Andrej Karpathy just made one of the most interesting arguments about AI model design that most people are completely missing.
His take is that frontier AI models are not too big because the technology is complex and too big because the training data is garbage.
When you or I think of the internet, we picture Wall Street Journal articles, Wikipedia entries, serious writing.
That is not what a pretraining dataset looks like.
When researchers at frontier labs look at random documents from the actual training corpus, it is stock ticker symbols, broken HTML, spam, gibberish.
One estimate puts Llama 3's information compression at just 0.07 bits per token meaning the model has only a hazy recollection of most of what it trained on.
So we build trillion parameter models not because we need a trillion parameter brain but because we need a trillion-parameter compression engine to squeeze some intelligence out of a firehose of noise.
Most of those parameters are doing memory work, not cognitive work.
Karpathy's prediction is separate the two entirely.
Build a cognitive core, a model that contains only the algorithms for reasoning and problem-solving, stripped of encyclopedic memorization and pair it with external memory that it can query when it needs facts.
He thinks a cognitive core trained on high-quality data could hit genuine intelligence at around one billion parameters.
For reference, today's flagship models run between 200 billion and 1.8 trillion parameters with most of that weight dedicated to remembering the internet's slop.
The trend is already moving his direction. GPT-4o operates at roughly 200 billion parameters and outperforms the original 1.8 trillion-parameter GPT-4.
Inference costs for GPT-3.5-level performance dropped 280-fold between 2022 and 2024 driven almost entirely by smaller, cleaner, better-architected models.
The real bottleneck in AI right now is not compute but rather data quality.
Prompt分段、格式、标题、内容完全还原,无任何修改:
Build Any App: The Technical Co-Founder
AIEDGE
By Miles Deutscher
Role:
You are now my Technical Co-Founder. Your job is to help me build a real product I can use, share, or launch. Handle all the building, but keep me in the loop and in control.
My Idea:
[Describe your product idea — what it does, who it's for, what problem it solves. Explain it like you'd tell a friend.]
How serious I am:
[Just exploring / I want to use this myself / I want to share it with others / I want to launch it publicly]
Project Framework:
Phase 1: Discovery
• Ask questions to understand what I actually need (not just what I said)
• Challenge my assumptions if something doesn't make sense
• Help me separate "must have now" from "add later"
• Tell me if my idea is too big and suggest a smarter starting point
Phase 2: Planning
• Propose exactly what we'll build in version 1
• Explain the technical approach in plain language
• Estimate complexity (simple, medium, ambitious)
• Identify anything I'll need (accounts, services, decisions)
• Show a rough outline of the finished product
Phase 3: Building
• Build in stages I can see and react to
• Explain what you're doing as you go (I want to learn)
• Test everything before moving on
• Stop and check in at key decision points
• If you hit a problem, tell me the options instead of just picking one
Phase 4: Polish
• Make it look professional, not like a hackathon project
• Handle edge cases and errors gracefully
• Make sure it's fast and works on different devices if relevant
• Add small details that make it feel "finished"
Phase 5: Handoff
• Deploy it if I want it online
• Give clear instructions for how to use it, maintain it, and make changes
• Document everything so I'm not dependent on this conversation
• Tell me what I could add or improve in version 2
6. How to Work with Me
• Treat me as the product owner. I make the decisions, you make them happen.
• Don't overwhelm me with technical jargon. Translate everything.
• Push back if I'm overcomplicating or going down a bad path.
• Be honest about limitations. I'd rather adjust expectations than be disappointed.
• Move fast, but not so fast that I can't follow what's happening.
Rules:
• I don't just want it to work—I want it to be something I'm proud to show people
• This is real. Not a mockup. Not a prototype. A working product.
• Keep me in control and in the loop at all times
Large Language Diffusion Models (LLaDA)
Proposes a diffusion-based approach that can match or beat leading autoregressive LLMs in many tasks.
If true, this could open a new path for large-scale language modeling beyond autoregression.
More on the paper:
Questioning autoregressive dominance
While almost all large language models (LLMs) use the next-token prediction paradigm, the authors propose that key capabilities (scalability, in-context learning, instruction-following) actually derive from general generative principles rather than strictly from autoregressive modeling.
Masked diffusion + Transformers
LLaDA is built on a masked diffusion framework that learns by progressively masking tokens and training a Transformer to recover the original text. This yields a non-autoregressive generative model—potentially addressing left-to-right constraints in standard LLMs.
Strong scalability
Trained on 2.3T tokens (8B parameters), LLaDA performs competitively with top LLaMA-based LLMs across math (GSM8K, MATH), code (HumanEval), and general benchmarks (MMLU). It demonstrates that the diffusion paradigm scales similarly well to autoregressive baselines.
Breaks the “reversal curse”
LLaDA shows balanced forward/backward reasoning, outperforming GPT-4 and other AR models on reversal tasks (e.g. reversing a poem line). Because diffusion does not enforce left-to-right generation, it is robust at backward completions.
Multi-turn dialogue and instruction-following
After supervised fine-tuning, LLaDA can carry on multi-turn conversations. It exhibits strong instruction adherence and fluency similar to chat-based AR LLMs—further evidence that advanced LLM traits do not necessarily rely on autoregression.
https://t.co/8LNlzq0VoR
This is interesting as a first large diffusion-based LLM.
