OpenJarvis: a local-first personal AI is now available to run with Ollama
Built by Stanford’s @HazyResearch and Scaling Intelligence labs, as part of their “Intelligence Per Watt” research into efficient local AI. @Stanford
Learn more in the blog post 👇👇👇
📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era.
A versatile foundation for agents that actually get things done:
🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it.
🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration.
⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding.
🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere.
API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio.
Go build something wild!🏃🏃♂️
📖 Blog: https://t.co/y3AupX3Pa0
✅ Qwen Studio: https://t.co/qpTnrCBjWt
⚡️ API:https://t.co/0sys00osKn
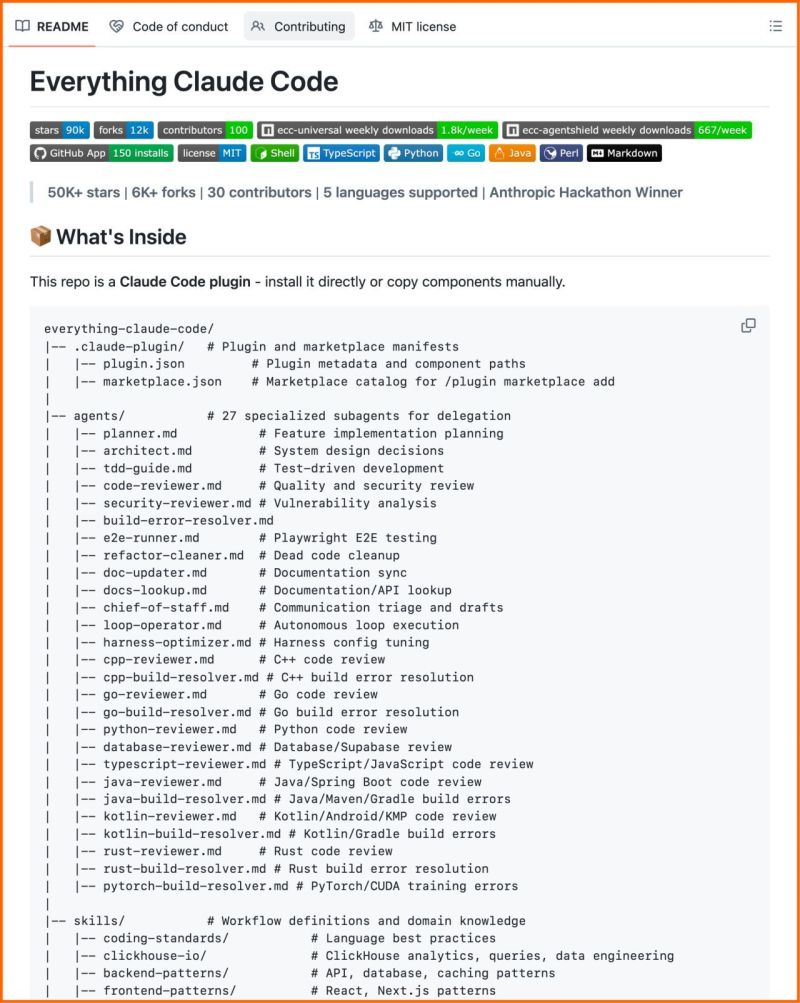
This is the most complete Claude Code setup that exists right now.
27 agents. 64 skills. 33 commands. All open source.
The Anthropic hackathon winner open-sourced his entire system, refined over 10 months of building real products.
What's inside:
→ 27 agents (plan, review, fix builds, security audits)
→ 64 skills (TDD, token optimization, memory persistence)
→ 33 commands (/plan, /tdd, /security-scan, /refactor-clean)
→ AgentShield: 1,282 security tests, 98% coverage
60% documented cost reduction.
Works on Claude Code, Cursor, OpenCode, Codex CLI. 100% open source.
