Thank you to everyone in the community who is testing and using Nemotron models. It's great to see Nemotron-Cascade-2, Nemotron-3-Super and Nemotron-3-Nano trending on HF.
The Nemotron team is working hard to incorporate all your feedback into Nemotron 4.
And yes, Nemotron 3 Ultra is still on track for release.
https://t.co/lkEwmlUng9
NVIDIA just released Nemotron-Cascade 2 on Hugging Face
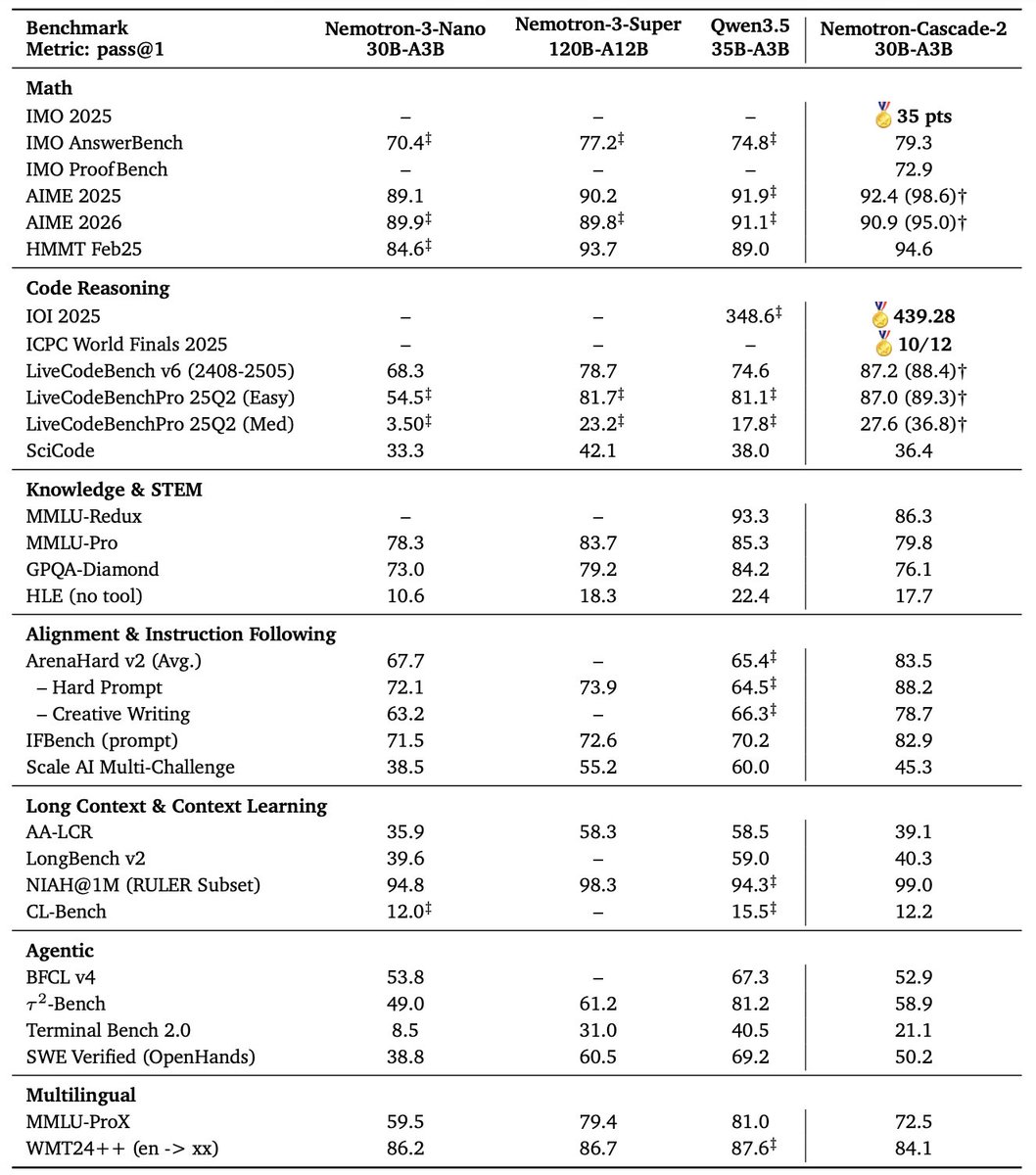
A 30B MoE model with 3B activated parameters that achieves gold medal performance at IMO and IOI 2025.
