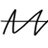This is the best site on the internet to learn harness engineering.
Free. Completely.
Most AI engineers have never heard the term.
https://t.co/bwDbTTYsjM
Bookmark this site.
Then read this setup ↓
As an AI Engineer. Please learn
>Harness engineering, not just prompt engineering
>Context engineering, not just long prompts
>Prompt caching vs. semantic caching tradeoffs
>KV cache management, eviction, reuse, and memory pressure at scale
>Prefill vs. decode latency and why they optimize differently
>Continuous batching, paged attention, and throughput optimization
>Speculative decoding vs. quantization vs. distillation tradeoffs
>INT8, INT4, FP8, AWQ, GPTQ, and when quantization hurts quality
>Structured output failures, schema validation, repair loops, and fallback chains
>Function calling reliability, tool contracts, argument validation, and idempotency
>Agent guardrails, loop budgets, tool budgets, and termination conditions
>Model routing, graceful fallback logic, and degraded-mode UX
>RAG architecture: chunking, embeddings, hybrid search, reranking, and freshness
>Retrieval evals: recall, precision, grounding, attribution, and citation quality
>Evals: golden sets, regression tests, adversarial tests, LLM-as-judge, and human evals
>LLM observability as a first-class discipline: traces, spans, tokens, latency, errors, and drift
>Cost attribution per feature, workflow, tenant, and user journey not just per model
>Safety engineering: prompt injection defense, data leakage prevention, and permission boundaries
>Multi-tenant isolation, cache safety, and cross-user context contamination prevention
>Fine-tuning vs. in-context learning vs. RAG vs. distillation and when each is the wrong tool
>Latency, quality, cost, and reliability tradeoffs across the full inference stack
>Production failure modes: hallucinated tool calls, malformed JSON, stale retrieval, runaway agents, and silent eval regressions
Ever wanted an AI that can watch videos and understand them like a human? Meet Marlin 2B, a multimodal model that processes video, text, and captions together. It's small, fast, and built for temporal grounding. Game changer for video AI.
Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
Trying some tweaks for the dual 3090 setup using Ornstein3.6-27B-MTP-NSC-ACE-SABER + MTP:
- Tensor parallelism enabled - nice boost in perf. but you lose the ability to quantize kv cache. Still deciding if worth the trade off.
- When running two prompts at once, it levels out to around 33 tokens/second each - not bad!
- Prefill - 1st time takes a bit, but after that, it's snappy on both slots
- FP16 kv cache @ 65k context = around 17 GB per card or 34 GB total VRAM usage.
Conclusion: If you only plan to serve a dense model, this is a very viable setup for a small business scenario with multiple users. I think I can safely fit Gemma-E4B or maybe even Qwen3.5-9B to handle multi-modal cases (still have 14 GB of headroom left)
--model /models/Ornstein3.6-27B-MTP-NSC-ACE-SABER-Q4_K_M-MTP.gguf \
--alias Ornstein3.6-27B-MTP-NSC-ACE-SABER \
--split-mode tensor
--n-gpu-layers 999 \
--ctx-size 65536 \
--parallel 2 \
--cache-type-k f16 \
--cache-type-v f16 \
--spec-type draft-mtp --spec-draft-p-min 0.0 --spec-draft-n-max 3 \
--spec-type ngram-mod --spec-ngram-mod-n-match 16 --spec-ngram-mod-n-min 24 --spec-ngram-mod-n-max 48 \
--spec-type ngram-map-k4v --spec-ngram-map-k4v-size-n 12 --spec-ngram-map-k4v-size-m 48 --spec-ngram-map-k4v-min-hits 1 \
--cont-batching \
--jinja \
--flash-attn on \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--presence-penalty 1.5 \
--min-p 0.00 \
--no-mmap \
--reasoning on --chat-template-kwargs '{"preserve_thinking": true}'
Overall: you get Sonnet 4.6 level at home and can be used by multiple people - MTP + ngram-mod + ngram-map makes this possible!
How To Secure A Linux Server is an evolving guide that teaches server security fundamentals while walking through practical hardening steps.
- SSH hardening with key-based auth and 2FA/MFA
- Firewall setup using UFW and intrusion detection with PSAD and Fail2Ban
- File integrity monitoring with AIDE and rootkit detection with Rkhunter and chrootkit
- Automatic security updates and audit logging with Lynis and OSSEC
Quick Linux Tip #3
Need to see which ports are open and which process owns each one?
Use:
$ ss -tlnp
It lists all TCP listening ports with the process name and PID attached.
Faster than netstat, built into every modern Linux system, and no package to install.
Run this before opening a firewall port, and you'll know instantly if the service is actually bound and listening or just supposed to be.
Follow @tecmint for more #Linux tips
nvidia-smi on my headless Linux server for the first time.
RTX 5090, 32GB VRAM, CUDA 13.2, Ubuntu 26.04.
SSH from my macbook.
5W idle, 34°C, fan-stop mode. waiting for its first model.
the 8GB era is over.