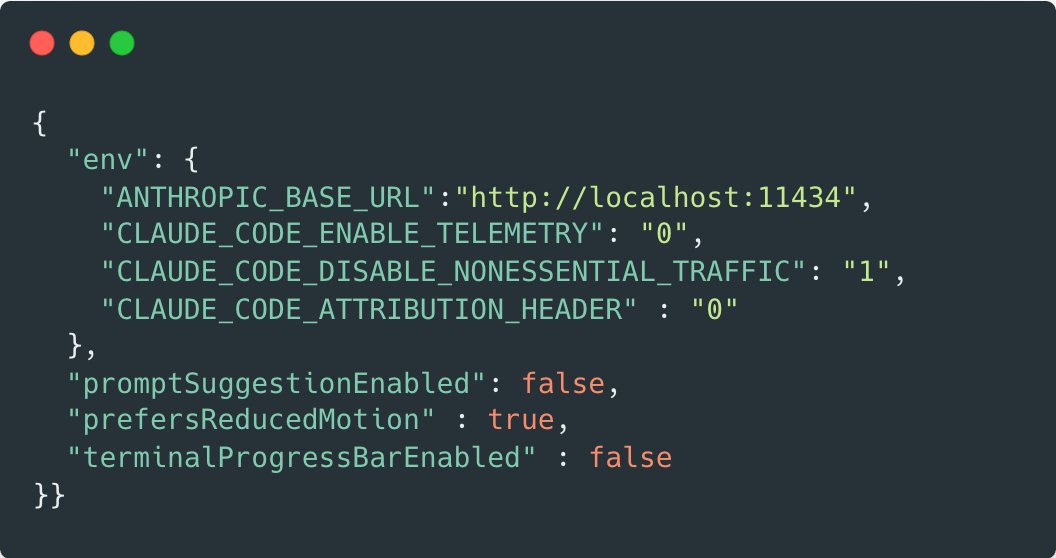
AI Pro Tip 🧠💡
Using Claude Code with local models (e.g. Ollama)?
Set CLAUDE_CODE_ATTRIBUTION_HEADER=0.
It disables the x-anthropic-billing-header, preventing full prompt processing on every request.
Result: 3×+ faster local inference 🚀
Any other tips except those below?
DeepSeek releases DeepSeek-OCR 2. 🐋
The new 3B model achieves SOTA visual, document and OCR understanding.
DeepEncoder V2 is introduced which enables the model scan images in same logical order as humans, boosting OCR accuracy.
Instead of traditional vision LLMs which read an image in a fixed grid (top-left → bottom-right), DeepEncoder V2 first builds a global understanding, then learns a human-like reading order - what to attend to first, next, and so on.
This improves OCR on complex layouts helping it follow columns, link labels to values, read tables coherently, and handle mixed text + structure more reliably.
DeepSeek-OCR 2 outperforms Gemini 3 Pro on benchmarks and is >4% improvement over the previous DeepSeek-OCR.
You can now run and fine-tune DeepSeek-OCR 2 with Unsloth and our guide.
Guide: https://t.co/z5Hu7J7KkW
Model: https://t.co/OuVLY7SvhP
MiniMax M2.1 is really good for writing code.
It's open source, and you can connect Visual Studio Code to it and start coding right away.
The model is especially good for those who don't use Python as a primary language. It's currently the best multilingual model out there.
The model hits 72.5% on SWE-Multilingual and 88.6% on VIBE-Bench (best!)
This means the model is also really good at performing real engineering work and does very well at agentic tasks:
• Long tool chains
• Structured agent scaffolding
• Following repo-level rules and slash commands
• Working inside existing agent frameworks without falling apart
And obviously, it's faster, cheaper, and more concise than M2, which was already really good.
I recorded a video to show you how to run @MiniMax_AI's 2.1 using Visual Studio Code.
Meta just solved the biggest problem in RAG!
Most RAG systems waste your money. They retrieve 100 chunks when you only need 10. They force the LLM to process thousands of irrelevant tokens. You pay for compute you don't need.
Meta AI just solved this.
They built REFRAG, a new RAG approach that compresses and filters context before it hits the LLM. The results are insane:
- 30.85x faster time-to-first-token
- 16x larger context windows
- 2-4x fewer tokens processed
- Outperforms LLaMA on 16 RAG benchmarks
Here's what makes REFRAG different:
Traditional RAG dumps everything into the LLM. Every chunk. Every token. Even the irrelevant stuff.
REFRAG works at the embedding level instead:
↳ It compresses each chunk into a single embedding
↳ An RL-trained policy scores each chunk for relevance
↳ Only the best chunks get expanded and sent to the LLM
↳ The rest stay compressed or get filtered out entirely
The LLM only processes what matters.
The workflow is straightforward:
1. Encode your docs and store them in a vector database
2. When a query arrives, retrieve relevant chunks as usual
3. The RL policy evaluates compressed embeddings and picks the best ones
4. Selected chunks are expanded into full token embeddings
5. Rejected chunks stay as single compressed vectors
6. Everything goes to the LLM together
This means you can process 16x more context at 30x the speed with zero accuracy loss.
I have shared link to the paper in the next tweet!
In Charlie Kirk's own words, he thinks his death was worth it. If God almighty gave Kirk a choice to stand by his thoughtless and indifferent words, or retract them and once again be able to hold his wife and children in his arms, whaddya think he'd say?
🚨 BREAKING: Multiple videos have surfaced showing what appears to be an individual running and ducking on the roof of a University building moments after Charlie Kirk was shot
Officials said Charlie was shot from around 200 yards.
The shooter is still at large, and it’s unknown if these videos shows them.