Unpopular opinion: If your process is even semi-predictable and runs in a loop, you're probably burning money on tokens and don't need an agent 🔥💵🔥
Use AI to build a good old-fashioned program that handles the workflow and only calls an agent as a fallback🤖
Thank me later😉
I'm pretty sure the only reason to use Kafka for telemetry data in 2026 is muscle memory.
A simple, open source, S3-backed pipeline can shuttle 1Gb/s of logs to @ClickHouseDB for $200/mo with 2.8s p50 latency. Fast enough for us.
https://t.co/E3Zv25TIqS
the default "puff into {nvme, dram}" works well for most use-cases, but in cases of high, sustained QPS—coupling compute and storage is best
this is what we mean by "compute-storage flexible"
Don't know how I got this far in my career without realizing that us-east-1a/b/c are just random identifiers and 1a for one account might be 1c for another
Until now, LiveVue supported only two SSR modes:
➡️ Vitejs-based (for development)
➡️ Nodejs (for production)
Now I'm introducting a third one:
✅ QuickBeam
It's running QuickJS as NIF, which is more performant. Now a default mode!
Thanks @dan_note for contribution!
Reach can now trace data flow from Elixir through QuickBEAM's JS runtime and back. One program dependence graph across two languages and two runtimes.
Also: dead code detection now produces near-zero false positives across 5 real codebases.
The line between frontend and backend is getting thinner. More coming soon.
https://t.co/0eHb5ngVuD
This is my first big Elixir project. I reached for it because I needed to manage the state of a lot of docker compose clusters to run the dev servers and docker containers to run agents.
The supervisor tree was crucial to getting it working.
Reach 1.5.0 — effect classification accuracy went from 11% to 89%.
The analyzer couldn't tell 𝚁𝚎𝚙𝚘.𝚒𝚗𝚜𝚎𝚛𝚝!() from 𝙴𝚗𝚞𝚖.𝚖𝚊𝚙(). Now it can.
What changed:
— Alias/import resolution. 𝚊𝚕𝚒𝚊𝚜 𝙵𝚘𝚘.𝙱𝚊𝚛 then 𝙱𝚊𝚛.𝚌𝚊𝚕𝚕() was invisible to coupling analysis. Multi-alias 𝚊𝚕𝚒𝚊𝚜 𝙵𝚘𝚘.{𝙰, 𝙱} and 𝚒𝚖𝚙𝚘𝚛𝚝 too
— Cross-module effect inference. Pure functions recognized transitively across modules
— Plugin 𝚌𝚕𝚊𝚜𝚜𝚒𝚏𝚢_𝚎𝚏𝚏𝚎𝚌𝚝/𝟷 callback for all 8 built-in plugins. 𝚁𝚎𝚙𝚘.𝚊𝚕𝚕 → read, 𝚁𝚎𝚙𝚘.𝚒𝚗𝚜𝚎𝚛𝚝! → write, 𝚊𝚜𝚜𝚒𝚐𝚗 → pure
— On Elixir 1.19+ reads compiler-inferred types from ExCk BEAM chunk
7 new commands: 𝚌𝚘𝚞𝚙𝚕𝚒𝚗𝚐, 𝚑𝚘𝚝𝚜𝚙𝚘𝚝𝚜, 𝚍𝚎𝚙𝚝𝚑, 𝚎𝚏𝚏𝚎𝚌𝚝𝚜, 𝚋𝚘𝚞𝚗𝚍𝚊𝚛𝚒𝚎𝚜, 𝚡𝚛𝚎𝚏, 𝚌𝚘𝚗𝚌𝚞𝚛𝚛𝚎𝚗𝚌𝚢. All take a path filter: 𝚖𝚒𝚡 𝚛𝚎𝚊𝚌𝚑.𝚑𝚘𝚝𝚜𝚙𝚘𝚝𝚜 𝚕𝚒𝚋/𝚖𝚢_𝚊𝚙𝚙/
