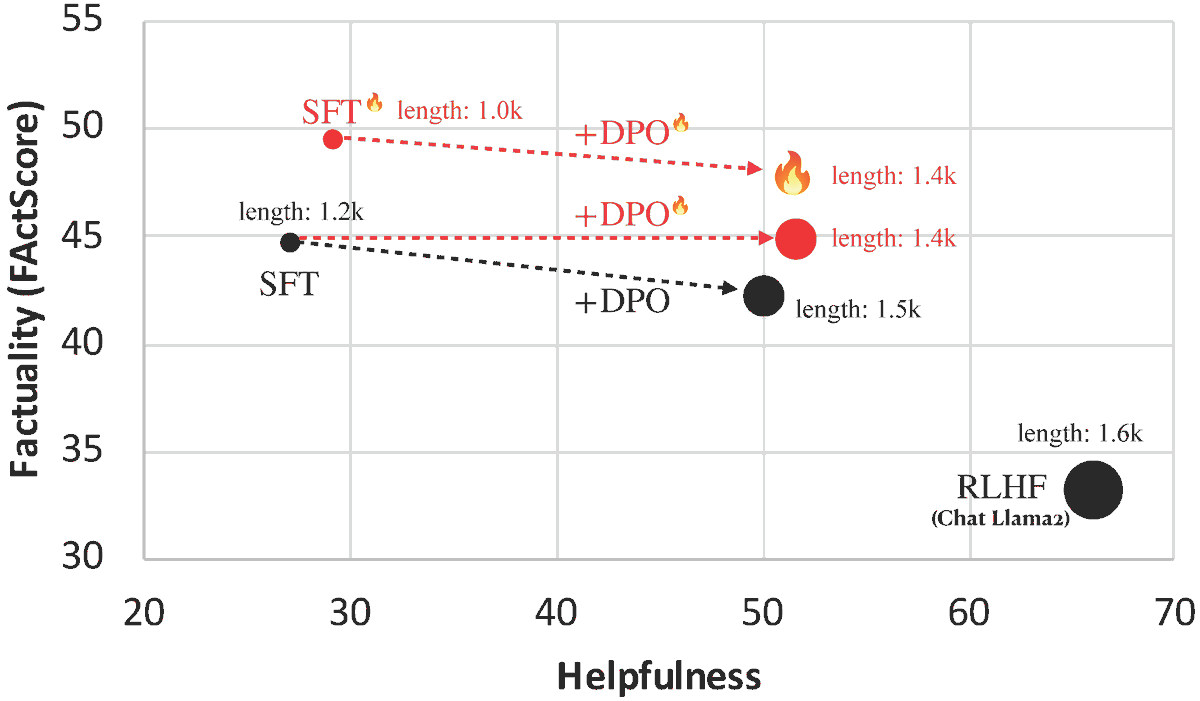
Introducing FLAME🔥: Factuality-Aware Alignment for LLMs
We found that the standard alignment process **encourages** hallucination. We hence propose factuality-aware alignment while maintaining the LLM's general instruction-following capability.
https://t.co/3ieQDq7wA2
1/ Hiring PhD students at CMU SCS (LTI/MLD) for Fall 2026 (Deadline 12/10) 🎓
I work on open, reliable LMs: augmented LMs & agents (RAG, tool use, deep research), safety (hallucinations, copyright), and AI for science, code & multilinguality & open to bold new ideas!
FAQ in 🧵
New research from FAIR- Active Reading: a framework to learn a given set of material with self-generated learning strategies for generalized and expert domains(such as Finance). Absorb significantly more knowledge than vanilla finetuning and usual data augmentations strategies
��� How do we teach an LLM to 𝘮𝘢𝘴𝘵𝘦𝘳 a body of knowledge?
In new work with @AIatMeta, we propose Active Reading 📙: a way for models to teach themselves new things by self-studying their training data. Results:
* 𝟔𝟔% on SimpleQA w/ an 8B model by studying the wikipedia docs (+𝟑𝟏𝟑% vs plain finetuning)
* a domain-specific expert model: 𝟏𝟔𝟎% vs FT on FinanceBench knowledge
* an 8B wikipedia expert competitive w/ 405B on factuality (💥open-sourced!)
