Rubin’s memory explosion = AI’s next physics limit.
One chip slurping 300GB HBM4 means $AMZN/ $MSFT clusters will burn through DRAM supply faster than $NVDA can fab it.
Rental pricing for Rubin‑equipped racks? Pure chaos until someone builds the hedging layer.
$NVDA #HBM #AIInfra
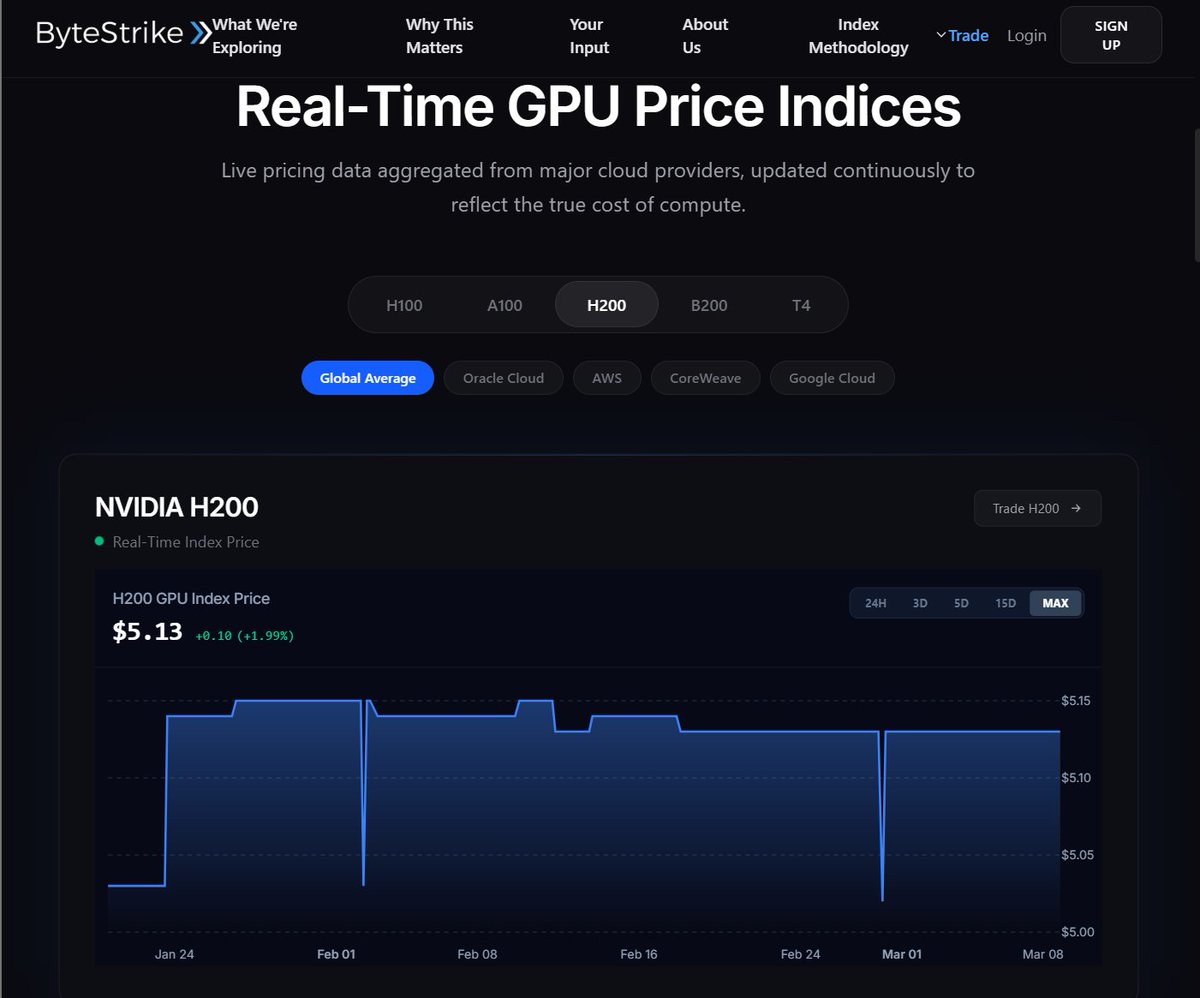
Nvidia’s Rubin R100 jumping to ~300GB HBM4 (from H100’s 80GB → H200 141GB → B200 192GB) isn’t just a spec bump.