🚀 Introducing Nemotron-Cascade 2 🚀
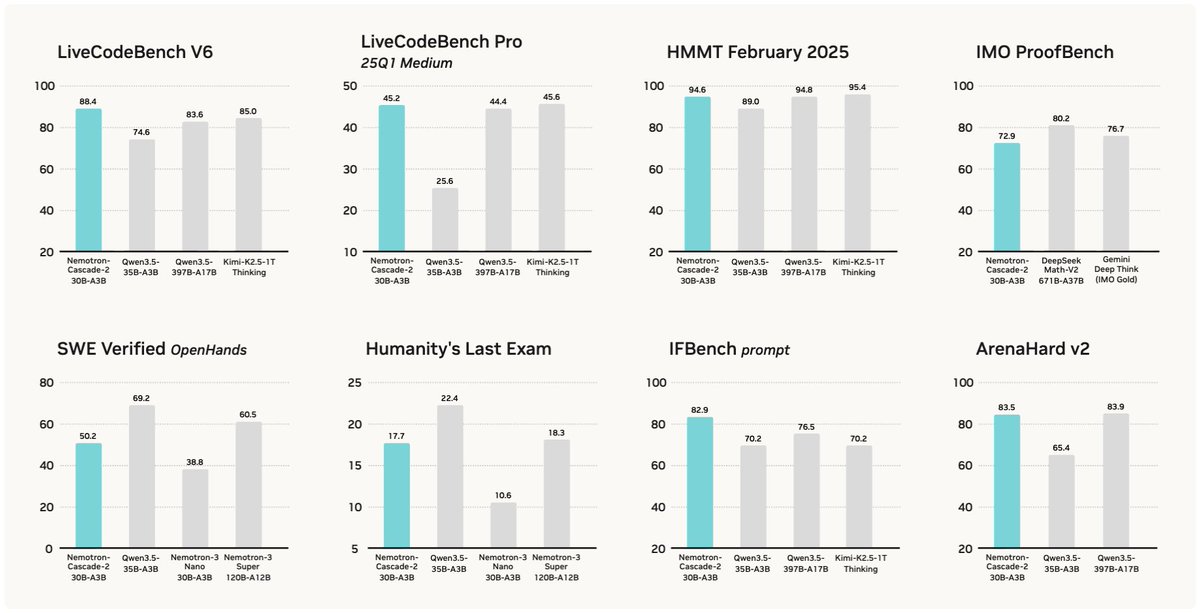
Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities.
🥇 Gold Medal-level performance on IMO 2025, IOI 2025, and ICPC World Finals 2025:
• Capabilities once thought achievable only by frontier proprietary models (e.g. Gemini Deep Think) or frontier-scale open models (i.e. DeepSeek-V3.2-Speciale-671B-A37B).
• Remarkably high intelligence density with 20× fewer parameters.
🏆 Best-in-class across math, code reasoning, alignment, and instruction following:
• Outperforms the latest Qwen3.5-35B-A3B (2026-02-24) and even larger Qwen3.5-122B-A10B (2026-03-11).
🧠 Powered by Cascade RL + multi-domain on-policy distillation:
• Significantly expand Cascade RL across a much broader range of reasoning and agentic domains than Nemotron-Cascade 1, while distilling from the strongest intermediate teacher models throughout training to recover regressions and sustain gains.
🤗 Model + SFT + RL data:
👉 https://t.co/4QJqfTOt6I
📄 Technical report:
👉 https://t.co/dFC00m6RZU
Super proud to introduce my first work at NVIDIA!! Nemotron-Cascade, our RL scaling efforts to build fully open-source general-purpose reasoning models that achieve SoTA performance on math, coding, and SWE.
I am extremely honored to join this small but closely-connected team led by the wonderful @_weiping!
Check out the first comprehensive study on cascade RL to build general-purpose reasoning models. We also release the training data and the strong 8B 14B General-purpose reasoning models.
🚀 Introducing Nemotron-Cascade! 🚀
We’re thrilled to release Nemotron-Cascade, a family of general-purpose reasoning models trained with cascaded, domain-wise reinforcement learning (Cascade RL), delivering best-in-class performance across a wide range of benchmarks.