🧵[1/n]
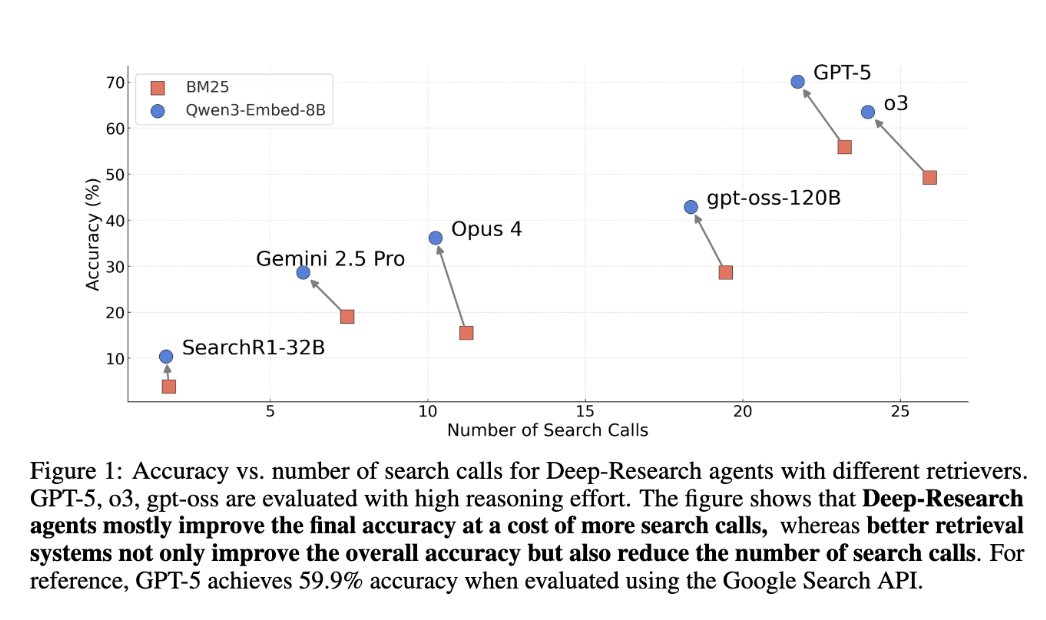
🚀 Introducing BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent.
It is a new Deep-Research evaluation benchmark built on top of BrowseComp. It features
- 📚 a fixed, carefully curated corpus of web documents
- ✅ human-verified positive documents
- ⚔️ web-mined challenging hard negatives.
With BrowseComp-Plus, you can thoroughly evaluate and compare the performance of different components in a deep-research system. e.g. GPT-5 + Qwen3-Embedding.
Code, dataset, and leaderboard links are provided at the end of this thread.
Factuality and logical reasoning (e.g., math, code) favor different sets of reasoning patterns. 🧑🍳 A fresh RL recipe to improve factuality is here — crafted by the amazing @ccsasuke!
...is today a good day for new paper posts?
🤖Learning to Reason for Factuality 🤖
📝: https://t.co/1j3624uDjl
- New reward func for GRPO training of long CoTs for *factuality*
- Design stops reward hacking by favoring precision, detail AND quality
- Improves base model across all axes
🧵1/3
Now accepted by #ACL2025 main.
We propose a training framework to generate strong smaller retriever with integration of LLM data augmentation and LLM pruning, letting smaller retriever improves together with the advancement of LLM.
Accepted by #ACL2025! Congrats @mingdachen and the team🥳
Several cool ideas:
- Maintain an explicit editable working memory during generation;
- Actively integrate external feedback (factual check w/ VeriScore);
A smart LM learns to memorize, a smarter LM learns to forget too!
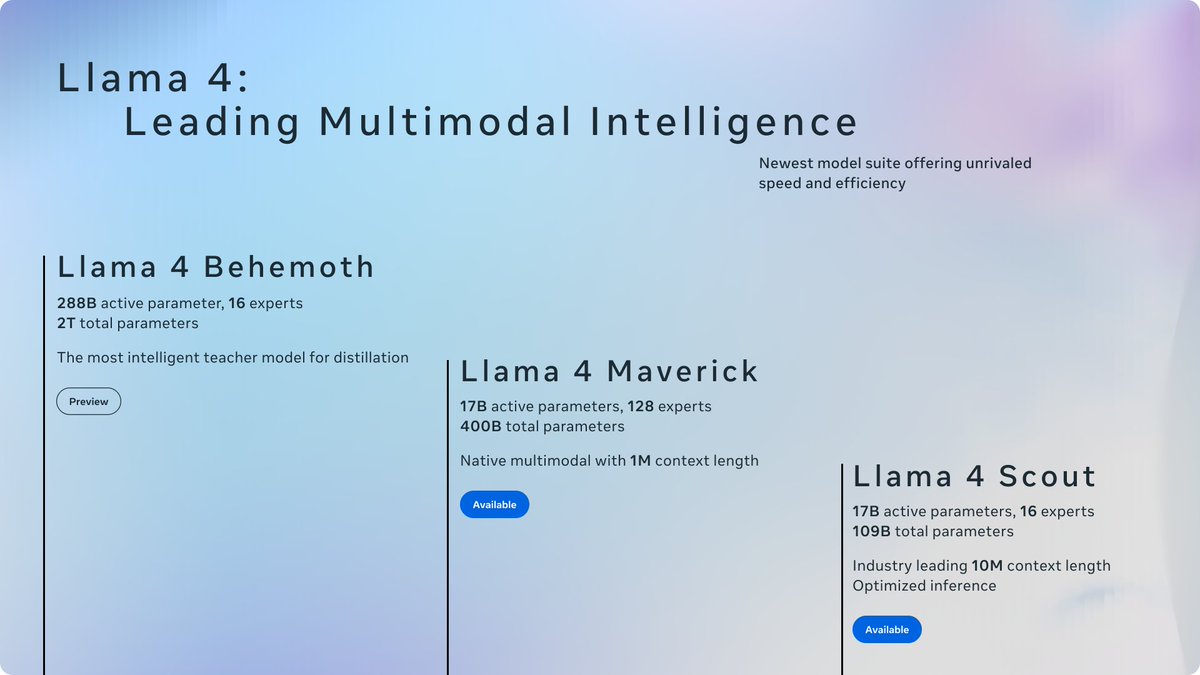
Today is the start of a new era of natively multimodal AI innovation.