It’s a memory wall demolition, each gen demanding DRAM equivalent to multiple high‑end PCs, sucking gigatons out of the supply chain and turning HBM into the new AI bottleneck.
Hyperscalers like $AMZN, $MSFT, $GOOGL, $META now face:
• HBM shortages spiking GPU rental costs 20–50%
• Rack redesigns for denser memory (higher power draw too)
• Pricing chaos as Rubin ramps in H2 2026
$NVDA isn’t just selling chips anymore. They’re selling the entire physics stack compute + memory + bandwidth and the economics are brutal if you’re renting capacity.
ByteStrike tracks this live:
• GPU Indices: H100/H200/B200/Rubin pricing across 70+ providers
• Hedging Tools: Regulated perps to lock costs before the next memory crunch hits
• Forward Markets: Price discovery for HBM‑constrained compute
When one Rubin GPU eats as much DRAM as 3–4 PCs, you don’t guess on pricing. You hedge it.
Financializing AI Compute.
https://t.co/pRArsz8lFl
$NVDA $AMZN $MSFT $GOOGL $META $TSM
#AI #Rubin #HBM #GPUs #MemoryWall #AIInfra #Derivatives #ByteStrike
$NVDA latest Rubin AI chip requires ~300GB of memory (up from 80GB on the H100) showing how each generation of AI hardware demands far more DRAM.
At hyperscaler scale, this is pulling massive amounts of DRAM out of market turning memory into a key bottleneck in the AI buildout.
Power is the substrate. Compute is the yield.
$IREN, $NBIS, $CRWV just stacked gigawatts of electrons. Genius.
But imagine signing 20yr PPAs only to watch H100/H200 rentals crater 20% on a single $NVDA drop.
Hedging compute risk isn’t optional anymore and it’s the moat for power landlords.
Power is the new GPU.
You can order $NVDA H100s or $AMD MI325s or $GOOGL TPUs all day long.
But gigawatts? Those are the real constraint, and the power landlords are stacking contracts:
• $IREN: ~4.5GW
• $CRWV: ~3.1GW
• $NBIS: ~2.0GW
• $WULF: 643MW
• $CIFR: 600MW
• $APLD: 600MW
• $CORZ: 590MW
• $HUT: 245MW
These aren’t just data centers. They’re AI power plants, liquid‑cooled, fiber‑dense, locked into 10–20yr PPAs that hyperscalers like $AMZN, $MSFT, $META, $GOOGL are desperate to backfill with GPUs.
The catch?