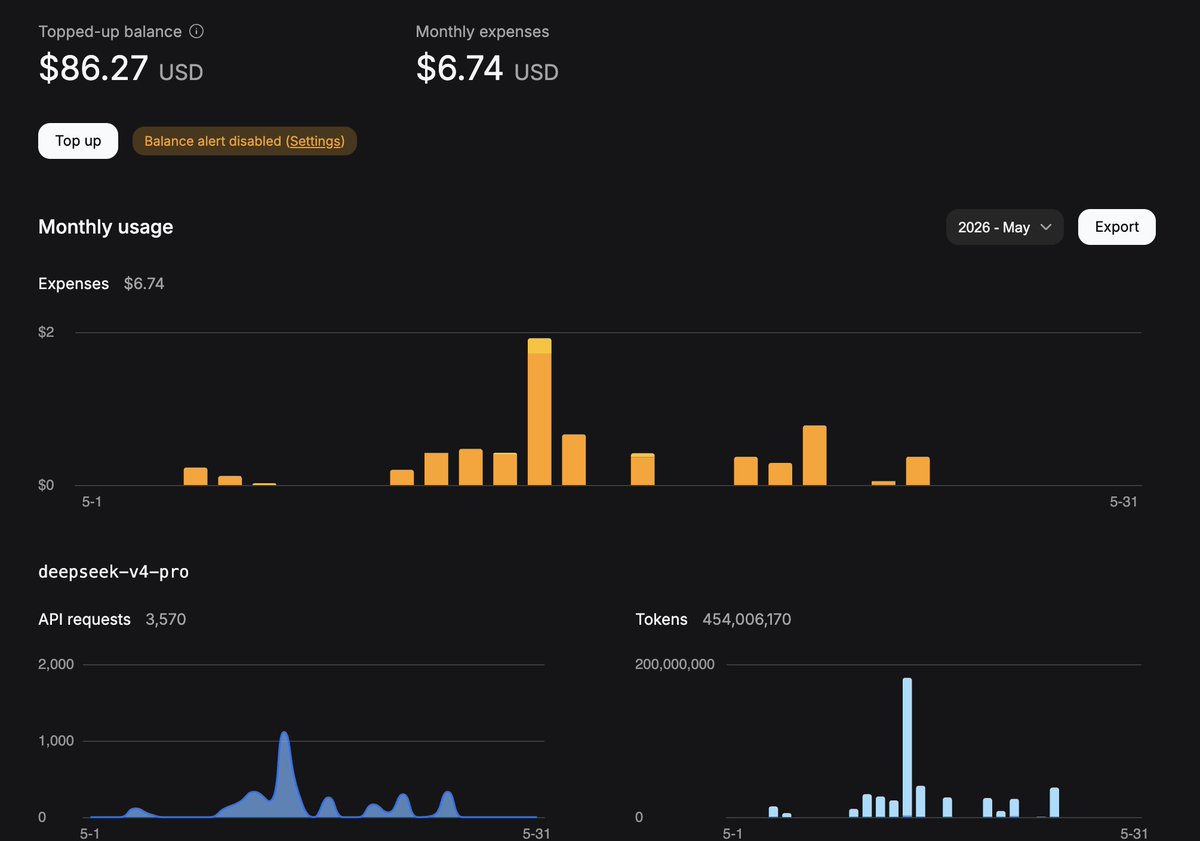
Meet the new financial QA powerhouse: convfinqa-qwen3.5-4b. It's a text generation model fine-tuned to answer complex financial questions with precision. Perfect for analysts, traders, or anyone who needs quick, reliable answers from financial data.
It’s very simple
Find a 3090 or two
Get any mobo that supports 2 pcie x16 ports (at least x16x4 for lanes)
Get a 1200W+ PSU
Buy the cheapest ddr4 ram 64gb+ (you’re not using it anyways)
Install Linux, vLLM, Llama.cpp, SGlang, tailscale
Download any flavour of qwen 3.7 27b
You are now localmaxxing
A massive 20B parameter model just dropped on Hugging Face, and it's already getting tons of love. This is a text generation powerhouse built for conversational AI and more. Check the tags, it's ready for production with vLLM support.
Meet Qwen3.5-4B, a powerful image-text-to-text model that can understand both images and text. It's perfect for building smarter chatbots and assistants.
Meet MobileNetV3 Small, a super efficient image classifier that packs a punch. It can recognize 1000 different objects from photos, and it's been downloaded over 12 million times. This tiny model is a big deal for AI on the go.
Ever wished ComfyUI could auto-install everything for you? This model is an asset pack that simplifies setup for Flux, Wan, Qwen, HiDream, and more. It bundles diffusers, ONNX, safetensors, and GGUF formats. A must have for AI artists who hate manual configs.
BERT is the AI that changed everything. This model, trained on Wikipedia and BookCorpus, understands language like no other. It's the foundation for countless NLP breakthroughs, and it's still one of the most downloaded models ever. 70 million downloads and counting.