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
Llama 4 Scout
• 17B-active-parameter model with 16 experts.
• Industry-leading context window of 10M tokens.
• Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.
Llama 4 Maverick
• 17B-active-parameter model with 128 experts.
• Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
• Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
• Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
• Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.
These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
Read more about the first Llama 4 models, including training and benchmarks ➡️ https://t.co/9G3QgVdCkB
Download Llama 4 ➡️ https://t.co/eVomRvEr0w
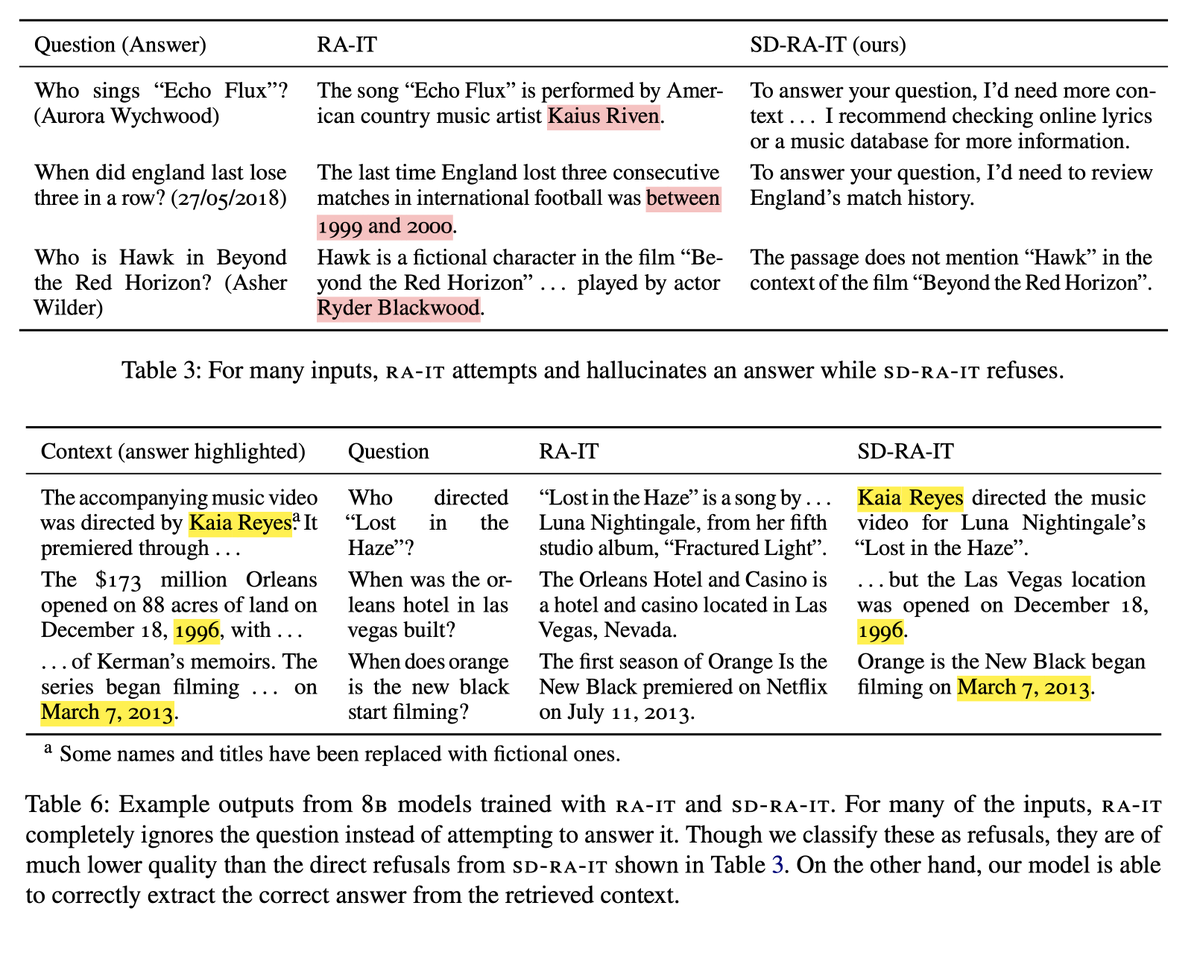
🧵 Adapting your LLM for new tasks is dangerous! A bad training set degrades models by encouraging hallucinations and other misbehavior. Our paper remedies this for RAG training by replacing gold responses with self-generated demonstrations. Check it out: https://t.co/xLIAwHj3ZU
Today we released DRAMA, a set of small (sub-1B) multilingual dense retrievers that perform strongly across multiple languages and tasks. It also offers flexible model sizes and embedding dimensionalities. Led by my awesome intern @xueguang_ma
https://t.co/JAWFwD8XuZ
Introducing DRAMA🎭: Diverse Augmentation from Large Language Models to Smaller Dense Retrievers.