Power is fixed. But compute revenue isn’t.
$IREN and $NBIS have the electrons, but they’re exposed to:
• H100/H200/B200 rental volatility (14% swings on model drops)
• $NVDA/$AMD mix‑shifts from hyperscalers
Utilization gaps if training demand softens
• No power landlord wants a gigawatt of stranded capacity because GPU spot markets tanked overnight.
ByteStrike solves this.
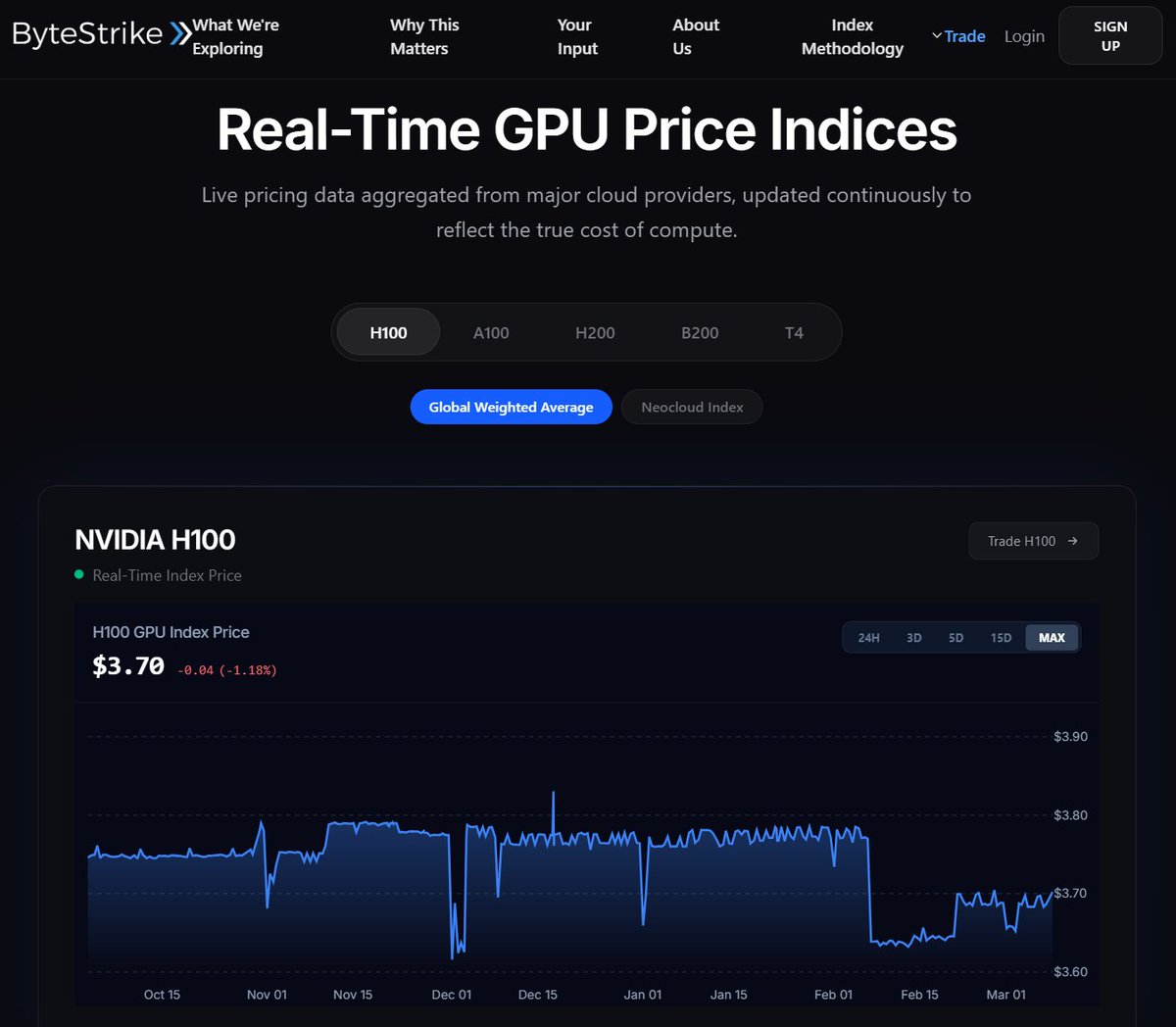
• Live GPU Indices: Track H100/H200/B200 pricing across 70+ providers in real time
• Regulated Perps: Hedge rental volatility w/o physical delivery
• Forward Curves: Lock compute economics before racks are live
Turn power contracts into hedged yield machines.
$IREN doesn’t just need more GPUs. They need predictable compute pricing to match those GW commitments.
Financializing AI Compute.
https://t.co/pRArsz8lFl
$IREN $CRWV $NBIS $WULF $CIFR $APLD $CORZ $HUT $NVDA $AMD $GOOGL $AMZN $MSFT $META
#AI #Power #DataCenters #GPUs #AIInfra #Derivatives #ByteStrike
These companies are locking in the physical substrate behind the next decade of AI compute and that substrate is power.
You can order GPUs from $NVDA or $AMD or TPUs from $GOOGL but you can’t just order gigawatts so now the question becomes who can actually deliver it.
Contracted power:
• $IREN ~4.5GW
• $CRWV ~3.1GW
• $NBIS ~2.0GW
• $WULF ~643MW
• $CIFR ~600MW
• $APLD ~600MW
• $CORZ ~590MW
• $HUT ~245MW
$GOOGL ’s data center buildout hitting $1T+ over 10 years (starting with $175–185B this year alone) is the real AI capex story, powered by TPUs, not just $NVDA GPUs.
Markets panicked on OpenAI/$ORCL Stargate delays and dumped semis.
But $GOOGL isn’t OpenAI. They’re printing cash while scaling TPU v8 racks at unprecedented levels, with $LITE, $AVGO, $TSM, SK Hynix, Samsung all positioned to feast.
The trillion‑dollar bet means hyperscalers like $GOOGL, $AMZN, $MSFT, $META are all‑in on multi‑year infra:
• TPU/Trainium/Maia ASIC ramps
• HBM memory shortages
• Power contracts + land grabs
• GPU/accelerator pricing that moves 10–20% on supply hiccups
That’s $600B+ in 2026 capex alone, with zero standardized hedging for the most volatile input: compute capacity.
