on top of it. Two years later, JSONB was launched. New releases continue to add additional indexing capabilities and operators. Now, both JSON and JSONB have their place.
We expect Postgres 19's SQL/PGQ implementation to be similar. The initial release probably won't replace much workflow. It is limited to fixed-depth queries, which is already quite easy with current SQL implementations.
But, you have to start somewhere!
What is implemented?
DDL definition: a graph is declared and named. `CREATE PROPERTY GRAPH org_graph` declares which tables are vertices and edges, once. Queries can reference the graph by name. Schema changes propagate automatically, clear errors if a query references a vertex/edge that no longer exists, and no dropping tables with associated graphs.
Ever written a large CTE query that no fails due to a schema change? Yeah, me, either.
Query syntax: query syntax that follows SQL:2023 standards. For instance, `(a)<-[IS reports_to]-(b)` means b reports to a.
You get the standard composability of SQL because GRAPH_TABLE behaves as a table. So, join it, filter it, aggregate it, put it in a CTE, and think of GRAPH_TABLE as a new FROM clause source.
The question answered with this implementation is: "What is the least we can build that gets us started?" The answer appears to be DDL support and supported query syntax.
What SQL/PGQ can't do yet that recursive CTEs still do better:
Variable depth: if you need all descendants at any depth, SQL/PGQ in Postgres 19 is fixed-depth only. You must spell out each hop explicitly, which means you need to know the max depth at the time you write the query, which means the query can get lengthy.
Aggregation along the path: CTEs can build up arrays, concatenate paths, compute running totals as they recurse.
The future:
As with JSON support, just wait, and you'll look up after a few releases and say "oh, now it can do that too."
I have observed that AI founders at the very start of their journey don't yet realize the wall they are going to hit. They start building AI applications using traditional graph databases because it seems like the right tool for modeling complex relationships. But the founders who are already building at scale? They've told me exactly what happens.
I spoke with a team recently whose graph database bill had ballooned to almost $70,000 a month. When your infrastructure costs scale exponentially with agent reasoning, trying to earn that back from end-user subscriptions is almost impossible. The unit economics simply do not work.
That is what drove us to build pgGraph. We realized that for AI agents to actually be deployed at scale, the unit economics of graph infrastructure must fundamentally change.
You shouldn't have to choose between deep reasoning capabilities and sustainable infrastructure costs.
By rethinking the problem from the bare metal up, we're building the real-time graph engine that makes scalable agents economically viable.
Apache open source repo below
Hello again, everyone!
We've got another really fun 9b, this one specifically trained for tool calling and agentic coding workflows in @NousResearch Hermes agent.
Happy to report that it crushes, and as a 9b it runs on super affordable hardware. We also hit this one with some coding domain-specific training, and it scored a 53.33% on SWE bench on a slice of 200 samples!
To me, I was really shocked to see this high of a score on a 9B model in swe, correct me if I'm wrong, but I think that's nipping at the heels of the Gemma 4 series, much larger models on this particular benchmark, which is really incredible to see!
It also crushes the HermesAgent-20 benchmark, scoring an 85 vs the base model's 71!
Make sure to run it hot, --temp around 1, that seems to be the sweet spot for running these particular fine tunes in harnesses. If you have trouble, you can work your way down, but it does a much better job departing from base models, overthinking when you run it, high temp ~1.
Please spin it up in Hermes and let us know your thoughts! Looking forward to hearing your feedback as always!
Also, those of you waiting for Qwopus 3.6 27B, I have put together a preliminary evaluation for you in my HF repo, go check it out; we will be releasing the full model very soon! I will put the preliminary repo in the comments!
https://t.co/vP2s9iP6wL
Fleet has evolved into Air – our new Agentic Development Environment.
Air brings Fleet's simplicity and usability to working with coding agents.
Download free at https://t.co/8dy2vYNt0I ↓ and follow @getsome_air
Japanese HPC engineers, who collaborated for the development of the world's Top 1 Supercomputers from Japan, including “Earth Simulator” in 2002, “K” in 2011, gathered to celebrate Dr. Tadashi Watanabe, ex-NEC & RIKEN HPC Leader and the winner of Okawa Award in March 2026. #HPC
Today we're announcing the pgEdge AI DBA Workbench: an open source co-pilot for Postgres teams that are managing more databases, across more regions, with the same number of people they had two years ago.
