@Hikari_07_jp I am impressed with it so far. Q5 tested well. I have some results posted on my profile.
Going to mess around with Q6 and see if I can still have room for larger context but at even 8k it was almost hittimg my vram cap.
@googlegemma Thank you Google Deepmind for constantly releasing open models! 🌟
We made Dynamic GGUFs so you can run Gemma 4 12B more efficiently: https://t.co/8cL321pVDh
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
Been stress-testing Gemma 4 12B UD-Q5_K_XL on an RTX 5070 12GB.
~60 tok/s generation.
Up to ~49k context tested.
Under 10GB VRAM.
12GB GPUs are becoming a lot more capable for local AI than most people realize.
@stableAPY Never tested context on q6 only because at 8k i thought maybe id run out of vram. but might have to give it another test once im done with q5
@stableAPY everything at 8k. but i just dove back in and started testing larger context windows.
just started testing above 32k with a long prompt. ill be sure to post about testings once done. i am impressed so far tho
Tested Gemma 4 12B on an RTX 5070 12GB today.
The surprise wasn't the speed.
It was how usable the model feels while still fitting comfortably in VRAM.
UD-Q5_K_XL is the sweet spot so far.
Anyone else running Gemma 4 locally?
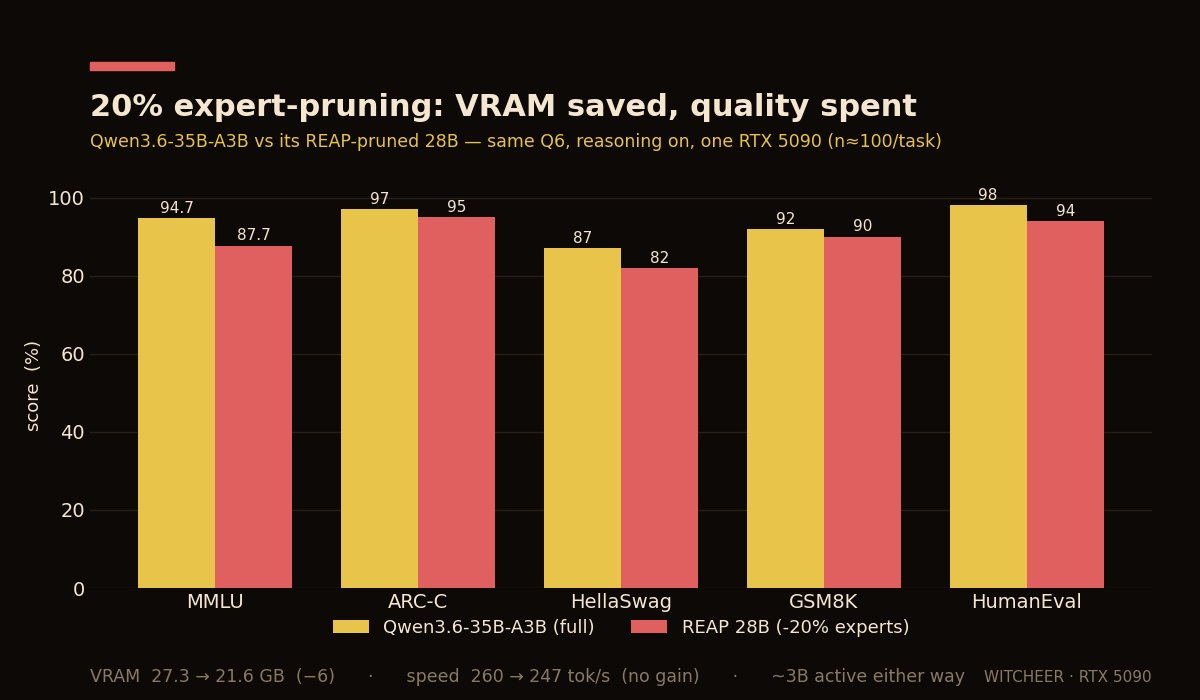
"Expert-pruning shrinks the model, so it must run faster."
I tested that and it doesn't.
REAP takes Qwen3.6-35B-A3B and prunes 20% of its experts down to 28B.
I ran it head-to-head against the unpruned parent.
~~~
what pruning actually changed:
- VRAM: 27.3 to 21.6 GB. a real ~6GB win.
- speed: 260 to 247 tok/s. no gain - slightly slower, even.
- quality: behind on all five (MMLU 94.7 to 87.7, HumanEval 98 to 94, HellaSwag 87 to 82, GSM8K 92 to 90, ARC 97 to 95).
~~~
REAP prunes whole experts, that cuts total params, but the active path per token is still ~3B either way. generation speed tracks active params and memory bandwidth, not total size.
you free VRAM, not time.
~~~
so expert-pruning here is a VRAM play, not a speed play.
it is worth it if you're memory-bound and need the headroom. not worth it if you're chasing tokens-per-second.
(n ~100 per task, so treat each gap as modest - but the parent won every single one.)
Results: Qwen2.5-3B quanted cleanly. Q4_K_M led generation at ~239 tok/s, IQ4_XS was close at ~232 tok/s and smallest at 1.63GiB, Q5_K_M hit ~215 tok/s, Q8_0 was the quality/reference quant at ~158 tok/s. Safety tests showed system prompts matter.
Built a local quant lab: HF download → F16 GGUF conversion → Q8/Q6/Q5/Q4/IQ quants → llama.cpp benchmarks → smoke tests with a conservative ops system prompt + safety leakage scanner. First baseline: Qwen2.5-3B on RTX 5070.
Grifters shipping vibe-coded slop are everywhere now and it is getting exhausting ngl
The issue is not that they are vibe coding
- Build however you want
- Use whatever tools you want
- Ship fast, experiment, have fun
The issue is pretending the output is serious software when it belongs in the trashbin
A lot of these people are not building products
- They are producing screenshots
- GitHub activity
- Fake momentum
And naturally, these are the same folks walking around proudly showing their GitHub commit count as if “many tiny commits to a broken app” is a proxy for taste, architecture, reliability, or competence
Very happy for them though: The graph is green, the software is not
learning more and more about local llms, how they work and exactly what all the different bits and pieces are really is a lot of fun.
its crazy to see where the tech has come in only 5 years. I remember using DeepDaze to make trippy ass pictures back then on my 2060super.