ByteStrike is the financial infrastructure layer for exactly this:
• Live GPU Indices: H100/H200/B200/B100 pricing across 70+ providers (works for TPU equivalents too)
• Regulated Perps: Hedge rental volatility before it hits P&L
• Forward Markets: Lock costs for training/inference across chip generations
$GOOGL can print money to fund $1T builds. But even money‑printing machines need to hedge the $NVDA/ $TSM/ $AVGO pricing risk underneath.
Financializing AI Compute.
https://t.co/pRArsz8lFl
$GOOGL $NVDA $AMZN $MSFT $META $ORCL $LITE $AVGO $TSM
#AI #Capex #TPU #DataCenters #AIInfra #GPUs #Derivatives #ByteStrike
“Google’s Data Center Buildout Could Top 1 Trillion”
The implications for $1.5T+ in capex spend for the Google TPU ecosystem:
From $LITE, Mediatek, $AVGO, $TSM, SK Hynix, Samsung and others are widely positive.
In an interview with Forbes on AI capex spend, $GOOGL CTO stated:
“We’re at $175 to $185 billion this year, one could imagine, assuming it's not going to go down, that this could extend to some big number over 10 years”
Forbes comments: “There’s a big difference between Google’s data center ambitions and OpenAI’s: Google is a money-making machine”
Yesterday, markets sold off semi names from OpenAI + $ORCL putting a pause on some Stargate related projects.
The market conflated OpenAI's growing pains with the broader AI infrastructure buildout funded by the richest hyperscalers.
From $GOOGL and a money-printing Mag7 perspective:
The AI buildout only looks to accelerate over the next decade.
$NVDA, $AMD, $MSFT, $GOOGL, $META, $AMZN are all scaling AI like there’s no tomorrow.
But everyone is running into the same pain point:
• GPU prices swing 3–10x between cycles and providers
• New chips (H100 → H200 → B200 / MI300 → MI450) nuke your last ROI model
• Long-term DC leases and power contracts are locked… while compute pricing is not
Right now, most teams are:
• Sourcing GPUs via opaque quotes and one-off deals
• Committing to multi-year spend with zero way to hedge
• Explaining budget blowups after the fact instead of managing risk upfront
That’s the gap ByteStrike is built to solve.
What ByteStrike does:
• Turns GPU capacity into a transparent, benchmarked price: indices for major SKUs (e.g., H100, H200, B200, inference GPUs) across dozens of providers
• Builds regulated, cash-settled futures on those indices so infra buyers can lock in compute costs ahead of time
• Lets operators, funds, and lenders trade compute risk instead of just wearing it on their P&L
In practice, that means:
• A cloud team can fix part of next year’s GPU budget instead of praying spot doesn’t rip
• A lender financing an AI campus can hedge collateral exposure to GPU depreciation
• A fund can go long/short “AI infra” without needing to own a single server
The problem: AI runs on volatile, unhedged compute.
ByteStrike’s solution: financial rails that turn compute into a tradable digital commodity.
https://t.co/fyvGyjkWk4
If you’re scaling AI infra today, what’s the single biggest compute risk you wish you could hedge?
$ORCL + OpenAI kill Texas DC expansion (financing + shifting needs). $META eyes the site with $NVDA's $150M Crusoe deposit to lock Blackwell over $AMD.
AI infra musical chairs: Multi-chip ( $NVDA/ $AMZN Trainium/Groq) kills single-site bets.
ByteStrike hedges the chaos: Live GPU indices (72+ providers) + regulated perps for $MSFT, $GOOGL, $AMZN and $META.
Deals die mid-buildout, who wins the financing game?
https://t.co/1NwRzzDaHX
$ORCL and OpenAI just canceled plans to expand their flagship Texas AI data center. Talks stalled over financing and shifting needs.
Now $META is potentially leasing the site. $NVDA reportedly helping facilitate discussions + putting down a $150M deposit with Crusoe.
This is the AI infrastructure musical chairs nobody's talking about.