It continuously monitors query performance, replication health, vacuum activity, connection counts, WAL throughput, and more across your entire Postgres estate. When something looks wrong, it doesn't just fire an alert and leave you to figure out the rest. Ellie, the built-in AI agent, investigates, walks you through the diagnosis step by step, and gives you the exact SQL to fix it. You decide whether to run it.
Built by the team behind pgAdmin, the most widely used open source Postgres management tool in the world.
Works with any Postgres 14+ instance, and fully open source under the PostgreSQL License. 🐘 Read the full announcement below.
🔗 https://t.co/62TofO16GX
#postgresql #postgres #dba #monitoring #ai #opensource #technews #data #programming #sql
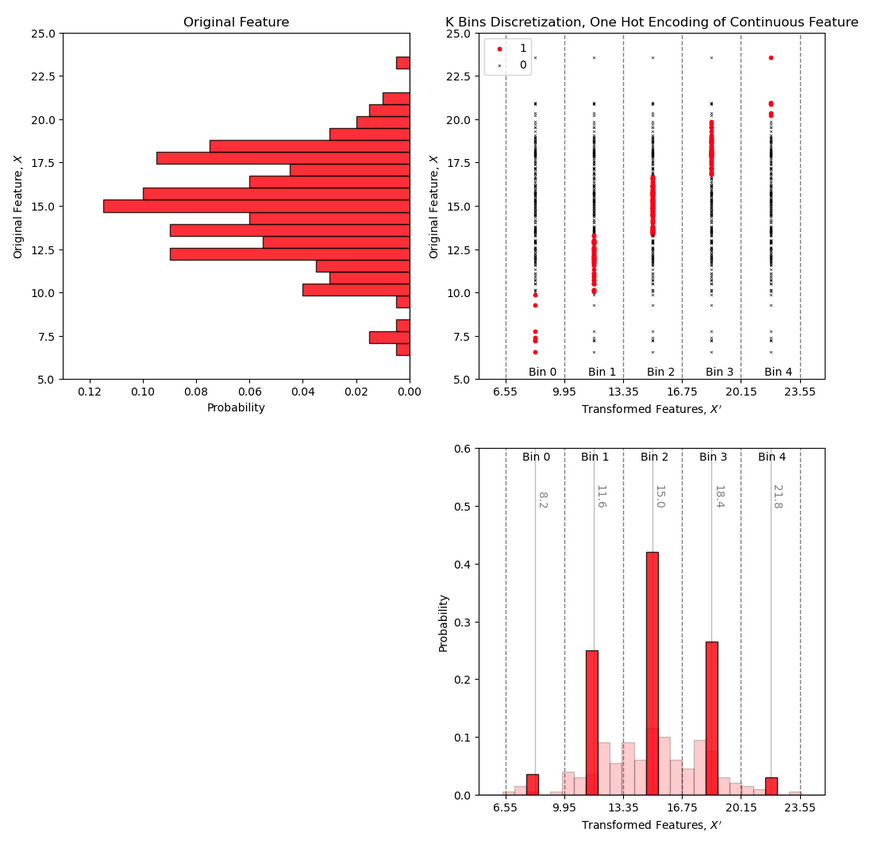
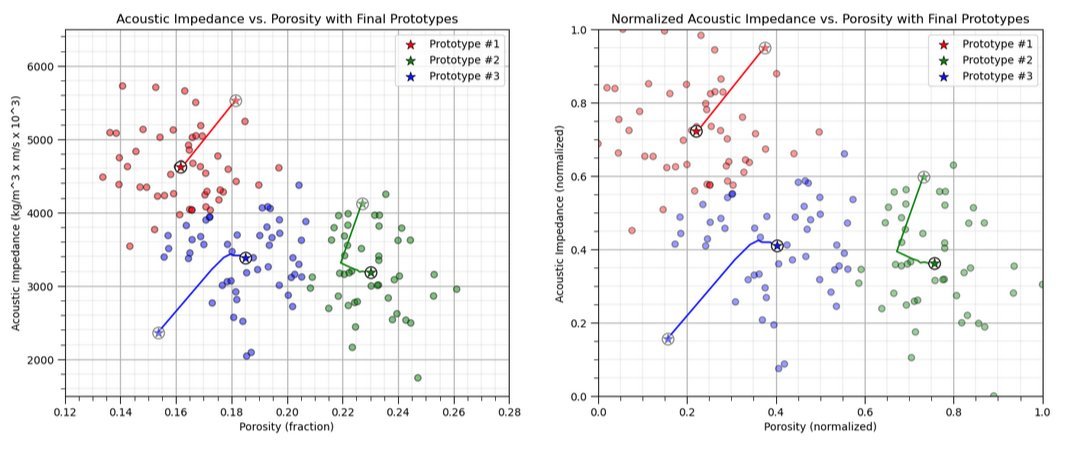
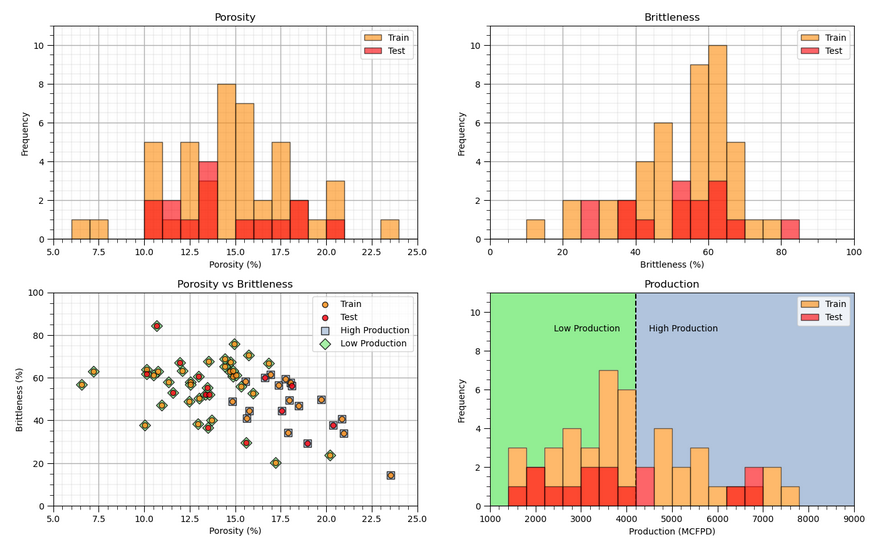
In my new free, online #DataScience e-books, I focus on creating effective and impactful visualizations.
The first step I take is always to ask: What message am I trying to communicate with this plot? From there, I design the plot specifically to make that message clear and intuitive. Rarely are my visuals the default, generic plots—each one is crafted to enhance understanding and engagement. See my ideas for model and #dataviz with,
Applied #MachineLearning in #Python: https://t.co/pq4eWwjPQQ
Applied #Geostatistics in Python: https://t.co/KFHZgbnbW0





![crunchydata's tweet photo. Graph queries in Postgres 19 are the start of a journey, not a destination.