💻 Coding powerhouse
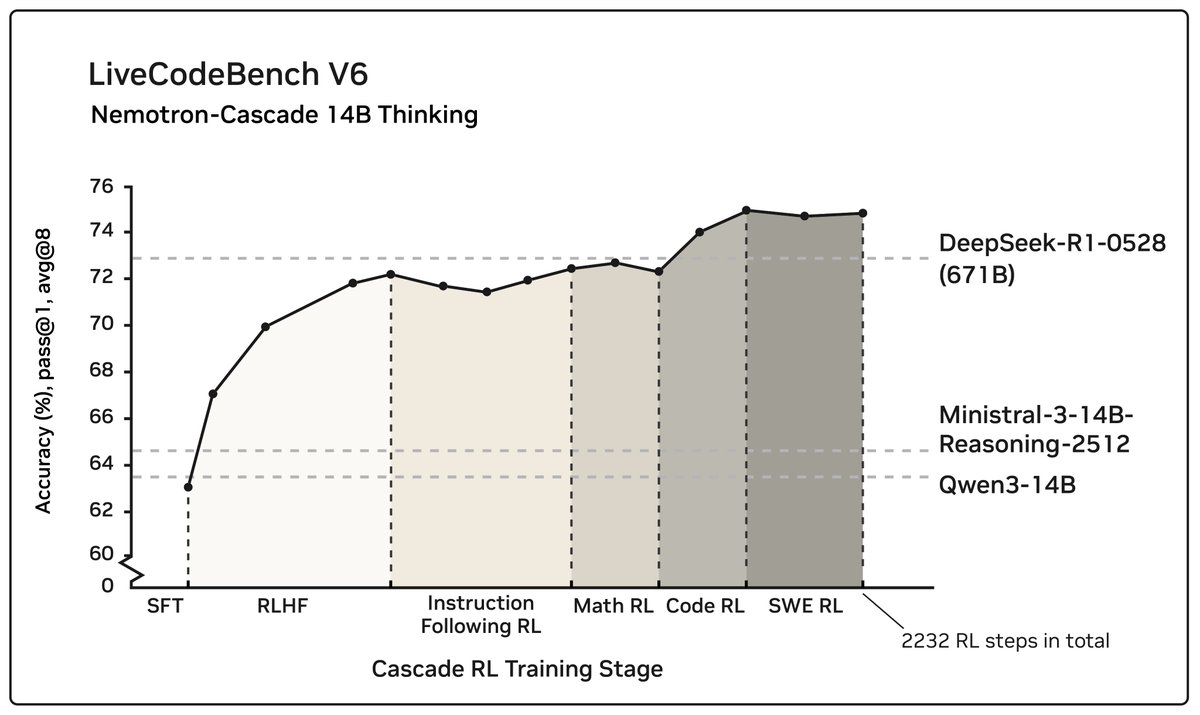
After RL, our 14B model:
• Surpasses DeepSeek-R1-0528 (671B) on LiveCodeBench v5/v6/Pro.
• Achieves silver-medal performance at IOI 2025 🥈.
• Reaches a 43.1% pass@1 on SWE-Bench Verified, and 53.8% with test-time scaling.
🧠 What is Cascade RL?
Instead of mixing heterogeneous prompts across domains, Cascade RL trains sequentially, domain by domain, which reduces engineering complexity, mitigates heterogeneous verification latencies, and enables domain-specific curricula and tailored hyperparameter tuning.
✨ Key insight
Using RLHF for alignment as a pre-step dramatically boosts complex reasoning—far beyond preference optimization. Subsequent domain-wise RLVR stages rarely hurt the benchmark performance attained in earlier domains and may even improve it, as illustrated in the following figure.
🤗 Models & training data 🔥
👉 https://t.co/wfVcAaMocA
📄 Technical report with detailed training and data recipes
👉 https://t.co/FdMINvB4yM
@yupp_ai@UWaterloo Today marks the beginning of this journey for me, and I’m happy to share more details in the coming months! Until then, I hope you’ll try out https://t.co/61cOJryF5O and share your feedback. (9/9)
Introducing DRAMA🎭: Diverse Augmentation from Large Language Models to Smaller Dense Retrievers.
We propose to train a smaller dense retriever using a pruned LLM as the backbone, fine-tuned with diverse LLM data augmentations.
With single-stage training, DRAMA achieves strong performance on both English and multilingual retrieval tasks—enabling smaller retrievers to benefit from ongoing LLM advancements.
In this work led by @ShengyaoZhuang , we explore various settings to attack recent document screenshot retrievers like DSE and ColPali.
🚨What you see might not be what you searched for.
#NeurIPS2024 I will present "Nearest Neighbor Speculative Decoding for LLM Generation and Attribution" led by @alexlimh23 at the poster session today.
⏰ Thu Dec 12 at 4:30-7:30 PM PST
🏛️ East Exhibit Hall A-C, #2201
🔗 https://t.co/a3Zfuvhfib
Please drop by if you would like to chat about semi-parametric language modeling, beyond token-level decoding and generation attribution!