What Just Happened:
$ORCL + OpenAI: Planned massive Texas expansion Reality: Financing couldn't close + OpenAI's needs changed
Result: Deal dead, site available
$META: Steps in immediately
$NVDA: Facilitating + $150M deposit to Crusoe (the site operator)
Why This Matters:
OpenAI's "shifting needs" = they're running multi-chip infrastructure now:
• $NVDA GPUs for training
• $AMZN Trainium (potential $50B partnership)
• Groq LPUs for inference (via $NVDA platform)
• $MSFT Azure capacity
They don't need a single massive $ORCL site. They need distributed capacity across vendors.
The $META Opportunity:
$META needs capacity for:
• 6GW $AMD MI455X deployment
• Llama model training
• Reality Labs compute (AR/VR)
• Instagram/Facebook inference scaling
Texas site = cheap power, existing infrastructure, ready to deploy. $META swoops in.
The $NVDA Angle:
Why is $NVDA facilitating + putting down $150M?
Because: $NVDA wants $META to deploy Blackwell/Rubin GPUs, not just $AMD. Helping secure the site = keeping $META in the $NVDA ecosystem.
This is vendor financing at infrastructure scale.
The Financial Risk Layer:
$150M deposit on a site that:
• $ORCL + OpenAI couldn't close financing for
• Requires billions more to fully build out
• Depends on multi-year demand commitments
If $META changes strategy (like OpenAI just did), that $150M + site investment becomes stranded capital.
What ByteStrike Tracks:
Infrastructure deals falling apart mid-negotiation = sign of market volatility. We track GPU pricing at https://t.co/1NwRzzDaHX
Demand is real, but financing structures are fragile. Transparent pricing helps companies avoid overcommitting to infrastructure that might not pencil.
$ORCL couldn't close. $META stepped in. ByteStrike tracks what compute actually costs vs what deals promise.
$MSFT $GOOGL $AMZN
$MRVL just reported Q4 revenue of $2.22B (up 22% YoY). Data center sales hit $1.65B, 74% of total revenue.
CEO guidance: 40% data center revenue growth next year. $15B annual revenue by fiscal 2028.
Stock up 14.7% after-hours. The "Mini-Broadcom" thesis just got validated.
The Strategic Play:
Big Tech wants off the "$NVDA tax." $MRVL provides:
• Custom ASICs for hyperscalers
• Optical interconnect for rack-scale systems
• High-speed SerDes for AI clusters
Same strategy as $AVGO, but at 1/5th the market cap. Hence: "Mini-Broadcom."
Why This Matters:
Hyperscalers are diversifying away from $NVDA monopoly pricing:
• $META: 6GW with $AMD MI455X
• $GOOGL: TPUs for internal workloads
• $AMZN: Trainium custom silicon
• All of them: $MRVL interconnect to make it work
$MRVL doesn't compete with $NVDA on GPUs. They build the infrastructure that connects everything else.
The Numbers:
Data center revenue: $1.65B (Q4) → growing 40% next year Interconnect business: Growing >50% YoY (vs 30% prior guidance) Total revenue path: $8.2B (FY25) → $15B (FY28)
That's 83% growth in 3 years. All from AI data center buildout.
The Hidden Layer:
$MRVL's interconnect + custom ASICs enable multi-chip strategies. Without them, hyperscalers can't deploy:
• $AMD + $NVDA mixed clusters
• TPU + GPU hybrid workloads
• Custom silicon at rack scale
$MRVL is the glue that makes heterogeneous compute work.
What ByteStrike Tracks:
Multi-chip deployments create pricing complexity. We monitor $NVDA GPU pricing at https://t.co/1NwRzzDaHX
As $MRVL enables more vendor diversity, transparent pricing across hardware platforms becomes critical.
$MRVL builds the interconnect. ByteStrike tracks what runs on top.
$MSFT $GOOGL $META $AMZN
https://t.co/1NwRzzDaHX
$MRVL Q4 EARNINGS
• Revenue $2.22B vs Est. $2.21B
• EPS $0.80 vs Est. $0.79
• Net Income $685M vs Est. $681M
• Gross Margin: 59% vs. Est. 59%
Q1 Guidance
• Revenue $2.4B vs Est. $2.3B
• EPS $0.79 vs Est. $0.74
• Gross Margin: 59% vs. Est. 59%
$AMZN charging $99/month per provider for AI that automates scheduling, verification, documentation, and coding.
That's 90%+ cost reduction vs hiring staff. But here's the hidden layer:
Every patient interaction = continuous inference workload. Voice AI + medical coding + EHR integration = expensive compute.
Millions of interactions/month across thousands of providers = massive sustained inference demand running 24/7.