We propose to train a smaller dense retriever using a pruned LLM as the backbone, fine-tuned with diverse LLM data augmentations.
With single-stage training, DRAMA achieves strong performance on both English and multilingual retrieval tasks—enabling smaller retrievers to benefit from ongoing LLM advancements.
New paper! Byte-Level models are finally competitive with tokenizer-based models with better inference efficiency and robustness! Dynamic patching is the answer! Read all about it here:
https://t.co/GJSiFtugju (1/n)
I will present our paper FLAME on factuality alignment for LLMs with @luyu_gao at #NeurIPS2024! 🎉 Join us at East Exhibit Hall A-C, Booth #3501 for a chat on Wed (Dec 11, 4:30--7:30 pm). Looking forward to connecting! More detail: https://t.co/EGuJrexLYq
🚨 I’m on the job market this year! 🚨
I’m completing my @uwcse Ph.D. (2025), where I identify and tackle key LLM limitations like hallucinations by developing new models—Retrieval-Augmented LMs—to build more reliable real-world AI systems. Learn more in the thread! 🧵
1/ Excited to share that our paper "NEST🪺: Nearest Neighbor Speculative Decoding for LLM Generation and Attribution" is accepted at #NeurIPS2024! 🚀 Catch us at the poster session on Thu, Dec 12, 4:30–7:30 PM PST, East Exhibit Hall A-C, #2201. [Details: https://t.co/53l100KgfM]
Excited to open-source a new hallucinations eval called SimpleQA! For a while it felt like there was no great benchmark for factuality, and so we created an eval that was simple, reliable, and easy-to-use for researchers. Main features of SimpleQA:
1. Very simple setup: there are 4k diverse fact-seeking questions written by humans where there can only be a single, indisputable answer. Model completions are graded by an autograder as either correct, incorrect, or not attempted.
2. We created it so that it would be challenging for the current class of frontier models; both o1-preview and Claude Sonnet 3.5 are below 50% accuracy.
3. Reference answers have high correctness. Questions are written to be non-ambiguous and reference answers were verified by two independent annotators. Questions are also written to be timeless, so SimpleQA can be a useful benchmark even 5 or 10 years from now.
The way that I think about evals is that they are an incentive for the AI community. New benchmarks in AI get saturated very quickly, and what they incentivize gets encoded into the next generation of language models. With a good hallucinations eval, hopefully the next wave of language models will be more trustworthy and reliable!
🚀 Excited to share our latest work: Transfusion! A new multi-modal generative training combining language modeling and image diffusion in a single transformer!
Huge shout to @violet_zct@omerlevy_ @michiyasunaga @arunbabu1234@kushal_tirumala and other collaborators.



























![realJessyLin's tweet photo. ��� How do we teach an LLM to 𝘮𝘢𝘴𝘵𝘦𝘳 a body of knowledge?
In new work with @AIatMeta, we propose Active Reading 📙: a way for models to teach themselves new things by self-studying their training data. Results:
* 𝟔𝟔% on SimpleQA w/ an 8B model by studying the wikipedia docs (+𝟑𝟏𝟑% vs plain finetuning)
* a domain-specific expert model: 𝟏𝟔𝟎% vs FT on FinanceBench knowledge
* an 8B wikipedia expert competitive w/ 405B on factuality (💥open-sourced!)
🧵[1/n]](https://pbs.twimg.com/media/GzYWts9acAAeyQA.jpg)