Postgres takes a pragmatic, incremental approach to adding functionality. For instance, way back in 2012, Postgres added its first JSON support. @craigkerstiens declared "we cheated" because it was just a text field with JSON validation layered on top of it. Two years later, JSONB was launched. New releases continue to add additional indexing capabilities and operators. Now, both JSON and JSONB have their place.
We expect Postgres 19's SQL/PGQ implementation to be similar. The initial release probably won't replace much workflow. It is limited to fixed-depth queries, which is already quite easy with current SQL implementations.
But, you have to start somewhere!
What is implemented?
DDL definition: a graph is declared and named. `CREATE PROPERTY GRAPH org_graph` declares which tables are vertices and edges, once. Queries can reference the graph by name. Schema changes propagate automatically, clear errors if a query references a vertex/edge that no longer exists, and no dropping tables with associated graphs.
Ever written a large CTE query that no fails due to a schema change? Yeah, me, either.
Query syntax: query syntax that follows SQL:2023 standards. For instance, `(a)<-[IS reports_to]-(b)` means b reports to a.
You get the standard composability of SQL because GRAPH_TABLE behaves as a table. So, join it, filter it, aggregate it, put it in a CTE, and think of GRAPH_TABLE as a new FROM clause source.
The question answered with this implementation is: "What is the least we can build that gets us started?" The answer appears to be DDL support and supported query syntax.
What SQL/PGQ can't do yet that recursive CTEs still do better:
Variable depth: if you need all descendants at any depth, SQL/PGQ in Postgres 19 is fixed-depth only. You must spell out each hop explicitly, which means you need to know the max depth at the time you write the query, which means the query can get lengthy.