If inference costs spike, the $99 pricing model breaks.
ByteStrike tracks inference economics: https://t.co/1NwRzzDaHX
$AMZN builds the product. We track what it actually costs to run at healthcare scale.
$AMZN just launched Amazon Connect Health: an agentic AI platform automating healthcare scheduling, verification, documentation, and medical coding.
Early results: 30-60% lower call abandonment. 275% increased AI scribe adoption. 630 hours/week redirected from verification.
This is healthcare's $20B administrative cost problem getting solved by inference workloads.
The Product:
AI agents handling:
• Patient scheduling (no human needed)
• Insurance verification (automated EHR integration)
• Medical documentation (AI scribes during visits)
• Medical coding (automated billing)
• Chart summarization (clinical decision support)
Pricing: $99/provider/month for AI scribe (up to 600 encounters), $0.15 per patient verification.
Why This Matters:
Healthcare spends $20B+ annually on administrative overhead:
• Call centers for scheduling
• Staff for insurance verification
• Medical scribes for documentation
• Coders for billing
$AMZN just automated all of it. At $99/month per provider, that's 90%+ cost reduction vs hiring staff.
The Compute Layer:
Agentic AI = continuous inference workloads at massive scale.
One Medical, UC San Diego Health, Netsmart deploying this means:
• Millions of patient interactions/month
• Real-time EHR integration
• Voice-to-text transcription
• Medical coding generation
Every interaction burns compute. This isn't training once. This is inference running 24/7 across thousands of healthcare providers.
The Hidden Economics:
$AMZN charges $99/month. But their compute cost?
Voice AI + medical coding + EHR integration = expensive inference stack. $AMZN needs:
• Trainium chips for cost efficiency
• AWS infrastructure at scale
• Multi-year contracts to amortize hardware
If inference costs spike, the $99 pricing breaks.
What ByteStrike Tracks:
Healthcare AI creates sustained inference demand. We monitor GPU/accelerator pricing at https://t.co/1NwRzzDaHX
$AMZN builds the product. ByteStrike tracks what it costs to run at scale.
$MSFT $GOOGL $NVDA
https://t.co/1NwRzzDaHX
$AMZN launched Amazon Connect Health, an AI platform that automates scheduling, verification, documentation & coding while integrating with healthcare EHR systems.
The system can handle up to 80% of call tasks with early users reporting 30–60% lower call abandonment.
U.S. export controls already pushed China to build domestic alternatives (Huawei, Cambricon). DeepSeek V4 proved frontier AI works without $NVDA.
Now the U.S. wants government pre-approval for AI chip exports to allied countries?
If customers need 6-month approvals to buy $NVDA GPUs, they'll source:
• $GOOGL TPUs (no export hassle)
• Domestic alternatives
• Regional silicon
ByteStrike tracks geographic pricing fragmentation: https://t.co/1NwRzzDaHX
Export controls create parallel compute markets. Transparent pricing across $NVDA, TPU, and regional alternatives becomes critical.
The U.S. risks giving away semiconductor dominance through bureaucracy.
The U.S. is drafting rules requiring government approval before $NVDA and $AMD can ship AI chips globally.
This isn't national security. This is shooting yourself in the foot.
What's Happening:
New export controls would require:
• Government pre-approval for AI chip exports
• Country-by-country review process
• Restrictions beyond just China
$NVDA and $AMD would need permission to sell to customers in allied countries.
Why This Is Insane:
China already responded to U.S. export controls by:
• Building domestic alternatives (Huawei, Cambricon)
• Training DeepSeek V4 on non-NVIDIA chips
• Proving frontier AI doesn't require U.S. silicon
Now the U.S. wants to make it harder for NVDA/NVDA/ NVDA/AMD to sell to everyone else too?
The Strategic Failure:
U.S. semiconductor dominance came from:
• Best technology
• Fastest delivery
• Easiest to buy
New rules kill #3. If customers need 6-month government approvals to buy $NVDA GPUs, they'll source from:
• $GOOGL TPUs (manufactured domestically, no export hassle)
• Domestic alternatives in their own countries
• Chinese chips (if they can access them)
The Market Impact:
Export controls already forced geographic fragmentation:
• U.S. market: $NVDA dominance
• China market: Domestic alternatives
New rules extend fragmentation to allied countries. That creates:
• Parallel compute markets with different hardware
• Pricing divergence across regions
• Competitive advantage for non-U.S. silicon
What ByteStrike Tracks:
Geographic fragmentation = different pricing dynamics per region. We monitor U.S. GPU pricing at https://t.co/1NwRzzDaHX
If export controls push customers to alternatives, transparent pricing across $NVDA, TPU, and regional alternatives becomes critical.