I will present our paper FLAME on factuality alignment for LLMs with @luyu_gao at #NeurIPS2024! 🎉 Join us at East Exhibit Hall A-C, Booth #3501 for a chat on Wed (Dec 11, 4:30--7:30 pm). Looking forward to connecting! More detail: https://t.co/EGuJrexLYq
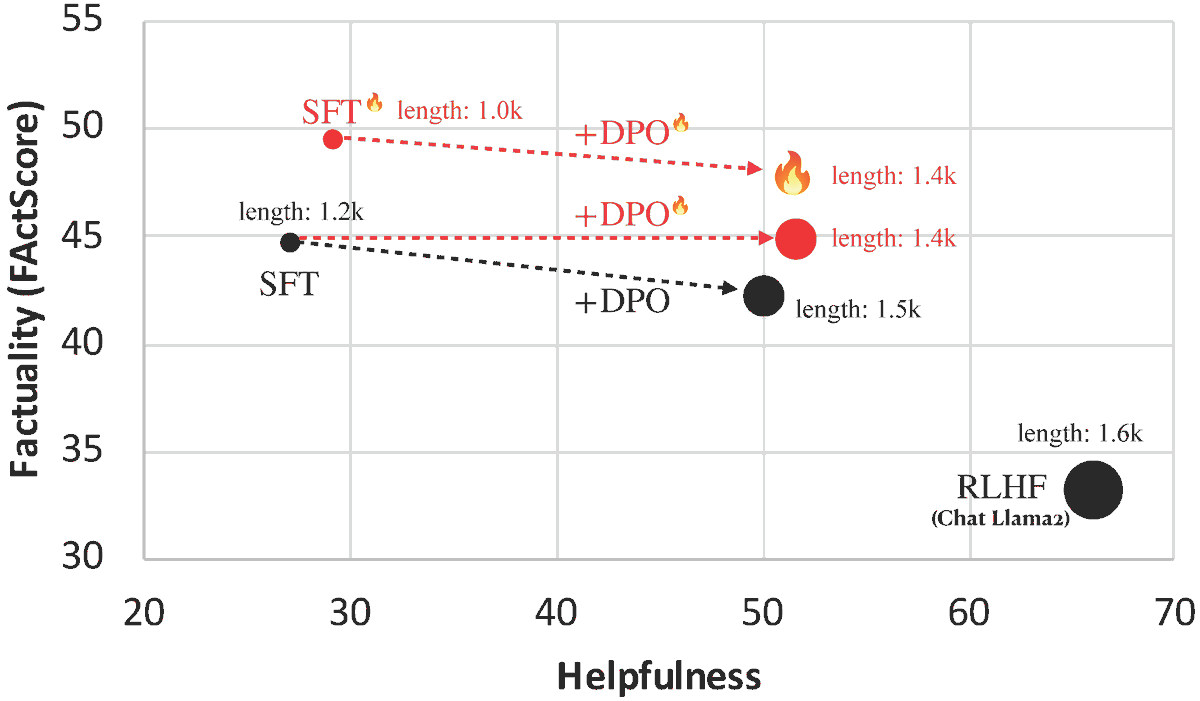
Introducing FLAME🔥: Factuality-Aware Alignment for LLMs
We found that the standard alignment process **encourages** hallucination. We hence propose factuality-aware alignment while maintaining the LLM's general instruction-following capability.
https://t.co/3ieQDq7wA2
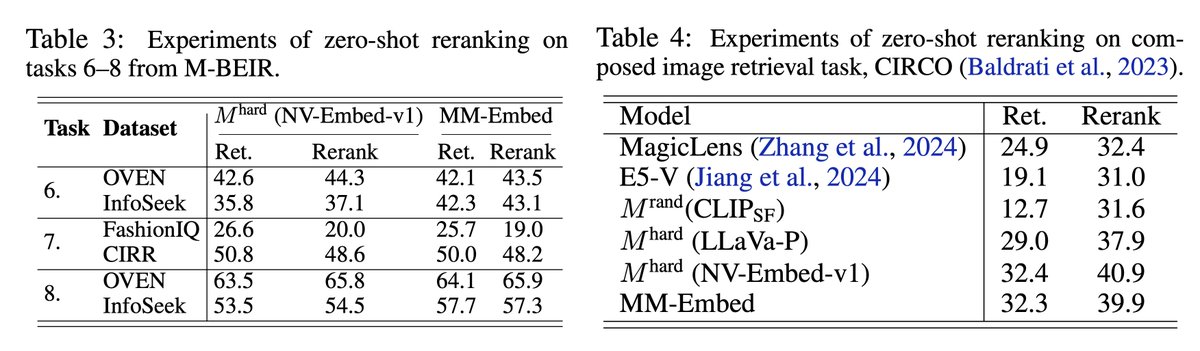
Crucial work in the field of multimodal embeddings! It’s impressive that multimodal embeddings are reaching SOTA-level performance comparable to text-only embeddings in the retrieval tasks.
Introducing MM-Embed, the first multimodal retriever achieving SOTA results on the multimodal M-BEIR benchmark and compelling results (among top-5 retrievers) on the text-only MTEB retrieval benchmark.
Paper: https://t.co/i4bSsDLlLA
🤗 Model: https://t.co/nSb6fFre08