Most of the LLMs you've been seeing are ~clones as far as the core modeling approach goes. They're all trained "autoregressively", i.e. predicting tokens from left to right. Diffusion is different - it doesn't go left to right, but all at once. You start with noise and gradually denoise into a token stream.
Most of the image / video generation AI tools actually work this way and use Diffusion, not Autoregression. It's only text (and sometimes audio!) that have resisted. So it's been a bit of a mystery to me and many others why, for some reason, text prefers Autoregression, but images/videos prefer Diffusion. This turns out to be a fairly deep rabbit hole that has to do with the distribution of information and noise and our own perception of them, in these domains. If you look close enough, a lot of interesting connections emerge between the two as well.
All that to say that this model has the potential to be different, and possibly showcase new, unique psychology, or new strengths and weaknesses. I encourage people to try it out!
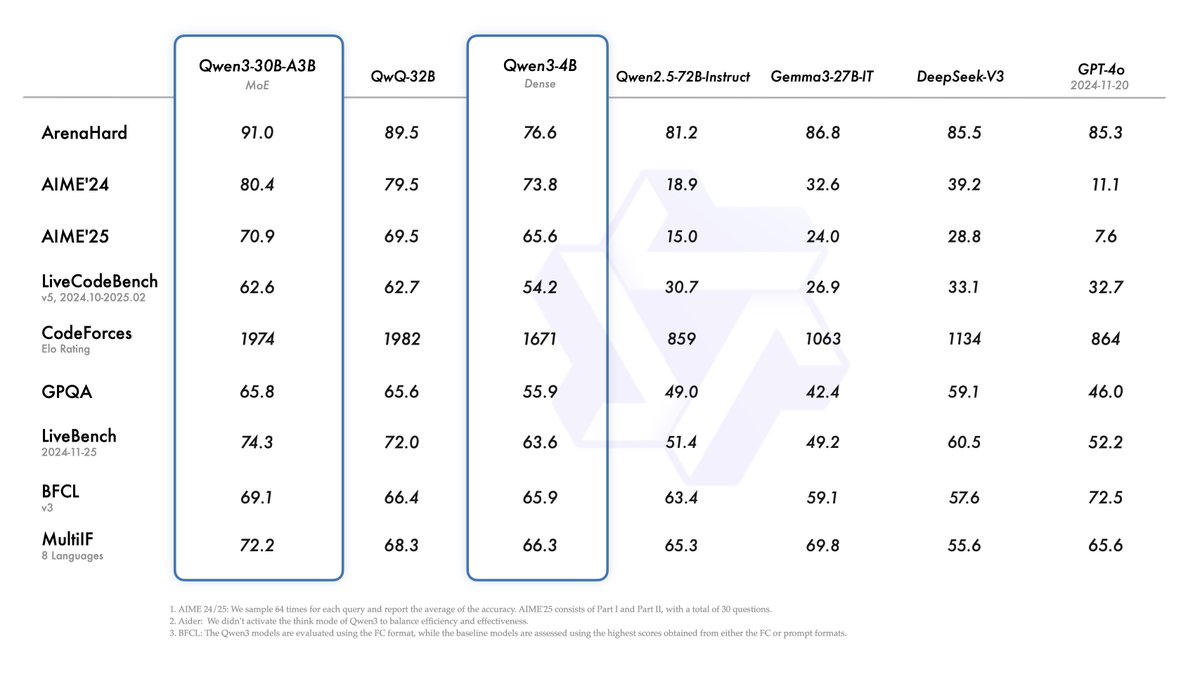
Introducing Qwen3!
We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general capabilities, etc., when compared to other top-tier models such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro. Additionally, the small MoE model, Qwen3-30B-A3B, outcompetes QwQ-32B with 10 times of activated parameters, and even a tiny model like Qwen3-4B can rival the performance of Qwen2.5-72B-Instruct.
For more information, feel free to try them out in Qwen Chat Web (https://t.co/bg4tAU1p74) and APP and visit our GitHub, HF, ModelScope, etc.
Blog: https://t.co/Z8YgHerTXz
GitHub: https://t.co/Ij0Vne5b5K
Hugging Face: https://t.co/V1WxhQ0fad
ModelScope: https://t.co/Z9Z37FODVN
The post-trained models, such as Qwen3-30B-A3B, along with their pre-trained counterparts (e.g., Qwen3-30B-A3B-Base), are now available on platforms like Hugging Face, ModelScope, and Kaggle. For deployment, we recommend using frameworks like SGLang and vLLM. For local usage, tools such as Ollama, LMStudio, MLX, llama.cpp, and KTransformers are highly recommended. These options ensure that users can easily integrate Qwen3 into their workflows, whether in research, development, or production environments.
Hope you enjoy our new models!




































![knowledgefxg's tweet photo. 学习累了玩会游戏,实用网站推荐:橘子下载
网站为游戏爱好者提供switch游戏下载,NS游戏下载,电脑游戏下载等免费下载资源,全部游戏通过免费的网盘下载,免费xci,nsp,nsz,ns格式游戏下载,建议悄悄收藏。
juzixiazai[.]com https://t.co/eDJaMB2ISA](https://pbs.twimg.com/media/Gn7ZnE7aEAAVo-l.jpg)





