The U.S. built semiconductor dominance. Export bureaucracy risks giving it away.
$MSFT $GOOGL $META
https://t.co/1NwRzzDaHX
The U.S. is drafting rules that would require government approval before AI chips from companies like $NVDA & $AMD can be shipped globally.
The US built the most dominant semiconductor ecosystem in history but now we're telling those companies they need government permission to sell globally.
I call BS because this is not how you win supercycles by making your own companies harder to buy from.
$IREN: Bitcoin miner → 150,000 GPU AI cloud provider in 18 months.
$3.7B annual revenue target = $24,667 per GPU per year.
At ~$40-50K per B300, that's 18-24 month payback with 50%+ margins once paid off.
The catch? $9.3B funding = debt backed by future GPU rental revenue. If B300 pricing crashes when Rubin launches or $MSFT renegotiates terms, lenders hold depreciating collateral with no hedging tools.
ByteStrike tracks real-time GPU pricing: https://t.co/1NwRzzDaHX
$IREN builds the fleet. We track what those assets are actually worth as hardware cycles compress.
$IREN just secured 50,000 $NVDA B300 GPUs to build a 150,000-unit AI fleet. Projected revenue: $3.7B annually once fully deployed.
This is a Bitcoin miner becoming one of the largest AI infrastructure providers globally in 18 months.
The Transformation:
• 2023: Bitcoin mining company
• 2024: Pivots to AI cloud services
• 2025: $9.7B deal with $MSFT
• 2026: 150,000 GPU fleet ($3.7B annual revenue target)
$IREN went from mining crypto to mining AI workloads. Same infrastructure (power + cooling), different revenue model.
The Scale:
• 150,000 GPUs across British Columbia + Texas
• 50,000 B300s (newest $NVDA Blackwell architecture)
• $9.3B in funding already secured
For context:
• OpenAI runs ~100K-150K GPUs across all providers
• $IREN will have similar capacity in-house
The Economics:
$3.7B annual revenue from 150,000 GPUs = $24,667 per GPU per year
At current B300 pricing (~$40K-50K per unit), that's:
• 18-24 month payback period
• 50%+ gross margins once hardware is paid off
• Pure rental revenue with minimal ongoing capex
This is the neocloud model: Buy GPUs, lease capacity, print revenue.
The Risk:
Stock up 11.5% on the news. Then down after-hours on $6B share dilution concerns.
$IREN needs capital to fund GPU procurement. Dilution is how they're getting it. But dilution means existing shareholders own less of the $3.7B revenue opportunity.
The Collateral Exposure:
$9.3B funding secured = debt backed by future GPU rental revenue. If:
B300 pricing crashes (B400/Rubin launches)
$MSFT renegotiates contract terms
Demand shifts to inference-specific chips (Groq LPUs)
Lenders hold collateral that's depreciating hardware in a volatile market.
ByteStrike tracks this: https://t.co/1NwRzzDaHX
$IREN builds the fleet. ByteStrike tracks what those GPUs are worth in real-time.
$MSFT $GOOG $META
https://t.co/1NwRzzDaHX
To meet growing demand for our vertically integrated offering, $IREN is expanding to 150,000 GPUs with the addition of 50,000 @NVIDIA B300 GPUs.
Time-to-compute is increasingly important in today’s AI Cloud market and this expansion positions $IREN among the largest AI infrastructure providers globally.
More details: https://t.co/RsGJH7t81l
$AVGO doing $8.4B in AI semiconductors (up 2x YoY) selling custom ASICs, networking chips, and interconnect silicon to all five hyperscalers + OpenAI.
Guidance: $100B+ revenue by 2027, almost entirely AI products.
This creates multi-vendor infrastructure complexity:
• Different hardware platforms
• Complex pricing across vendors
• Different depreciation curves
ByteStrike tracks this: https://t.co/1NwRzzDaHX
$NVDA gets headlines. $AVGO builds the infrastructure layer. We track what it costs to run on top of both
$AVGO just reported $19.3B Q1 revenue, up 29% YoY. AI semiconductors hit $8.4B, more than double last year.