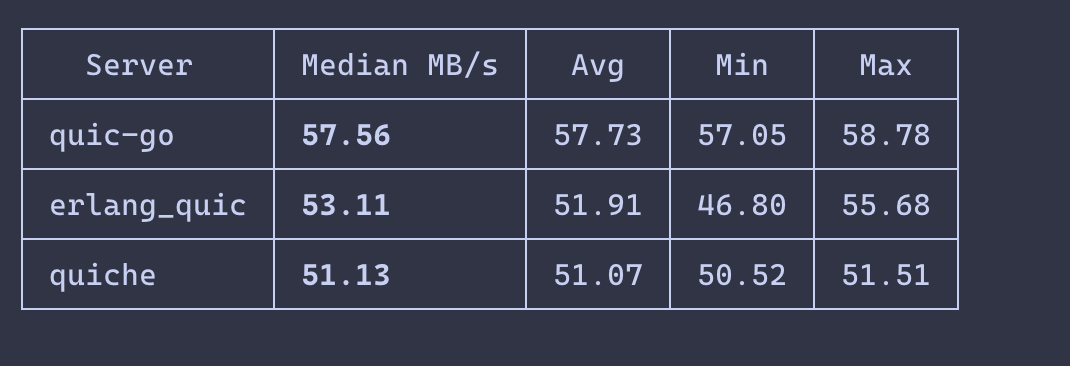
Tested on 7 real codebases (up to 817 files). Zero crashes, 30% faster.
https://t.co/bULkiIZP7H
PgQue v0.1.0 is out.
PgQ -- the Postgres queue system built at Skype 20 years ago for 1B-user-scale workloads -- repackaged for the managed-Postgres era. One SQL file. No C extension. No external daemon. pg_cron to tick.
Why bother reviving a 2007 architecture?
Every major Postgres queue in production today uses some flavor of SKIP LOCKED + UPDATE/DELETE. It works under light load. When you have more data and higher load, it degrades predictably. Then you get posts like these:
- Brandur at Heroku, 2015: 60k job backlog in one hour from a single open transaction
- PlanetScale, 2026: death spiral at 800 jobs/sec
- River issue #59, awa issue #169 and so on, Oban's partitioning work, PGMQ's autovacuum tuning guide and duct-taping with pg_partman
The core issue is how Postgres MVCC is implemented and how we deal with it. Dead tuples in the hot path, xmin horizon pinned, vacuum falling behind, query performance quickly degrades. This happens every time you run pg_dump, execute an analytical query, or have a lagging/unused logical replication slot.
PgQ solved this in 2007 with snapshot-based batching and TRUNCATE rotation -- zero dead tuples in the event
path, by design.
But PgQ needed a C extension and an external daemon. Which means it doesn't run on RDS, Aurora, Cloud SQL, AlloyDB, Supabase, or Neon -- i.e., where most
Postgres lives now.
PgQue closes that gap.
💎 Pure SQL + PL/pgSQL (PgQ engine)
👩💻 \i sql/pgque.sql -- you're done
🕑 pg_cron replaces pgqd (optional, recommended)
💻 Python, Go, TypeScript client examples shipped
💙 Apache 2.0
Trade-off: end-to-end event delivery latency is up to a second, it depends on ticking frequency. If you need sub-3ms job dispatch, use River, Oban, or graphile-worker (and avoid anything that blocks xmin horizon). If you need high-throughput event streaming with fan-out inside Postgres -- Kafka-shaped, without Kafka and dealing with transactional outbox implementation -- this is the right shape of tool.
Kudos to Marko Kreen and Skype engineers who implemented this decades ago, for the original PgQ, and to Alexander Kukushkin whose recent "Rediscovering PgQ" talk brought this quiet corner of the Postgres ecosystem back into view.
Stars, issues, PRs, and honest criticism all welcome.
Link 👇