Aggregation along the path: CTEs can build up arrays, concatenate paths, compute running totals as they recurse.
The future:
As with JSON support, just wait, and you'll look up after a few releases and say "oh, now it can do that too."](https://pbs.twimg.com/media/HImu_eSXgAE-Lvo.jpg)
![crunchydata's tweet photo. Graph queries in Postgres 19 are the start of a journey, not a destination.
Postgres takes a pragmatic, incremental approach to adding functionality. For instance, way back in 2012, Postgres added its first JSON support. @craigkerstiens declared "we cheated" because it was just a text field with JSON validation layered on top of it. Two years later, JSONB was launched. New releases continue to add additional indexing capabilities and operators. Now, both JSON and JSONB have their place.
We expect Postgres 19's SQL/PGQ implementation to be similar. The initial release probably won't replace much workflow. It is limited to fixed-depth queries, which is already quite easy with current SQL implementations.
But, you have to start somewhere!
What is implemented?
DDL definition: a graph is declared and named. `CREATE PROPERTY GRAPH org_graph` declares which tables are vertices and edges, once. Queries can reference the graph by name. Schema changes propagate automatically, clear errors if a query references a vertex/edge that no longer exists, and no dropping tables with associated graphs.
Ever written a large CTE query that no fails due to a schema change? Yeah, me, either.
Query syntax: query syntax that follows SQL:2023 standards. For instance, `(a)<-[IS reports_to]-(b)` means b reports to a.
You get the standard composability of SQL because GRAPH_TABLE behaves as a table. So, join it, filter it, aggregate it, put it in a CTE, and think of GRAPH_TABLE as a new FROM clause source.
The question answered with this implementation is: "What is the least we can build that gets us started?" The answer appears to be DDL support and supported query syntax.
What SQL/PGQ can't do yet that recursive CTEs still do better:
Variable depth: if you need all descendants at any depth, SQL/PGQ in Postgres 19 is fixed-depth only. You must spell out each hop explicitly, which means you need to know the max depth at the time you write the query, which means the query can get lengthy.
Aggregation along the path: CTEs can build up arrays, concatenate paths, compute running totals as they recurse.
The future:
As with JSON support, just wait, and you'll look up after a few releases and say "oh, now it can do that too."](https://pbs.twimg.com/media/HImu8aFW8AA8Bga.jpg)





















![crunchydata's tweet photo. Graph queries in Postgres 19 are the start of a journey, not a destination.
Postgres takes a pragmatic, incremental approach to adding functionality. For instance, way back in 2012, Postgres added its first JSON support. @craigkerstiens declared "we cheated" because it was just a text field with JSON validation layered on top of it. Two years later, JSONB was launched. New releases continue to add additional indexing capabilities and operators. Now, both JSON and JSONB have their place.
We expect Postgres 19's SQL/PGQ implementation to be similar. The initial release probably won't replace much workflow. It is limited to fixed-depth queries, which is already quite easy with current SQL implementations.
But, you have to start somewhere!
What is implemented?
DDL definition: a graph is declared and named. `CREATE PROPERTY GRAPH org_graph` declares which tables are vertices and edges, once. Queries can reference the graph by name. Schema changes propagate automatically, clear errors if a query references a vertex/edge that no longer exists, and no dropping tables with associated graphs.
Ever written a large CTE query that no fails due to a schema change? Yeah, me, either.
Query syntax: query syntax that follows SQL:2023 standards. For instance, `(a)<-[IS reports_to]-(b)` means b reports to a.
You get the standard composability of SQL because GRAPH_TABLE behaves as a table. So, join it, filter it, aggregate it, put it in a CTE, and think of GRAPH_TABLE as a new FROM clause source.
The question answered with this implementation is: "What is the least we can build that gets us started?" The answer appears to be DDL support and supported query syntax.
What SQL/PGQ can't do yet that recursive CTEs still do better:
Variable depth: if you need all descendants at any depth, SQL/PGQ in Postgres 19 is fixed-depth only. You must spell out each hop explicitly, which means you need to know the max depth at the time you write the query, which means the query can get lengthy.
Aggregation along the path: CTEs can build up arrays, concatenate paths, compute running totals as they recurse.
The future:
As with JSON support, just wait, and you'll look up after a few releases and say "oh, now it can do that too."](https://pbs.twimg.com/media/HImvB72XIAEs2l2.jpg)