Guidance: $22B next quarter. Revenue "well over $100B by 2027, almost all from AI products."
This is the picks-and-shovels layer nobody's watching.
The Numbers:
Semiconductor solutions: $12.5B (up 52%) AI chips: $8.4B (more than doubled YoY) 2027E revenue: $100B+ (almost entirely AI)
$AVGO isn't selling GPUs. They're selling the infrastructure that makes GPUs work:
• Custom ASICs for hyperscalers
• Networking chips for AI clusters
• Interconnect silicon for rack-scale systems
The Customer List:
CEO Hock Tan highlighted "ramps at five hyperscalers plus OpenAI."
Translation:
• $MSFT: Custom silicon for Azure AI
• $GOOGL: Networking for TPU clusters
• $META: ASICs for 6GW AMD deployment
• $AMZN: Trainium interconnect
• Likely $ORCL or another hyperscaler
$AVGO sells to everyone. $NVDA dominates GPUs, but $AVGO dominates everything around them.
Why This Matters:
$100B revenue by 2027 = $AVGO becomes one of the largest semiconductor companies on earth.
All from AI infrastructure. Not consumer chips. Not telecom. Pure data center silicon.
The Financial Layer:
$AVGO growing 50%+ YoY means hyperscalers are deploying custom silicon at unprecedented scale. That creates:
Diverse hardware platforms (not just $NVDA)
Complex pricing across vendors
Different depreciation curves per platform
Multi-vendor infrastructure = pricing complexity.
ByteStrike tracks this: https://t.co/1NwRzzDaHX
$NVDA gets headlines. $AVGO builds the infrastructure layer. ByteStrike tracks what it costs to use.
$AVGO says it has line of sight to 2027 revenue “significantly above $100B” driven largely by AI silicon like accelerators, switch chips & DSPs.
Custom AI accelerator demand continues to ramp with $GOOGL TPUs strong, Anthropic scaling from ~1GW in 2026 to 3GW+ in 2027, $META targeting multi-GW deployments & OpenAI expected to deploy its first XPU at 1+GW in 2027.
$NBIS just got the green light to build a 1.2GW “AI factory” on ~400 acres in Independence, Missouri 1,200 construction jobs, 130 permanent roles, and $650M+ in PILOT taxes over 20 years.
At that scale, you’re not building a “data center.” You’re building an AI power plant:
• Gigawatt‑class tie‑in to the grid
• Multi‑building campus that will host hundreds of thousands of GPUs over time
• Long‑dated tax, power, and capex commitments that outlive any single chip generation
Here’s the catch: even the best‑positioned “AI power landlords” are still naked long compute.
Power + land are locked in, but $NBIS is exposed to:
• $NVDA H100/H200/B200 rental swings
• Hardware export rules and supply shocks
• Next‑gen GPU launches that reset spot pricing overnight
That’s exactly the gap ByteStrike is built to close.
We’re financializing AI compute so 1GW+ campuses can:
Hedge H100/H200/B200 price volatility with regulated GPU‑linked derivatives
Lock in forward compute costs before the racks are fully populated
Offer $NBIS, $AMZN, $MSFT, $GOOGL, $META, $AAPL predictable AI unit economics instead of riding spot markets
Gigawatt‑scale AI factories are the new refineries.
They shouldn’t have to wear unhedged GPU risk on their balance sheets.
Financializing AI Compute.
https://t.co/fyvGyjkWk4
#AI #DataCenters #GPUs #AIInfrastructure #Power #DigitalCommodities #ComputeMarkets #ByteStrike
$NBIS secured approval from Independence, Missouri to build its first U.S. gigawatt-scale AI factory with up to 1.2GW of capacity.
The ~400-acre campus is expected to create 1,200 construction jobs, 130 permanent roles and generate $650M+ in local tax payments over 20 years.
$AMZN bought a university campus in Ashburn for $427M. Not for education, for data centers.
Ashburn = "Data Center Alley," where 70% of global internet traffic flows. This is Tier 1 compute geography.
Land: $427M Full buildout: $3B+ (construction, power, cooling, networking)
Geographic pricing matters. Ashburn capacity commands premium vs Missouri/Louisiana because of location advantage.
ByteStrike tracks GPU pricing across regions: https://t.co/1NwRzzDaHX
Same hardware, different geography, different economics. Transparent regional pricing becomes critical.